【DeepSeek如何实现10倍效率提升?】
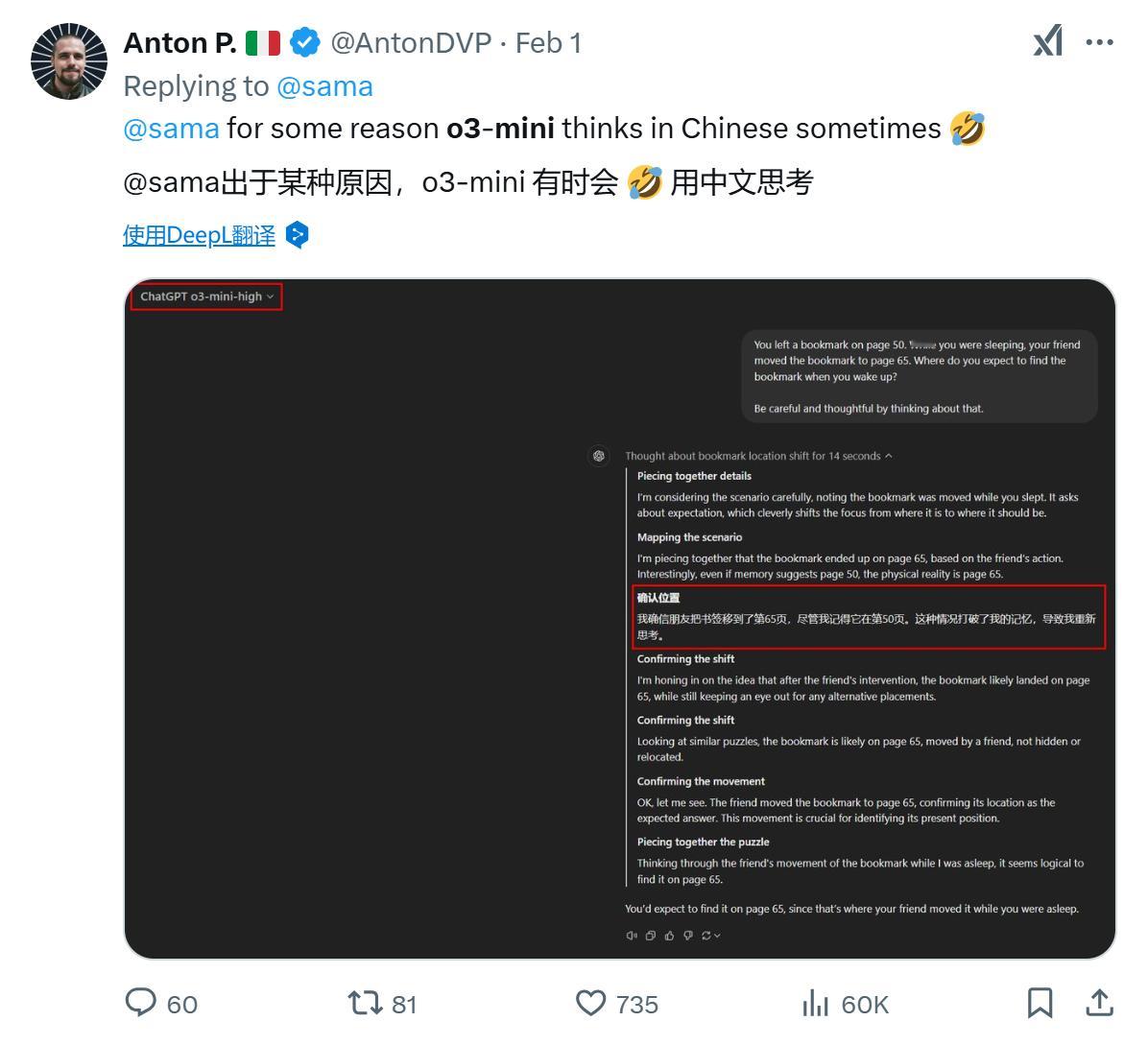
- DeepSeek成功训练出了一个拥有6710亿参数的混合专家模型(MoE)。这个看似平常的数字背后,藏着一个令人瞩目的效率革新:仅用2048块GPU、数月时间就完成了训练,效率比Meta等行业巨头高出10倍。
- 这次突破的关键在于其另辟蹊径的技术选择:没有采用传统的CUDA路线,而是转向了Nvidia的PTX(并行线程执行)编程。PTX作为一种介于高级GPU编程语言和底层机器代码之间的指令集架构,能实现更细粒度的优化,让开发者可以直接进行寄存器分配和线程级别的调整,这在CUDA C/C++等传统语言中是无法实现的。
- 这一选择不仅展现了技术团队的远见,更证明在AI领域,技术路线的创新选择有时比硬件投入更重要。DeepSeek的成功为整个行业提供了一个重要启示:在已有技术框架下深度优化,依然能获得革命性的突破。
思考:
- 底层优化对 AI 性能至关重要:DeepSeek 的案例有力地证明了,除了算法和模型架构的创新,底层的硬件优化对于 AI 性能的提升至关重要。这鼓励研究人员深入理解硬件结构,利用更低级的编程工具进行优化。
- PTX 编程的潜力:PTX 作为一种更接近硬件的编程方式,在 GPU 性能优化方面具有巨大的潜力,应该引起更多研究者和工程师的关注。
- AI 训练效率是未来竞争的关键: 训练大型 AI 模型需要大量的计算资源和时间。DeepSeek 的成功表明,通过技术创新和优化,可以显著提高训练效率,这对于未来的 AI 发展至关重要。