三巨头同日接入DeepSeek
使用deepseek似乎不难,很多人都部署成功了?因为大模型推理,本来就很简单,代码才1000多行!
群众对大模型技术不太熟悉,美国又狠命忽悠,说是特别高级的高科技,要几百亿美元才做得出。所以,大家容易误会,以为大模型很复杂。
真相是,高水平大模型的“训练”,确实很复杂。中小公司搞不了训练,搞懂都不容易。但是,大模型“推理”,是很简单的。个人就可以把开源的大模型推理,部署成功,真的不难。
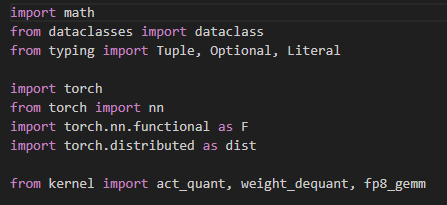
例如我下载了deepseek v3的源码,用python写的。python写大模型代码非常紧凑,最大一个代码文件才800行!加上别的源文件,一共1500行代码就差不多了。里面自己实现了fp8的gemm,也就是8比特表示浮点数的矩阵乘法。其它是借了Meta的PyTorch框架,这就是开源的力量,很厉害的程序 代码也不长。
当然这是借助了python。如果用C++来,大模型推理其实也不复杂。
我下载了Meta的LLama开源大模型的C++工程源码,核心的llama.cpp也就是1万行,里面描述了如何进行推理计算。按照C语言的标准,这真的不算复杂。加上别的源文件,一共也就3万多行代码。底层实现都说清楚了。就是有个张量矩阵运算库ggml,要支持各种平台和硬件,如cuda、opencl、blas,这个代码量大。但是这是C工程的特色,库函数弄好了就不用管了,编译就行。
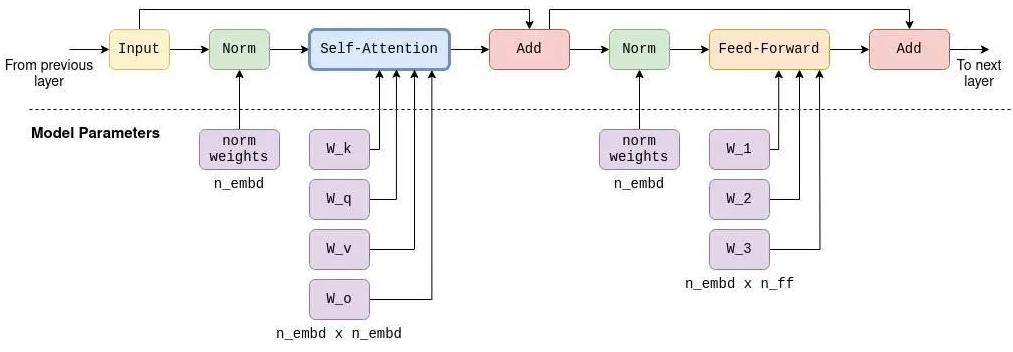
看C代码会比较清楚,大模型推理就是进行了图二的计算过程,矩阵不断地乘了加,加了乘,没几步。当然这是一层,deepseek有60层,但就是重复,代码都一样。
所以,只要有厉害的权重文件开源,把大模型推理玩起来是很简单的!自己看代码都不难,个人PC下载来安装小一些权重的都行。
这就是deepseek开源的厉害之处,推理用起来非常容易!








天才
这发明那么厉害,能不能帮警察把骗子揪出来?