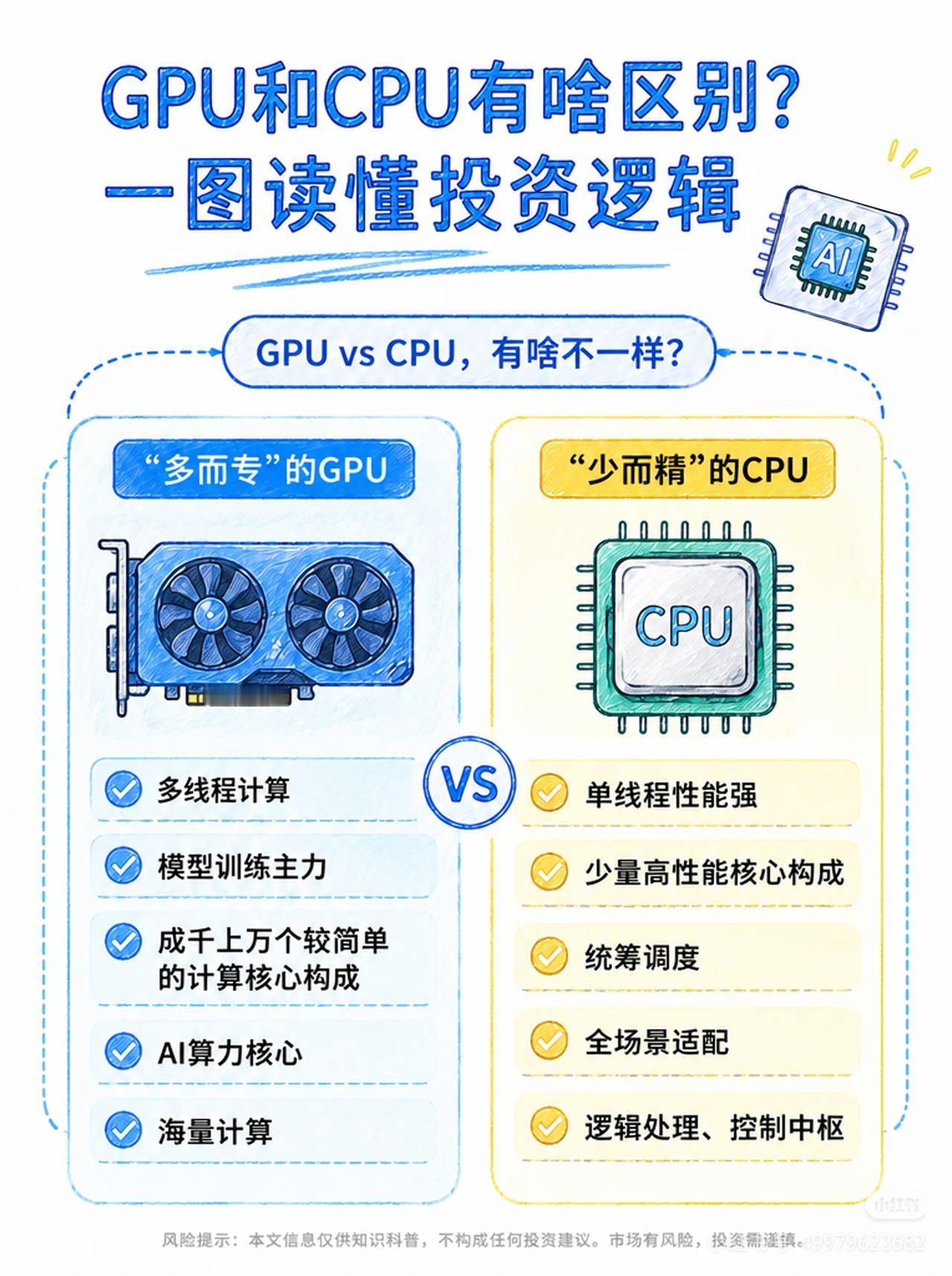
AI大模型厂商正在抠算力智谱新架构不加GPU算力提升15%【不加一块GPU,多榨出15%算力:大模型圈开始对网络“动刀”】《科创板日报》5月22日讯,近日,智谱首次公开了一项在生产集群中验证过的架构创新——ZCube组网架构。其中一组数据是:GPU一张没加,服务器一台没换,连应用代码都一行没动,集群推理吞吐直接提升了15%,TTFT(首Token响应时间)P99尾延迟下降了40.6%。这些数字是在真实生产流量中跑出来的,不是实验室的仿真推演。
对一家服务上百万开发者的大模型API平台来说,这意味着同一套硬件基础设施,每秒能多扛15%的并发请求,流量洪峰下的排队等待时间大幅缩短。而P99尾延迟的40%降幅,直接决定了终端用户感知到的“卡顿感”能减少多少。
更让行业内部关注的,是成本结构的变化。据智谱披露,ZCube架构所需的交换机和光模块数量比原有方案少了三分之一。规模越大,这笔节省的绝对值就越可观。在推理需求持续高增长、算力供给整体偏紧的市场里,这种“不动硬件、只动组网”的效率挖潜,等于是对存量算力资产进行了一次极低成本效率重估。 不加一块GPU,多榨出15%算力:大模型圈开始对网络“动刀”