[LG]《Unifying Sparse Attention with Hierarchical Memory for Scalable Long-Context LLM Serving》Z Zhao, B Lu, S Lin, Y Chen… [Microsoft Research] (2026)
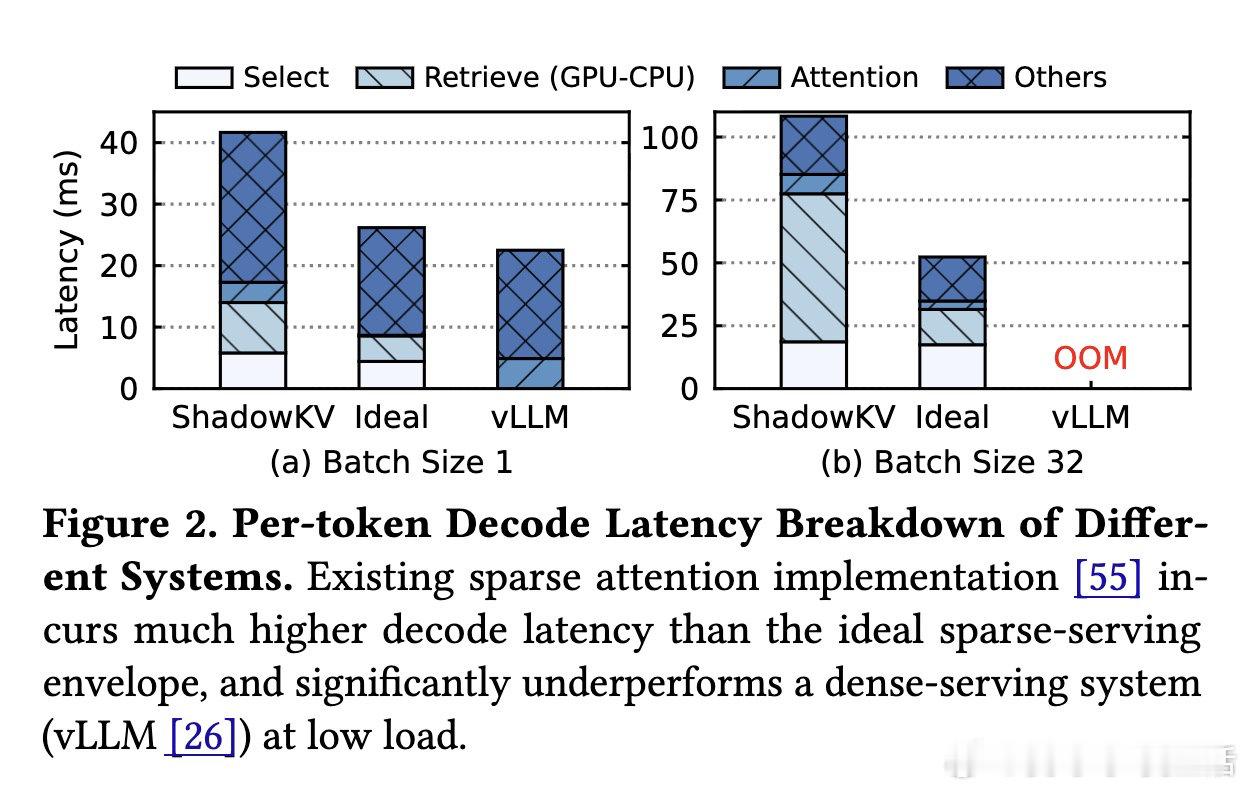
在长上下文LLM服务中,计算量并非唯一瓶颈。过去方法受困于只优化“算多少token”,本质原因是忽略了KV缓存跨GPU与CPU搬运的系统开销,稀疏优势被数据移动抵消。
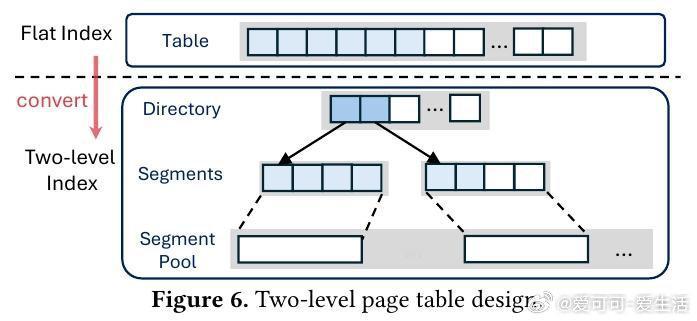
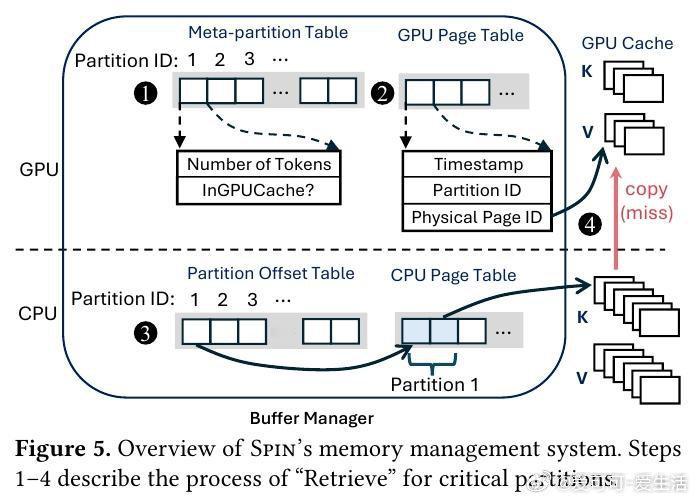
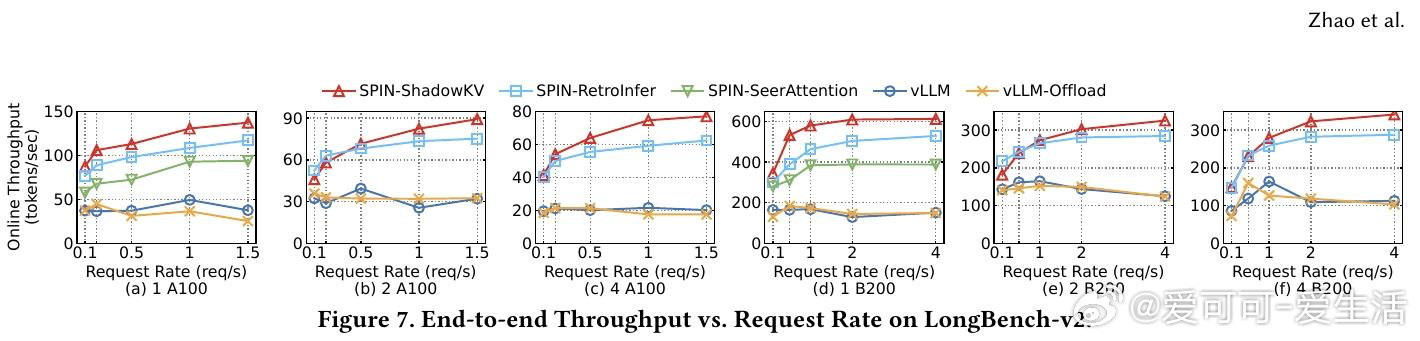
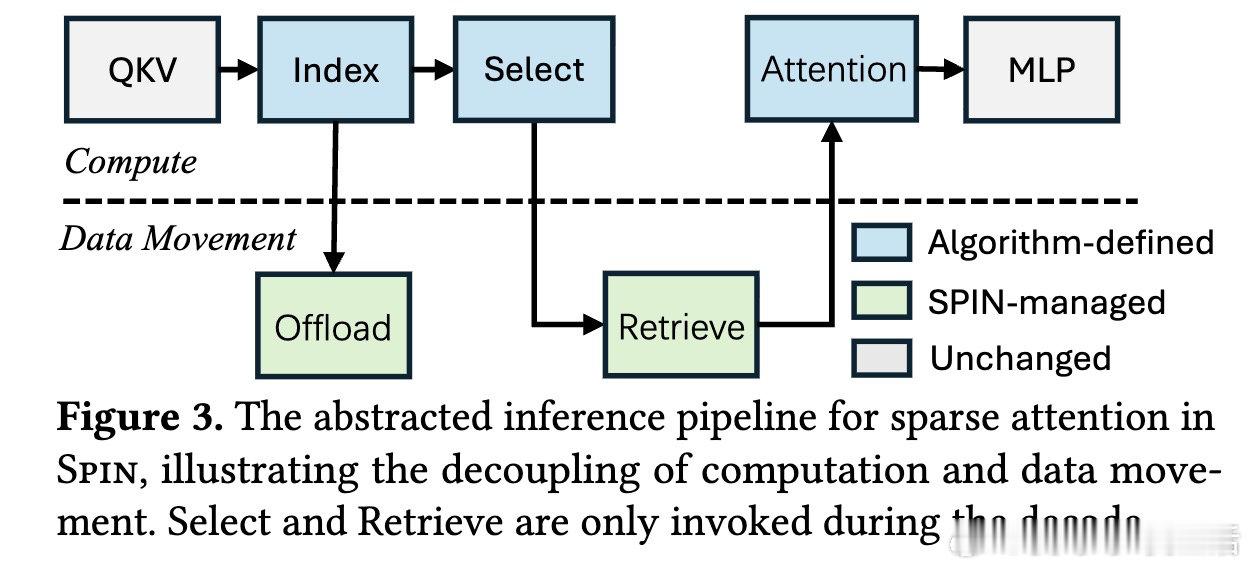
本文的核心洞见是:把稀疏注意力从“算法选择问题”重新看作“数据流调度问题”。由此,用统一分区抽象+分层KV缓存管理,把不同稀疏策略映射到同一执行管线,使稀疏真正转化为吞吐提升。
这项工作真正留下的遗产是把长上下文推理重心从计算转向内存与调度协同。它为后来者打开的新门是系统级重构稀疏推理,但尚未跨过的门槛是跨硬件环境下的数据迁移最优策略。
arxiv.org/abs/2604.26837 机器学习 人工智能 论文 AI创造营