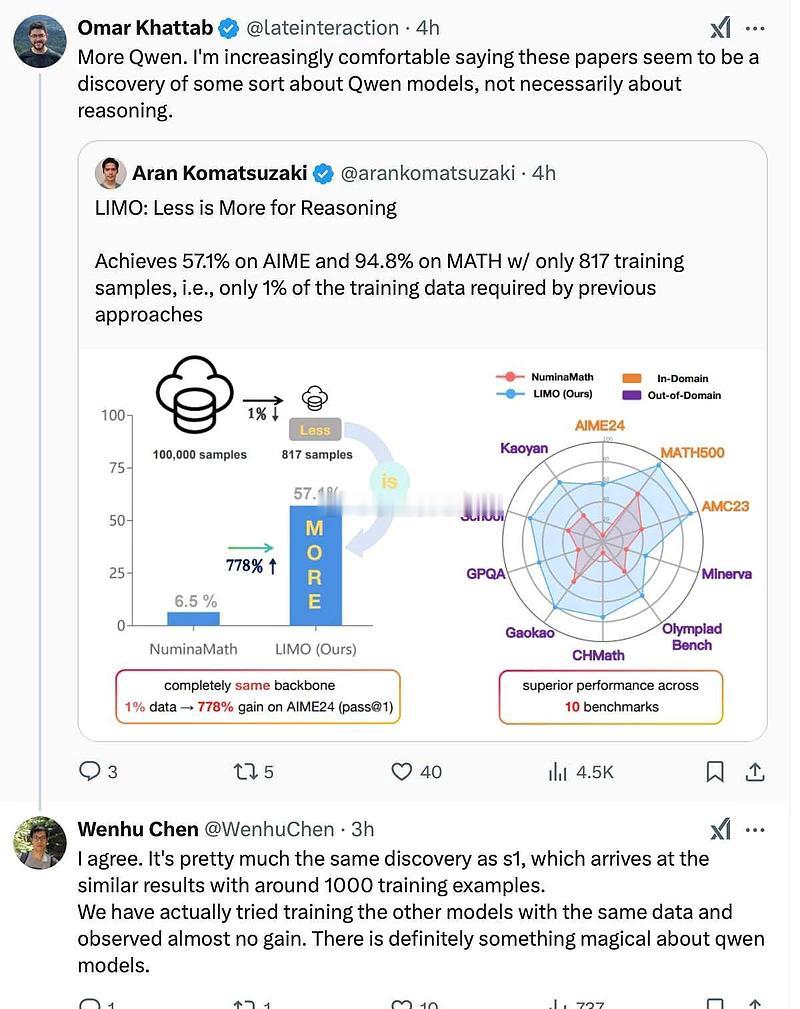
真相来了!李飞飞那个不到50美元的大模型s1,基座还是咱们的模型——阿里的通义千问。
具体来讲,李飞飞是用谷歌的Gemini 2.0 FTE,提炼出来1000个样本,然后再以千问2.5-32B-Instruct模型为基座,进行监督微调,训练出了堪比DeepSeek和o1的新模型s1。
换言之,李飞飞最大的贡献,是找到这1000个样本,从而实现了低成本的性能提升,但没有千问2.5,她根本得不到s1。
事实上,国外还有其他团队,也用极低成本训练出了新模型,但无一例外,都是使用通义模型作为基座实现的。
而且神奇的是,如果换作其他模型,却无法得到能力提升,所以,真正神奇的是千问2.5,而不是s1。
而最神奇的是,中国一进步,世界就进步;中国一开源,世界就突破;中国行我也行的奥秘,在于中国才是真正的开源。
都看德银今天的研报了吧?China eats the world,2025年,是中国超越世界其他地区的时刻!
那个顶着Open名号的AI公司,却还在一点点的挤牙膏:今天放个DeepResearch,明天放个免费搜索,为什么?因为商业模式破功了啊,老弟