【国盛计算机】国内模型开启世界级竞赛
摘自刘高畅/李可夫 计算机畅想
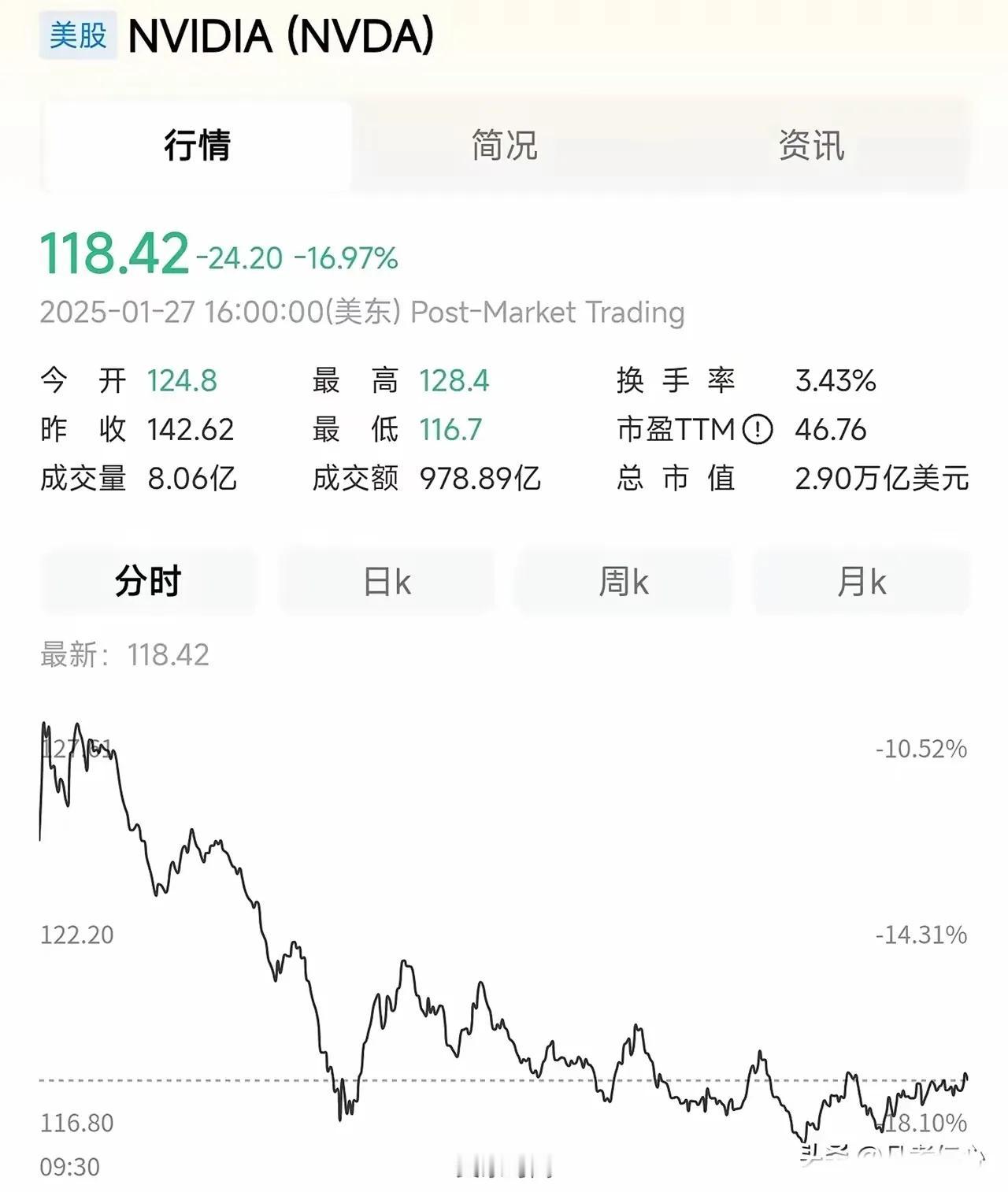
开源DeepSeek-R1低成本对标o1,震撼海外科技界。2025年1月20日,DeepSeek开源DeepSeek-R1模型,在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。同时DeepSeek通过 DeepSeek-R1 的输出,蒸馏了6个小模型开源给社区,其中 32B 和 70B 模型在多项能力上实现了对标 OpenAI o1-mini的效果。DeepSeek-R1 API服务定价远低于OpenAI o1。OpenAI CEO 1月24日称将向ChatGPT 免费用户提供o3-min,我们认为这体现了DeepSeek给到OpenAI的竞争压力。海外微软、亚马逊、英伟达、AMD纷纷将DeepSeek模型适配到自己的云服务或硬件,美国总统特朗普称DeepSeek给美国的科技行业敲响警钟,彰显了业界对DeepSeek技术实力的认可。
DeepSeek技术路径解析:算法层面多维度优化。DeepSeek团队在算法上的创新和工程上的极致优化。据DeepSeek-R1论文DeepSeek-V3技术报告,其优化包括以下方向:1)不需要监督微调,纯强化学习驱动。2)强化学习算法的创新:包括开发GRPO算法节省了强化学习的训练成本;没有应用结果或过程奖励模型,而采用了基于规则的奖励系统。3)多头潜在注意力机制(MLA)和专家混合架构(MOE)的结合。4)FP8混合精度框架。5)使用PTX从更底层调用硬件。DeepSeek证明了在大模型的发展进程中除了算力,软件层面的优化同样占据着举足轻重的地位,中国拥有大量高素质的算法设计、模型优化等方面的专业人才,为中国在大模型领域追赶和超越世界前沿水平提供了重要的支撑。
字节大模型进展不断,应用落地加速。1)1月20日豆包实时语音大模型在豆包 APP 全量开放,在情绪理解和情感表达方面与GPT-4O相比优势明显。情商层面,模型在情感理解、情感承接以及情感表达等方面也取得显著进展,能较为准确地捕捉、回应人类情感信息。2)1月22日,豆包全新基础模型 Doubao-1.5-pro发布,能力全面升级,并进一步提升了多模态能力。Doubao-1.5-pro使用MoE 架构,仅用较小激活参数,即可比肩一流超大稠密预训练模型的性能,探索模型性能和推理性能之间的极致平衡。豆包团队还通过 RL 算法的突破和工程优化研发了深度思考模式,在AIME上已经超过O1-preview,O1等推理模型。
国产模型进步影响深远,打开广阔投资机遇。国产大模型技术的不断进步带来的变革令人期待。1.更低的成本让企业在开发 AI 应用时,能够以、更高的效率进行,有望加速国内 AI 应用从概念走向实际落地。DeepSeek开源的蒸馏小模型超越 OpenAI o1-mini也有望为模型加速在端侧落地。2.算力效率提高,AGI有望来临。我们认为算力利用效率的提高一方面有望加速大模型的进步,另一方面也降低了大模型的训练和部署门槛,有望激励更多玩家入局大模型产业。微软CEO引用“杰文斯悖论”,表示随着 AI 的效率和可访问性越来越高,我们将看到它的使用量猛增。大模型应用对算力的需求为国产算力产业链带来了巨大的发展机遇。3.投资内容更加丰富,包括1)互联网大厂合作生态如软件服务商;2)AI Agent如各领域SAAS;3)其他细分领域如目前AI技术应用于军事领域,特种云建设有望加速;AI 编程提升效率,计算机行业公司深度受益。
建议关注:
AI Agent软件:萤石网络、汉得信息、中科创达、鼎捷数智、海天瑞声、新致软件、云天励飞、焦点科技、泛微网络、致远互联、金山办公、润达医疗、星环科技、协创数据、创业黑马、恒生电子、迈富时、小商品城、金证股份、卫宁健康、创业慧康、晶泰控股、佳发教育、嘉和美康、金桥信息、新大陆等。
字节AI链:寒武纪、恒玄科技、天键股份、润欣科技、实丰文化、乐鑫科技、萤石网络、中芯国际、孩子王、润泽科技、欧陆通、华懋科技、浪潮信息、中兴通讯、中科曙光、兆易创新、国光电器、法本信息、新致软件、亚康股份、申菱环境、兆龙互连等。
军工AI:能科科技、品高股份、海格通信、振芯科技、道通科技。
风险提示:AI技术迭代不及预期风险;经济下行超预期风险;行业竞争加剧风险。