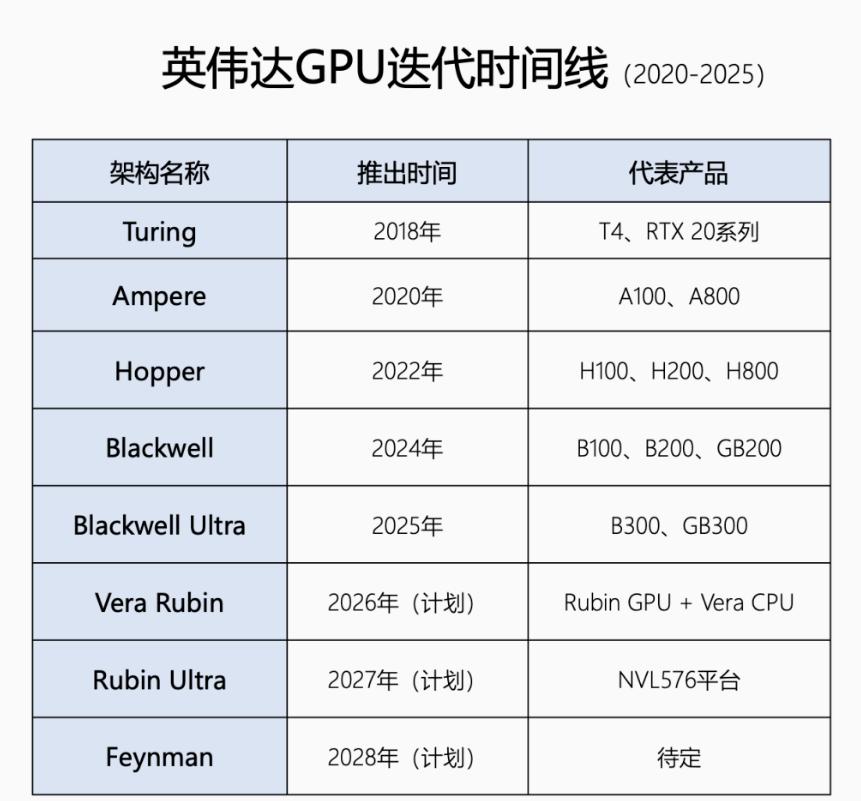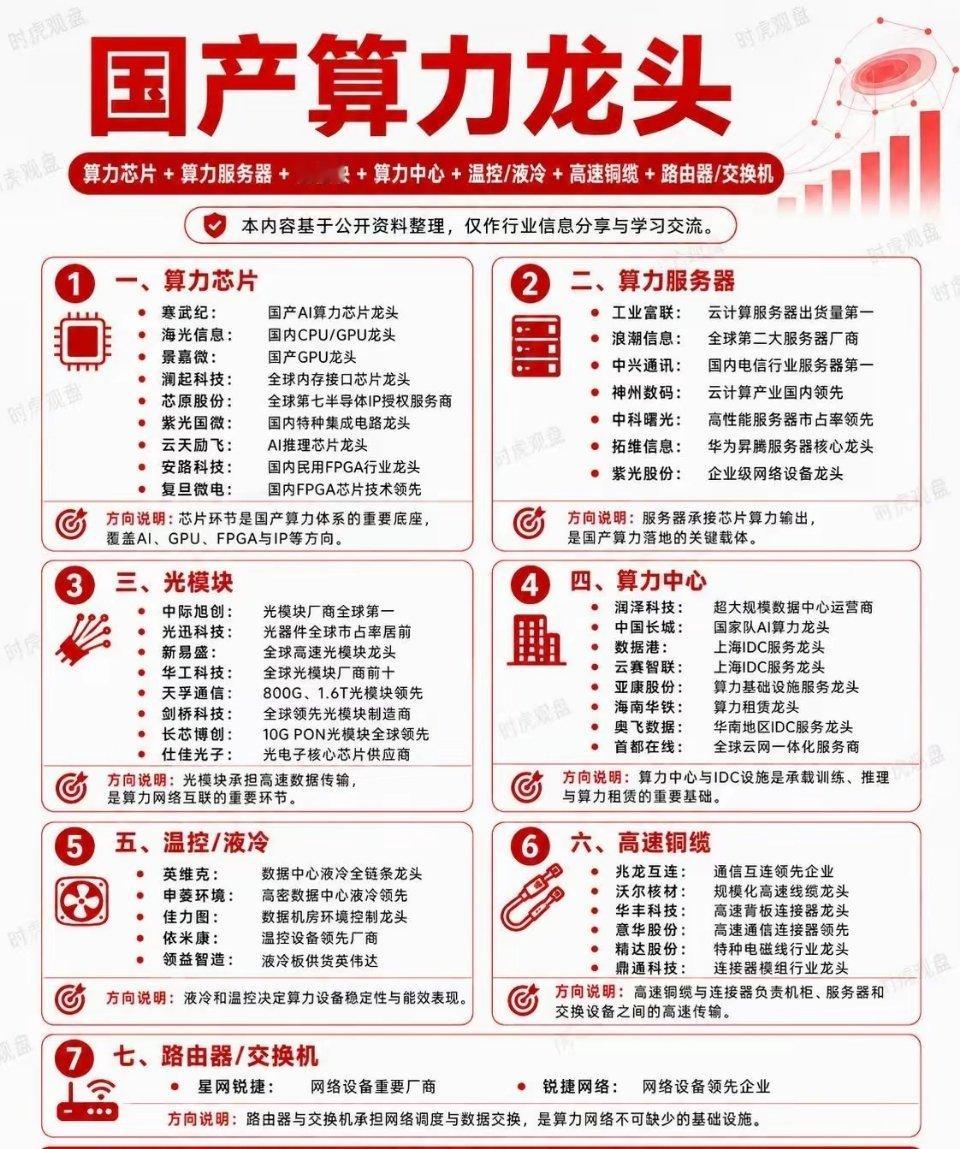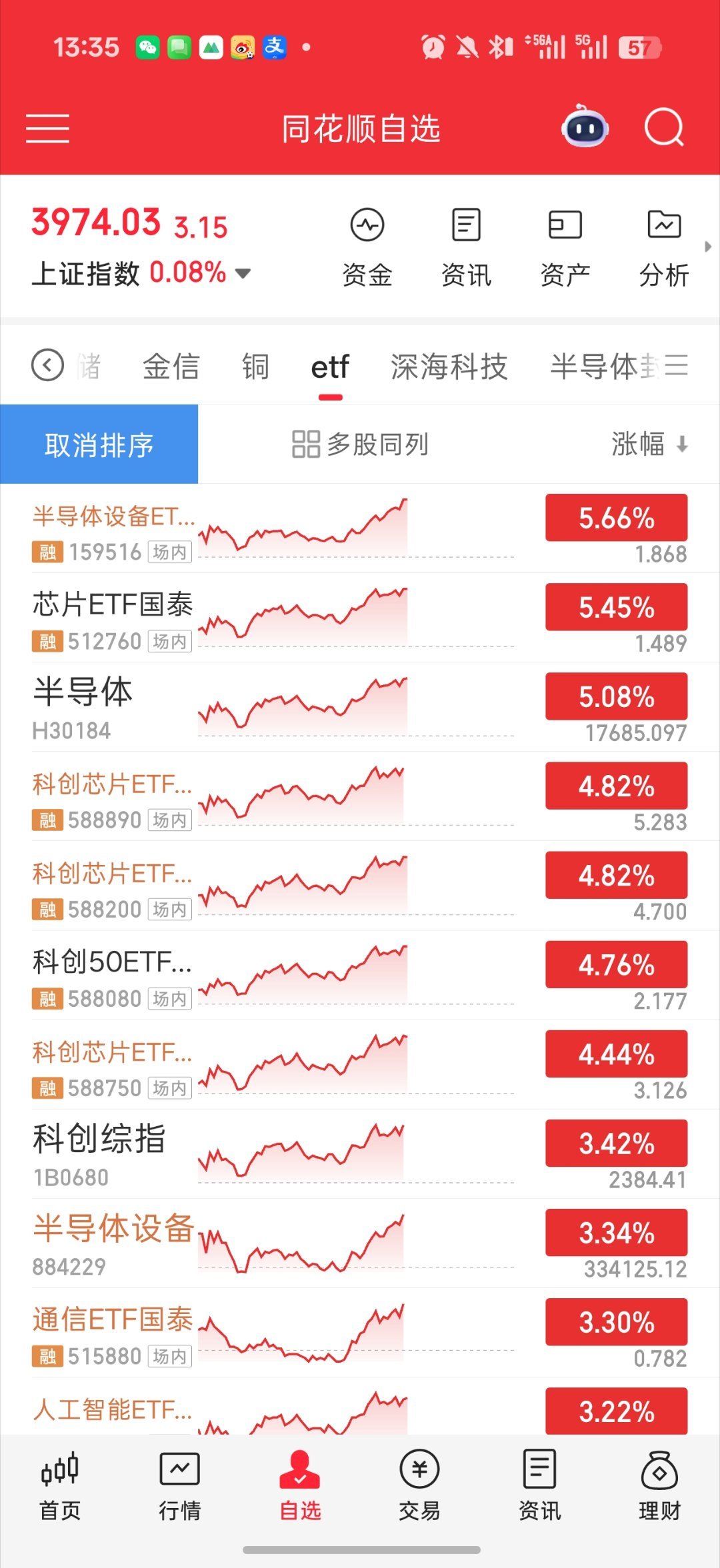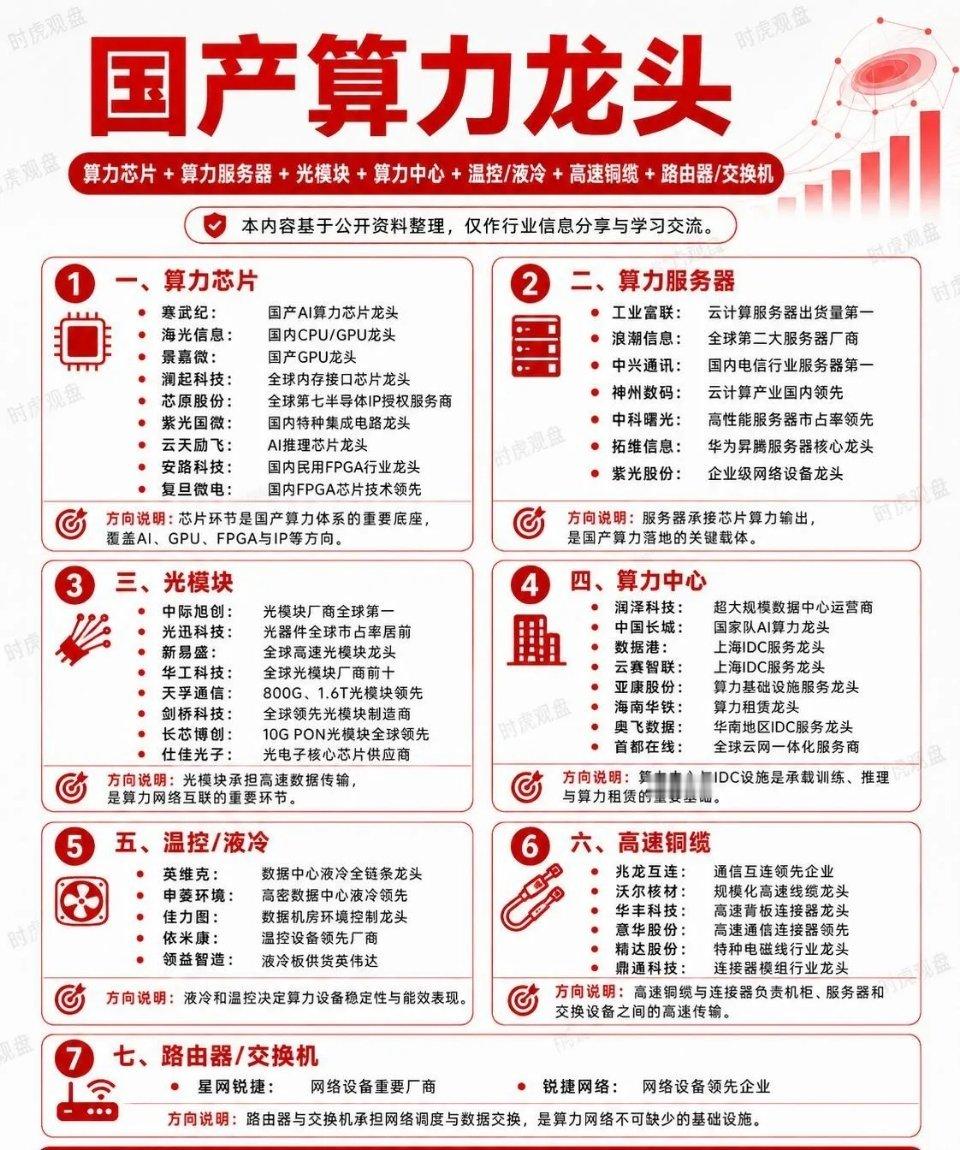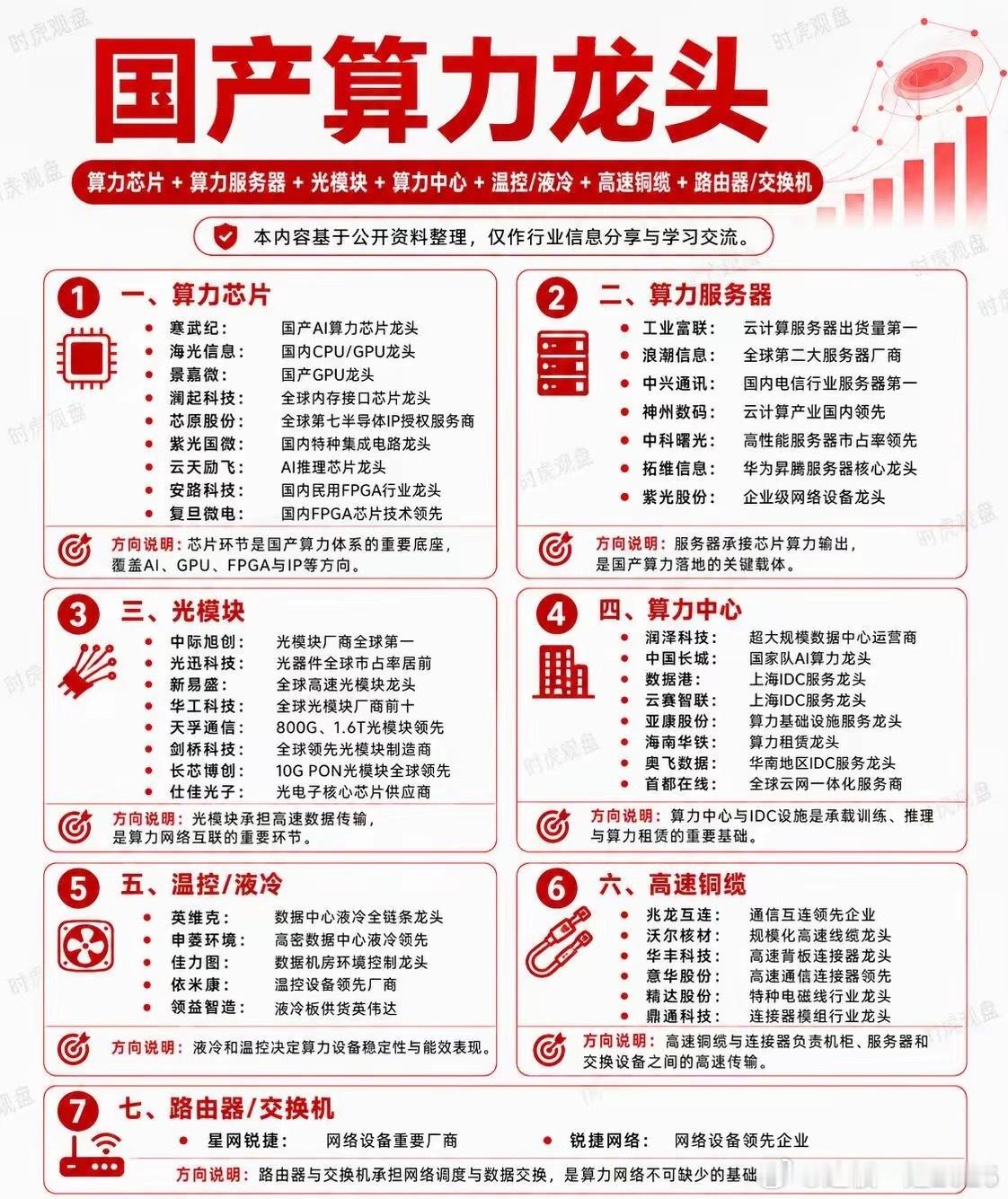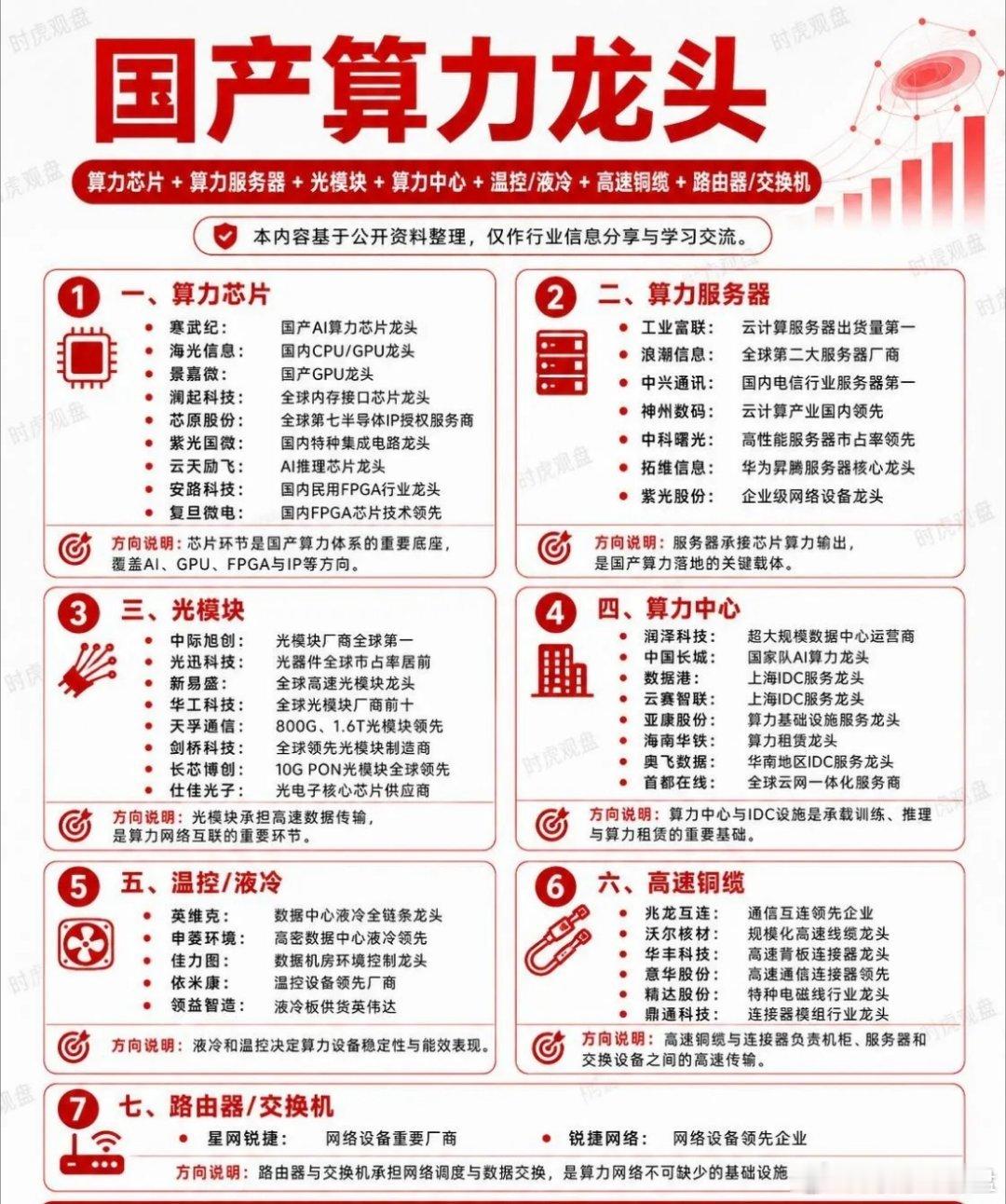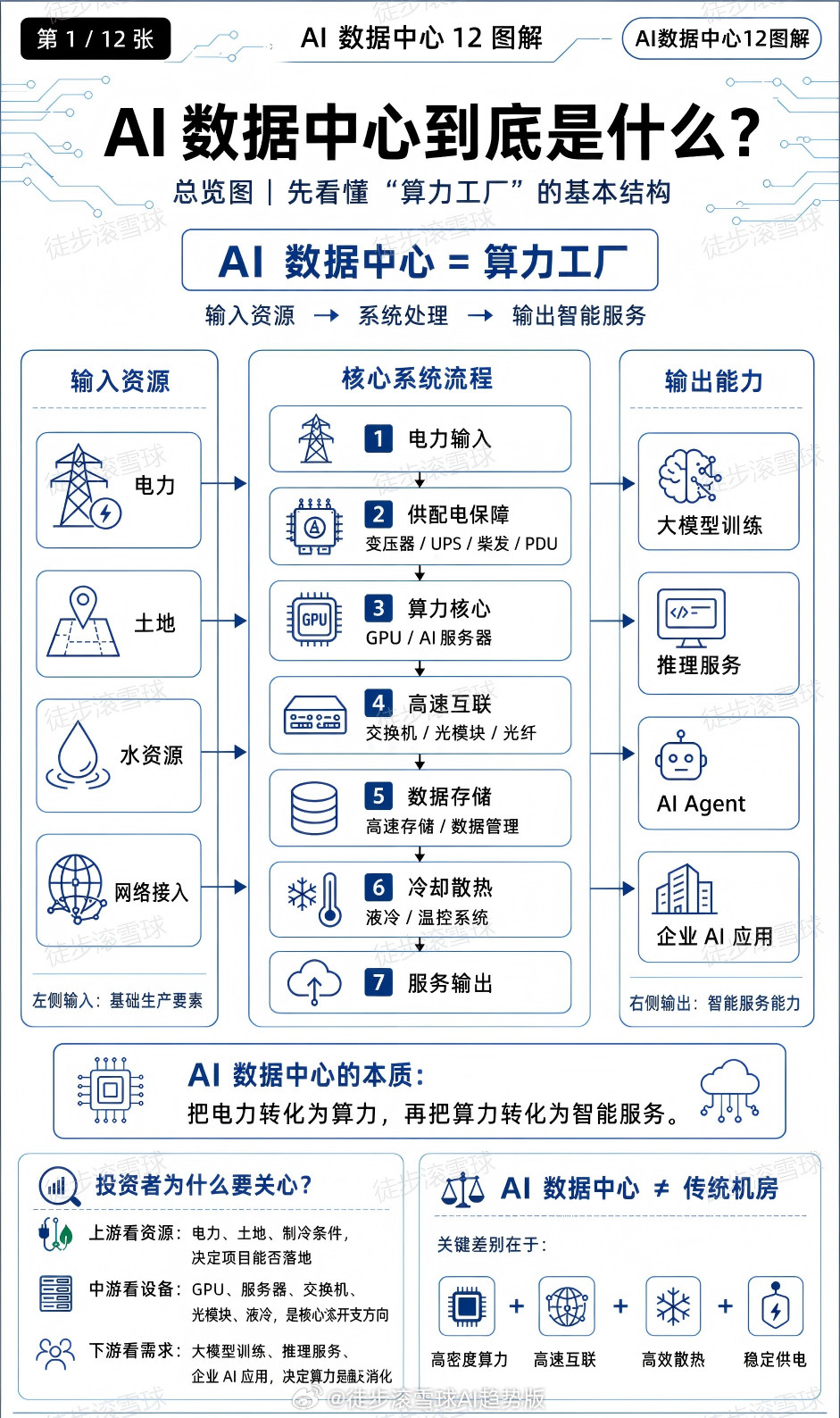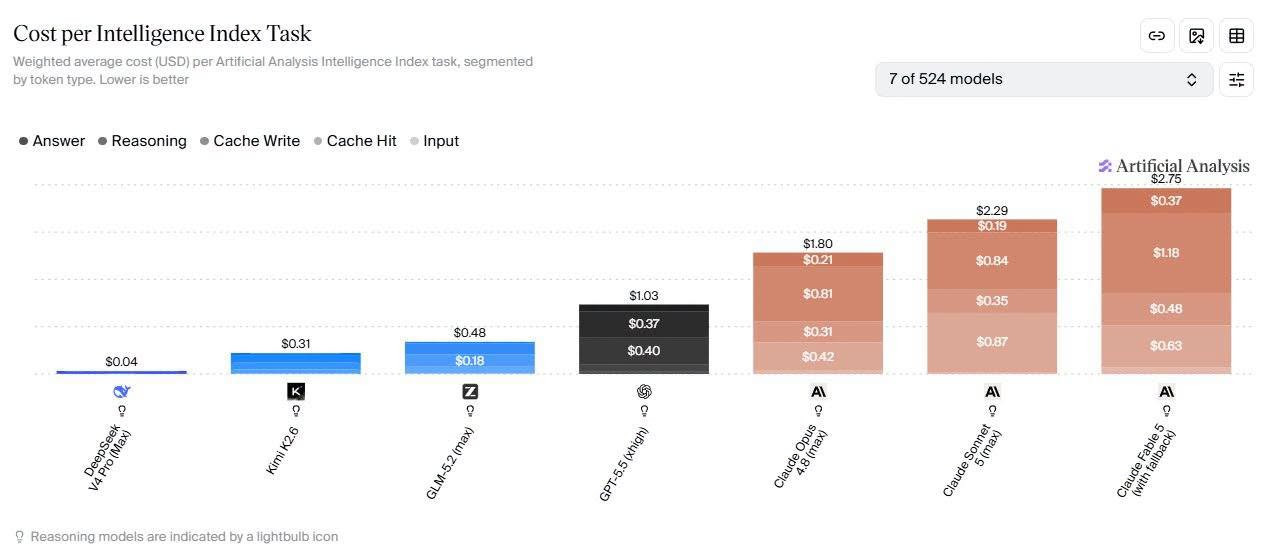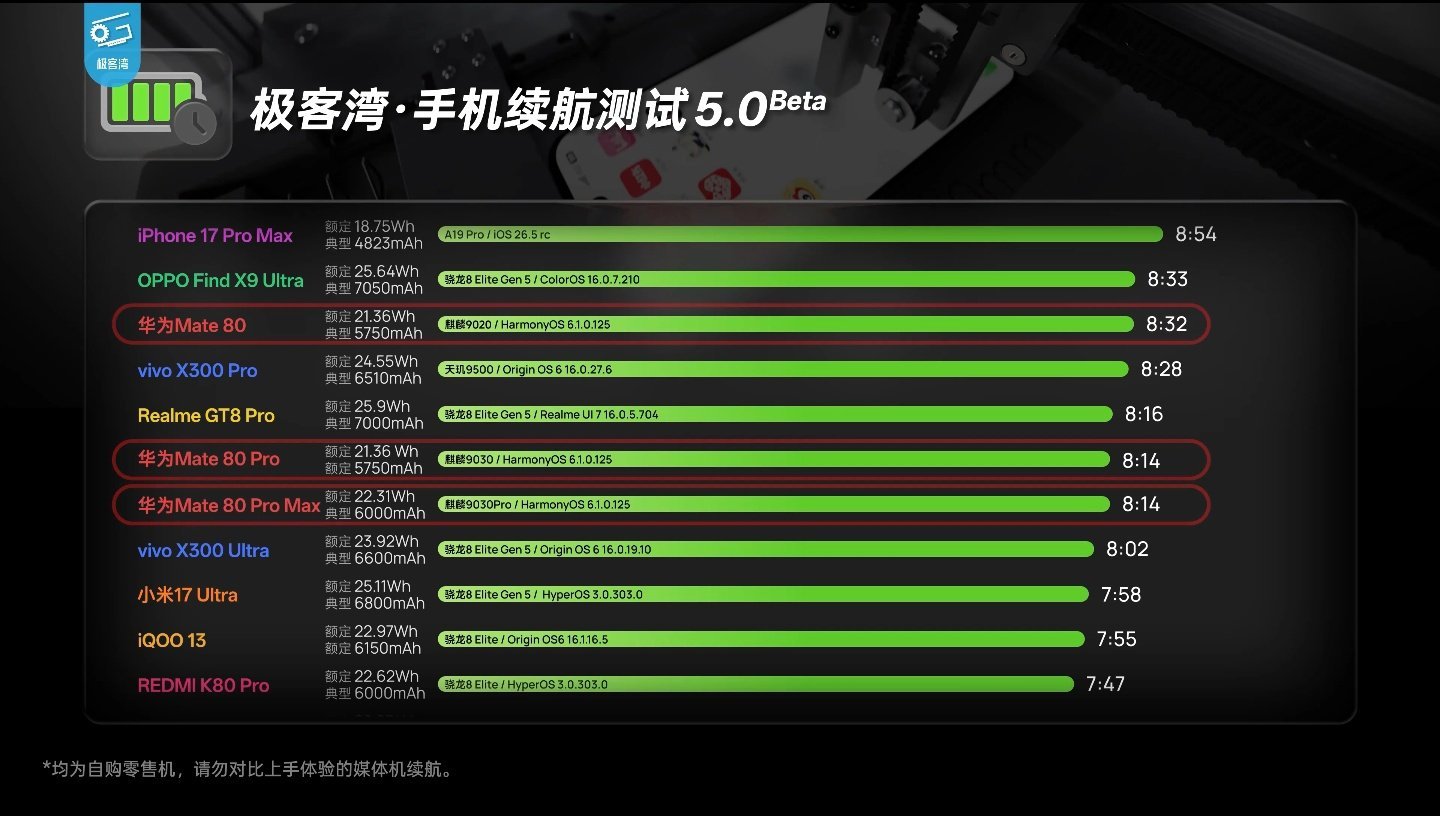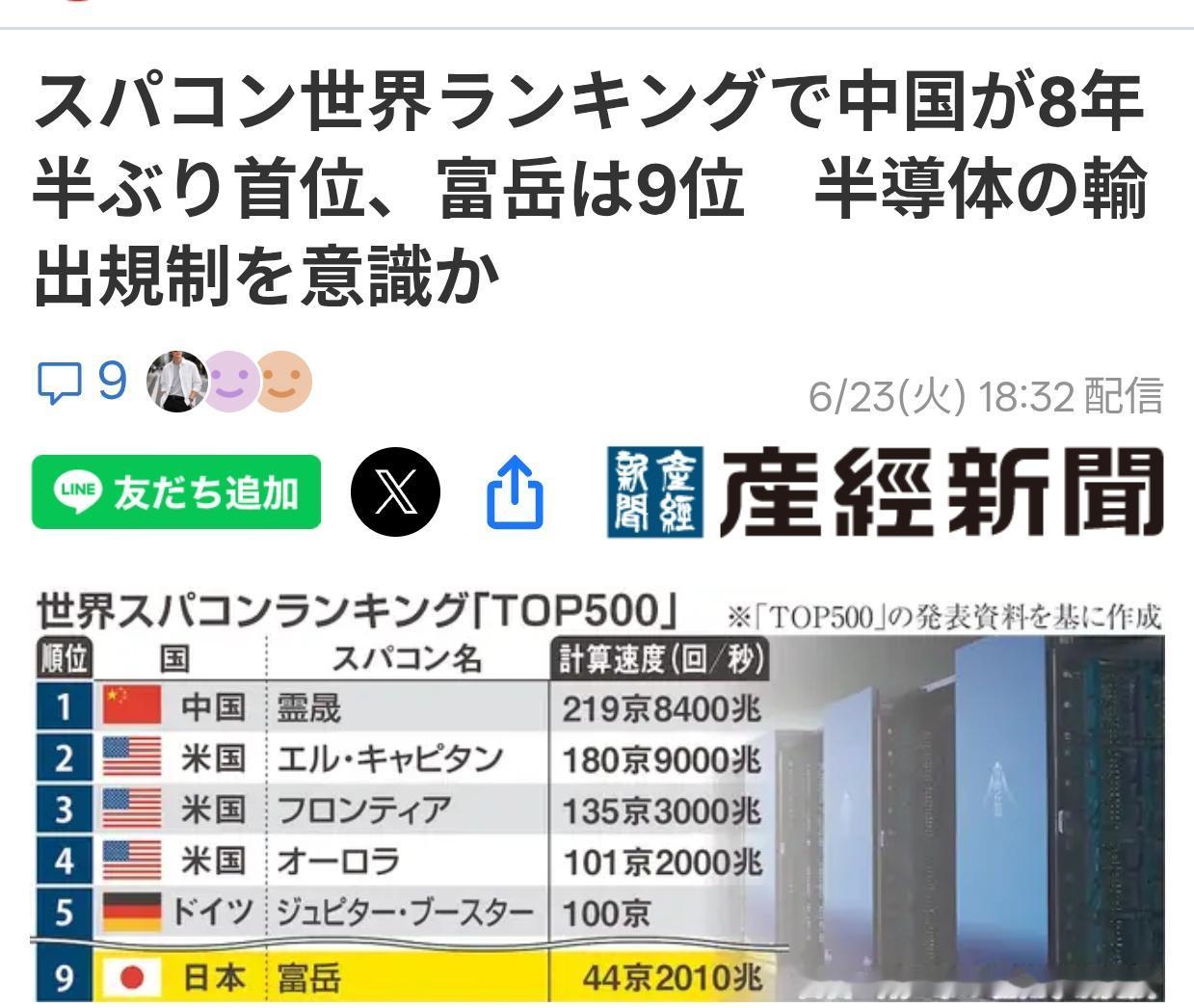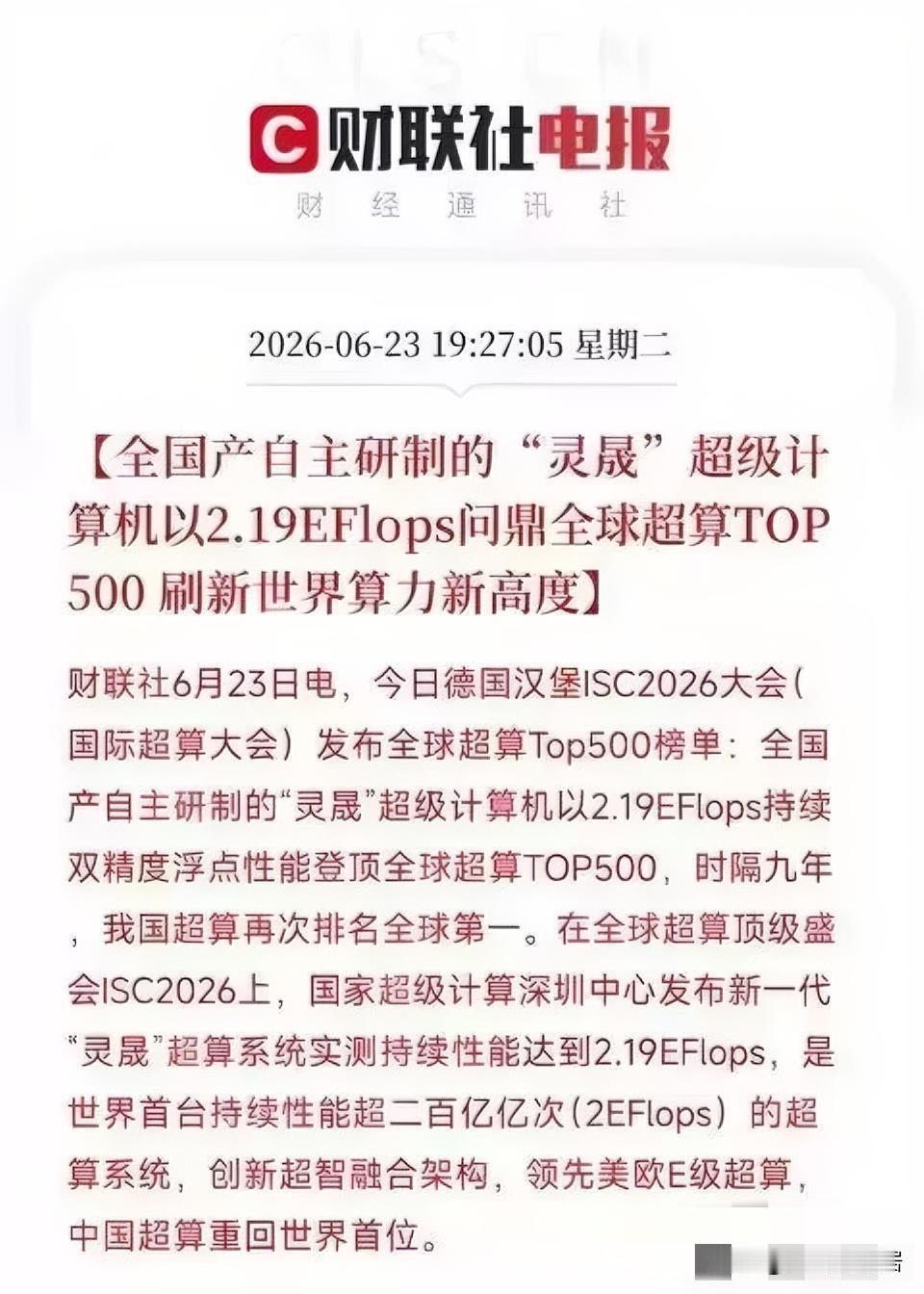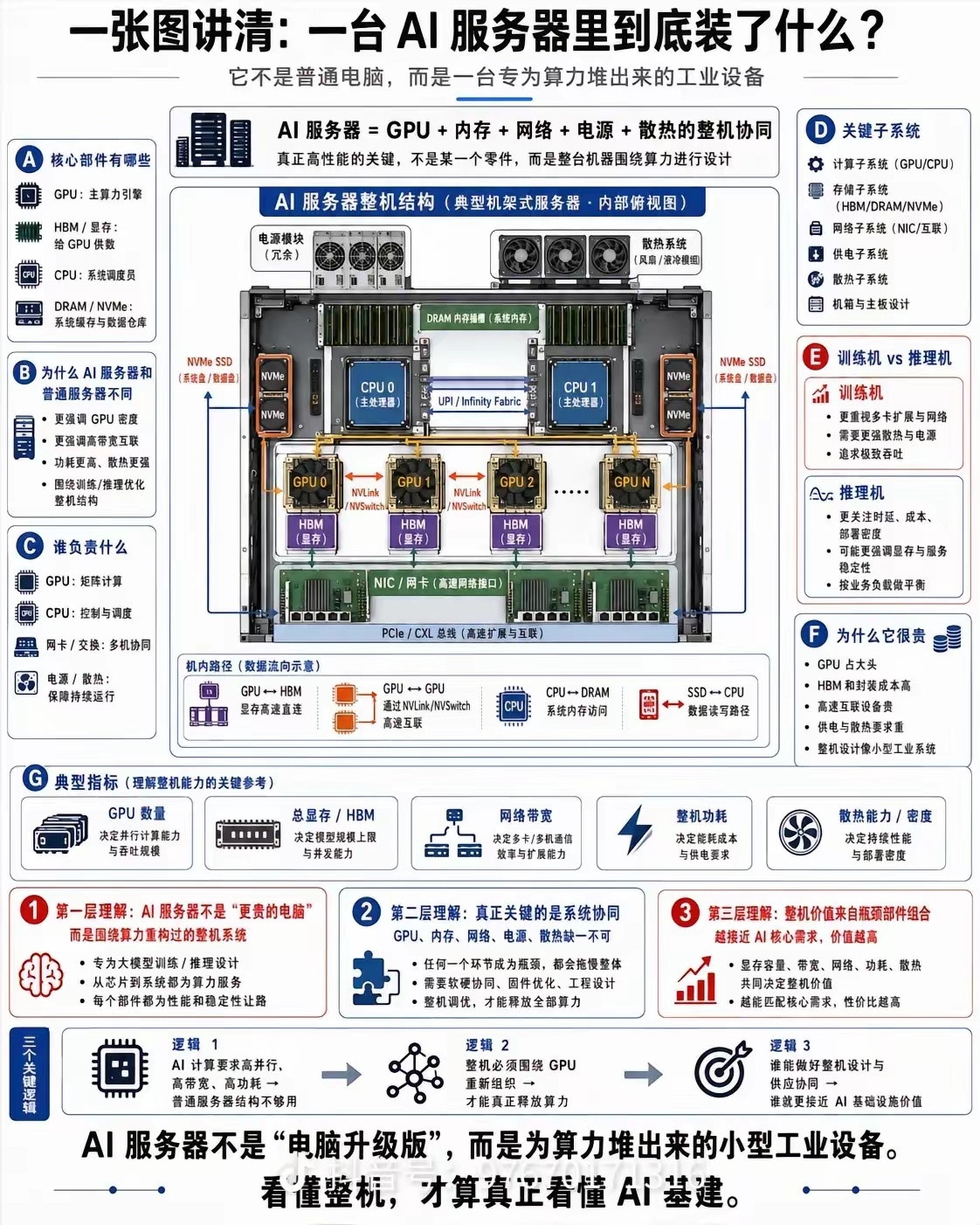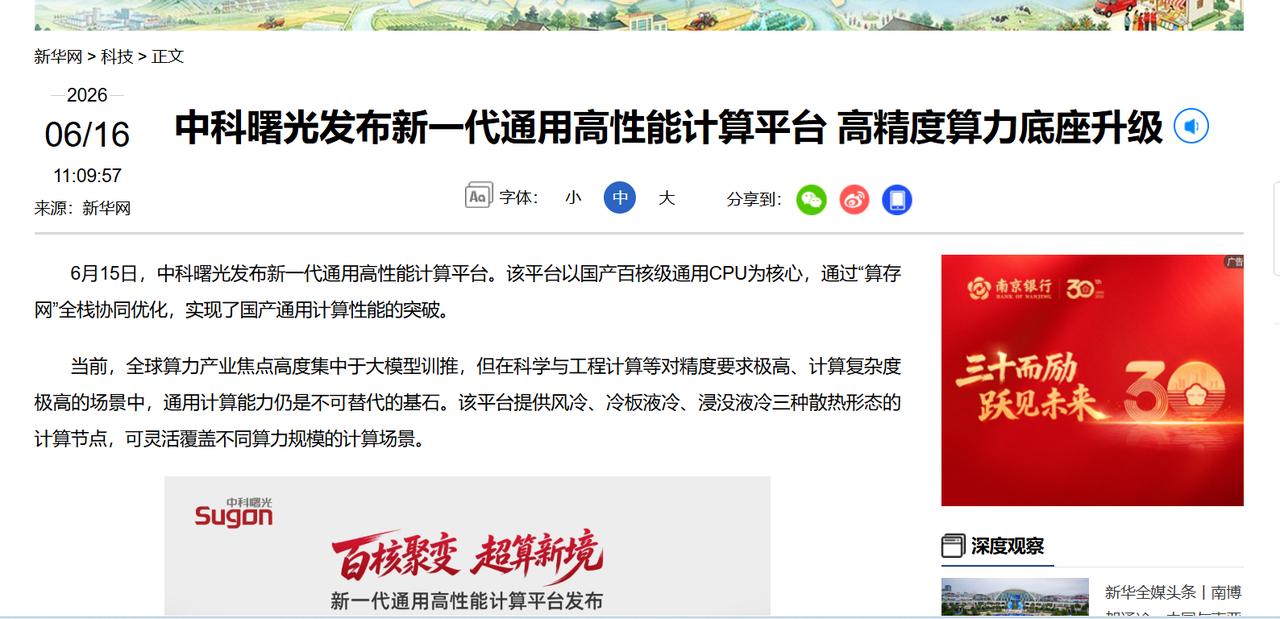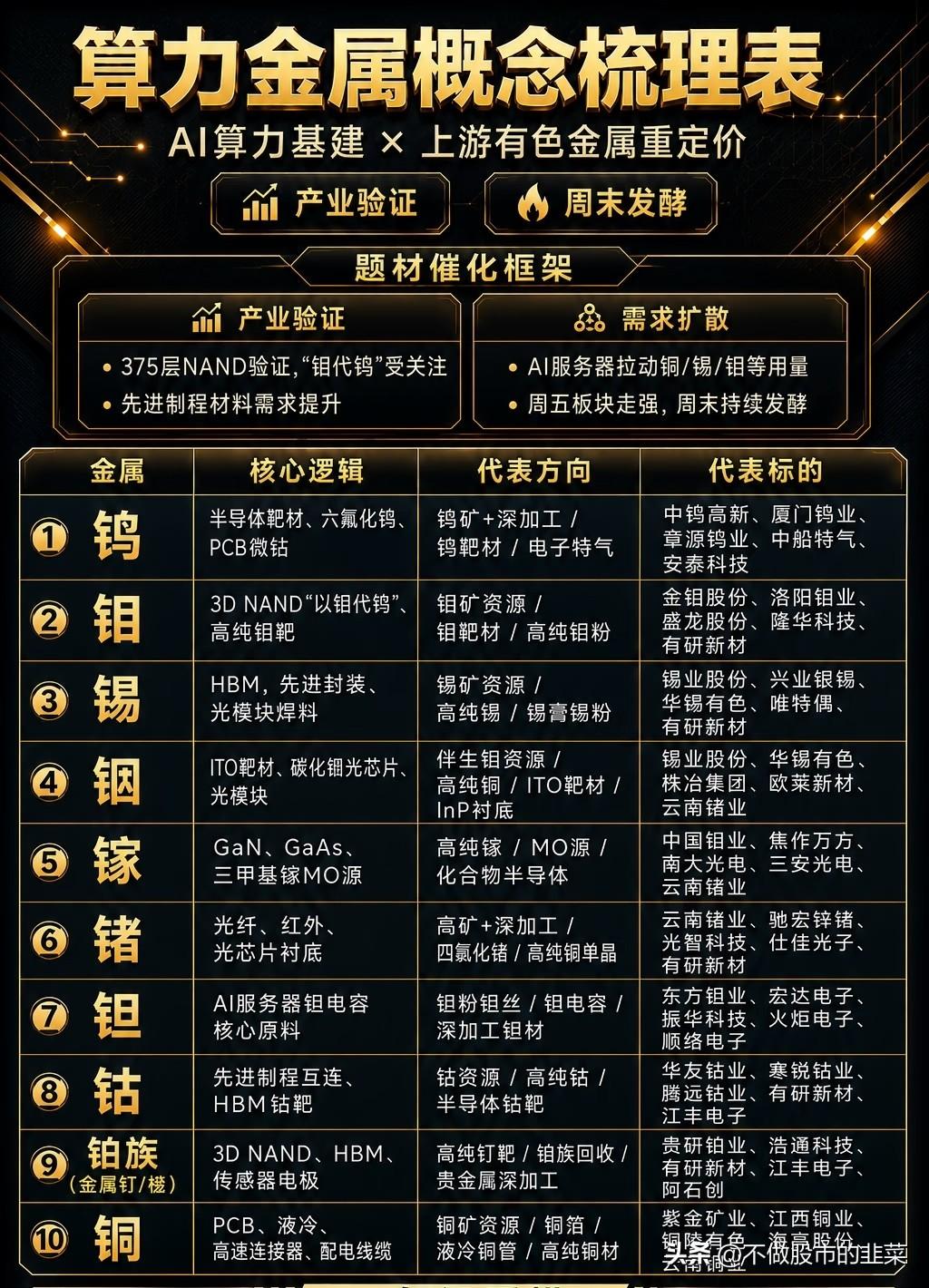
新加坡联合早报今天(7月19日)写道:“英伟达几乎垄断全球人工智能(AI)晶片市
新加坡联合早报今天(7月19日)写道:“英伟达几乎垄断全球人工智能(AI)晶片市场,订单多得做不完,但客户也在同时寻找摆脱它的方法。”评几句新加坡联合早报7月19日的报道,戳破了一个看似矛盾的行业真相——英伟达订单多到做不完,但它的金主们却在暗中"养备胎"。这不是简单的商业博弈,而是整个AI产业正在经历的一场深层结构性裂变。先说一个反直觉的事实:越强的垄断,越催生替代需求。英伟达的CUDA生态确实是护城河,但护城河越深,客户"翻船"的代价就越大。谷歌TPU、亚马逊Trainium、微软Maia、AMDMI300X……这些名字过去两年密集出现在各大科技巨头的采购清单上。OpenAI甚至开始租用谷歌TPU为ChatGPT提供算力,这在一年前几乎是不可想象的。为什么?因为没人想重复英特尔时代的悲剧。当年全球服务器CPU几乎被英特尔一家包揽,结果定价权、迭代节奏全在对方手里。如今科技巨头们学乖了——买英伟达芯片是"刚需",但养一套替代方案是"战略保险"。Meta把43%的GPU采购份额给了AMD,Anthropic和谷歌签下百万级TPU大单,这些动作的本质不是"叛逃",而是"去风险化"。更深层的变量在"推理"市场。AI行业正从"训练为王"转向"推理主导"。训练追求极致算力,英伟达无可替代;但推理讲究成本效率和低延迟,这正是专用芯片(ASIC)的甜点区。预计到2030年,推理将占全球AI算力需求的75%。在这个赛道上,谷歌TPUv7的能效是前代两倍,Groq的LPU能把推理成本压到GPU的三分之一——这些数字对每天跑数亿次推理的云厂商来说,意味着真金白银。还有一个被低估的变量:DeepSeek效应。今年年初,深度求索用极低成本训练出媲美OpenAI的模型,震动了整个行业。它传递的信号很清晰:算法优化可以大幅降低对高端硬件的依赖。如果"堆卡"不再是唯一路径,英伟达的高溢价逻辑就会被动摇。当然,英伟达短期内不会被颠覆。Blackwell芯片2025年产能已被抢购一空,台积电CoWoS先进封装产能的一半以上被它拿下。但历史规律告诉我们:没有永恒的芯片霸主。英特尔统治了PC时代二十年,最终在移动浪潮中掉队;英伟达能否避免同样的剧本,取决于它能不能在客户"另寻新欢"之前,先把自己的"新欢"——推理优化、成本下探、生态开放——做好。英伟达的订单排满,恰恰说明AI算力需求还在爆发期。但客户"养备胎"的动作,也预示着这个行业将从"卖方市场"逐步走向"多元竞争"。