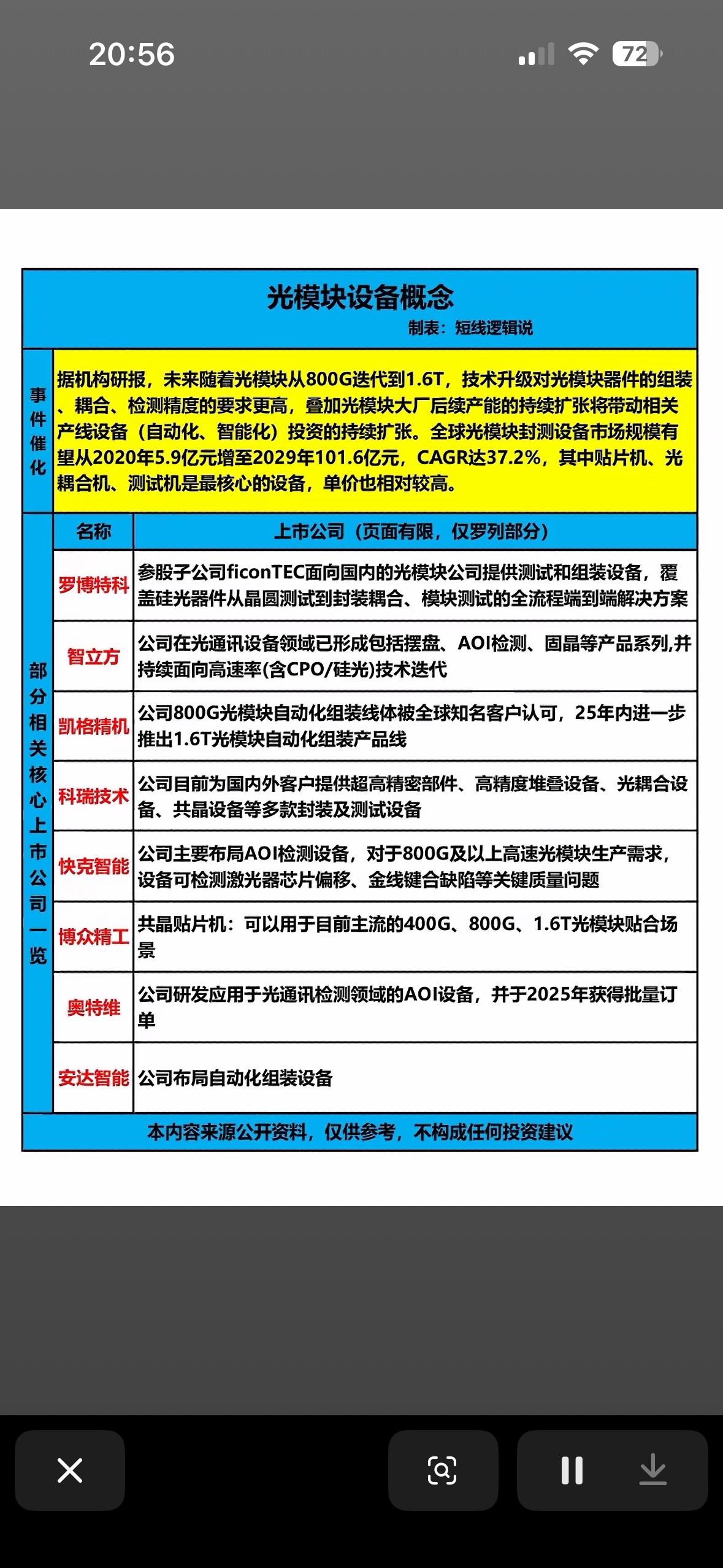
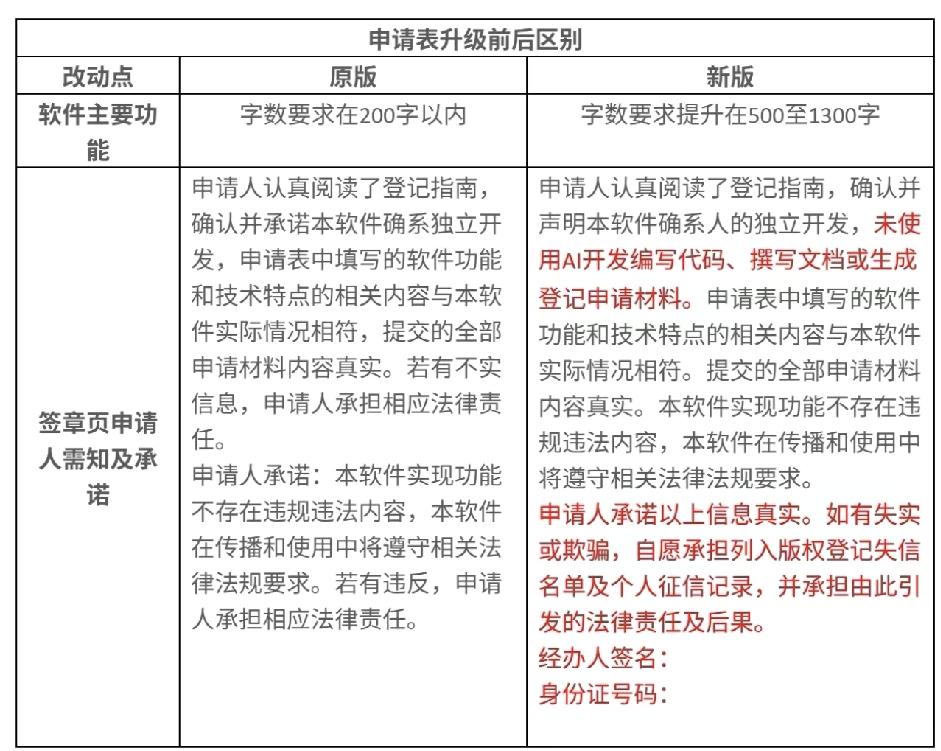
怪不得外媒惊呼“试验场”在中国,在AI应用这件事儿上,咱们确实走得很快,也走得很远! 首先得说数据这个AI的“燃料”。中国有16亿移动互联网用户,每天产生的浏览、交易、出行等各类数据,量级大到难以想象。这些不是零散的信息碎片,而是能直接用于模型训练的鲜活素材。更关键的是,这些数据覆盖了生活、工作、产业的方方面面,从城市交通流量到农业生产状况,从政务服务需求到医疗诊断场景,多样化的场景让AI能接触到最真实的需求反馈,不用在实验室里凭空模拟。 支撑这些数据运转的,是实打实的基础设施。全球62%的5G基站都在中国,483万个基站构建起的网络,让数据传输像日常聊天一样顺畅。再加上“东数西算”工程打造的全国一体化算力网络,962EFlops的总算力占全球21%,其中智能算力就达782EFlops,占比超过八成。算力中心的标准机架达到1085万架,服务器超3000万台,这些硬件让AI模型训练的速度比几年前快了几十倍,以前需要几个月的训练任务,现在几周就能完成。 光有数据和算力还不够,数据能安全流通才是关键。中国搞了数据产权“三权分置”的制度设计,既保护个人隐私和商业秘密,又能让数据在合规框架内流动。通过隐私保护计算、数据脱敏等技术,实现“原始数据不出域、数据可用不可见”,企业不用怕数据泄露,也不用为获取数据发愁。全国地市级以上的公共数据开放平台,已经累计开放了超过37万个有效数据集,近8年增长了44倍,这些公共数据和企业数据结合,让AI应用的开发成本大幅降低。 这种基础条件催生了AI应用的规模化落地。全球只有38%的企业能实现AI规模化部署,而中国这个比例达到45%,生成式AI的应用率更是超过全球均值。这不是靠单个企业的孤军奋战,而是整个生态的协同发力。从国产服务器占比超75%,到AI芯片、操作系统的关键突破,产业链的完整让技术落地不用受制于人。“数据要素×”行动推出后,数据产品上架量同比增长70%,催生出大量贴近实际需求的创新场景,形成了“应用-反馈-迭代”的良性循环。 更重要的是,这种“试验场”模式打破了技术普及的壁垒。开源平台的兴起让中小企业也能低成本使用AI技术,不用再面对高昂的研发投入。国家数据基础设施的建设,让不同地区、不同行业的企业都能享受到均等的算力和数据资源,避免了技术红利集中在少数头部企业。这种普惠性的发展,让AI应用的渗透速度远超很多国家,从城市的智慧交通到乡村的智慧农业,从大型工厂的智能质检到小商铺的数字化经营,AI不再是高高在上的技术概念,而是融入日常的实用工具。 这种快速发展背后,是发展和安全的统筹兼顾。数据安全法、个人信息保护法等法律法规筑牢底线,数据收集、流转、使用的全流程都有明确规范。通过数据产权登记、安全监测、权限管控等措施,既防范了数据泄露、滥用的风险,又没有因为过度监管而束缚创新。这种平衡让企业敢于投入,用户愿意配合,数据要素的价值得以充分释放。 中国能成为AI应用的“试验场”,本质上是超大规模市场、完善的基础设施、清晰的制度规则和完整的产业链相互作用的结果。这里有最丰富的应用场景让AI试错迭代,有最充足的算力和数据支撑技术突破,有最顺畅的流通机制让创新快速扩散。这种独特的发展环境,让AI技术不仅能快速落地,还能不断优化适配,最终形成具有全球竞争力的应用生态,这也是中国AI能走得快、走得远的核心密码。