台媒:大陆最新AI技术“神速突破”!硅谷巨头吓到崩溃,员工陷恐慌!
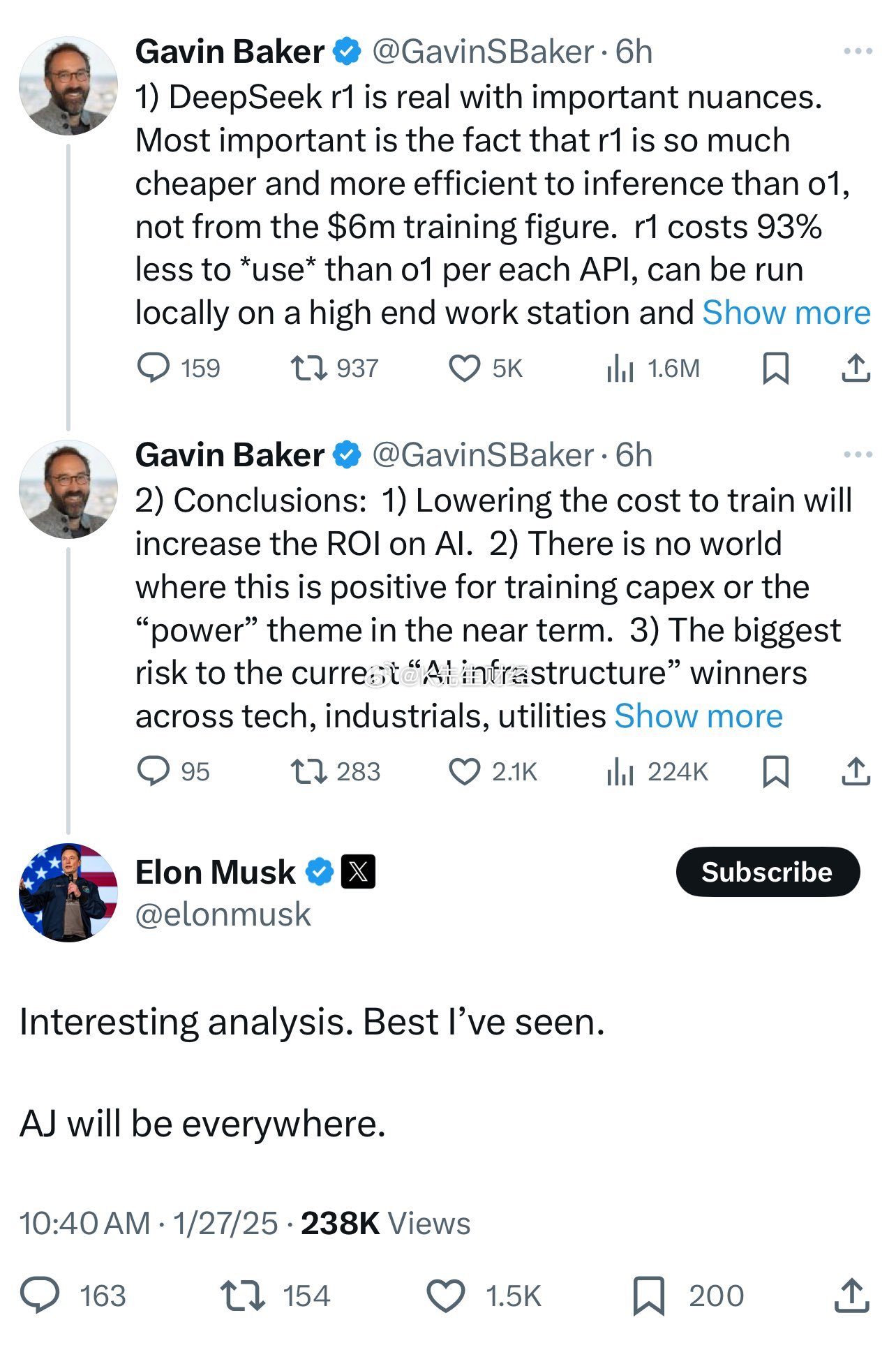
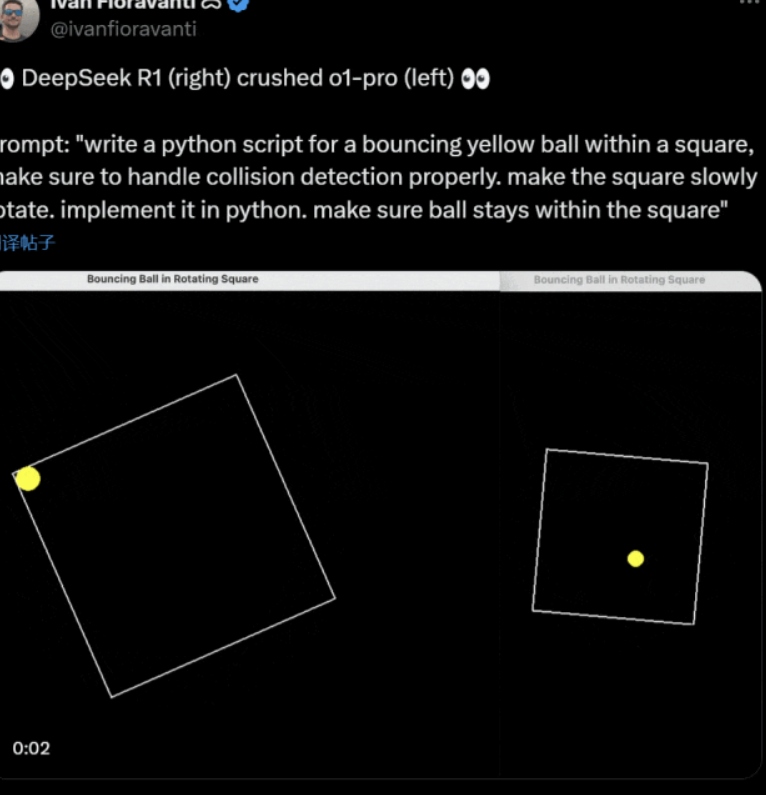
台媒报道,大陆AI新创企业DeepSeek(深度探求)近期推出“DeepSeek-V3”与“DeepSeek-R1”两款最新的AI模型。这两款模型具备低廉的制造成本,且採用运算能力相对低阶的辉达H800晶片,却拥有与全球顶尖AI语言模型匹敌的表现(例如OpenAI 的 ChatGPT-4),让硅谷巨头相当震惊。
据美国匿名职场论坛TeamBlind上一位自称Meta员工的贴文,自DeepSeek发布DeepSeek-V3以来,Meta旗下的Llama 4在各项测试中落后,让公司的生成式AI部门陷入恐慌。更令人忧虑的是,这间鲜为人知的中国公司仅耗资557万美元就达成这项技术成就。
该Meta员工指出,公司内部生成式AI部门的高阶主管薪资都超过 DeepSeek的开发成本,而Meta目前拥有数十位此类高管,令人质疑部门庞大成本的合理性。
该员工透露,目前Meta工程师正疯狂研究分析DeepSeek的成功秘诀,试图複制任何可複制的技术。然而,当DeepSeek-R1发布时,情况变得更加严峻。该员工表示,虽然无法透露具体细节,但一些资讯将很快公开。
DeepSeek-V3于去年12月26日发布后,随即成为开源模型的领头羊。DeepSeek公布的技术报告数据显示,Meta的Llama 3.1-405B仅在 MMLU-Pro大规模多任务理解数据集上接近DeepSeek-V3的水准,而在其他项目中表现几乎都不及八成。
今年1月20日,DeepSeek 正式发表DeepSeek-R1,官方技术报告中的对照模型,仅包含OpenAI公司的闭源模型OpenAI o1以及自家模型DeepSeek-v3。在前次DeepSeek-V3测试中被拿来做对照的 Meta、Anthropic等公司模型在本次报告中已销声匿迹。
在成本方面,DeepSeek-v3总计耗费了278.8万个GPU小时,使用2048 片辉达H800 GPU,耗时约两个月完成训练。相较之下,Meta公司的开源模型Llama 3.1-405B则耗费3080万个GPU小时,成本是DeepSeek-v3 的 11倍,甚至OpenAI公司的GPT-4o模型训练也耗资1亿美元,与 DeepSeek-V3的557万美元训练成本差距甚大。








问我止道
本来成本就没有那么高,都是制作组。公司中间人。圈钱的手段,557万美元都不是全部的研发费,还有各种各样的开销费用。真正研发一个这样的东西,前期通过信念理想鼓动年轻人熬夜,熬夜做出来的成本可能都不要100万美元。主要是一个数据导入。算推理软件是推荐,数据就是硬核,就是靠计算。前期这样的小团队靠青春,靠信念,靠理想支撑的话,员工成本是极低的,而不像那些公司给我搞的。同样的一个数据分析师或者工程师在美国的那些资本的圈钱的利益向他的年薪可能要拿几千万。但是在这个团队里面可能是加上人民币就够了。关键是看后续资本很多时候就是泡沫资本家的钱,他们为什么都说他们是吸人血的馒头?因为他们也被吸呀。资本的钱也被资本被人11倍的心,那资本家就要将这11倍放大到更大的倍数,从其他的人身上吸回来了。世界循环就是如此。
大牛
功到自然成,妙手偶得之
用户14xxx96
被老美那些所谓的精英吹的神户其神的东西贵的离谱,好像别人永这弄不出来,但就是人算不如天算,结果丑态百出
生活张建华
台积电总是孤芳自赏,牛批吃上了天,财富积累了那么多,只为了沤粪?这个时候哪去了,一点作为都没有。
大为
这么牛皮的世界骄傲技术成果,吓得主创研发人员提前跳槽逃跑到小米公司了,避免以后被发觉是骗子追究责任到自己!
Cl_Smoothcrew 回复 02-02 10:54
就一个女的,能掀起什么波浪,再说那个女的也是从阿里达摩院出来了,主心骨在创始人手上
大为 回复 Cl_Smoothcrew 02-02 11:14
这女的从来没说是世界骄傲技术成果,也是在吹嘘成骄傲成果以前离职到小米的,一个主创技术人员都吓得离职了,估计知道要当骗子吹成骄傲成果不愿意配合逃走的!懂了没?