deep seek深陷“蒸馏”舆论漩涡 deepseek 最近,美国白宫AI和加密货币事务负责人大卫·萨克斯(David Sacks)质疑DeepSeek使用了一种名为“蒸馏”的人工智能训练方法——即一个新的人工智能模型透过向一个现有模型提出数百万个问题,从中吸取其知识及模仿其推理过程,涉嫌“抄作业”,在西方舆论引起轩然大波。
美国《华尔街日报》报道指出,“蒸馏”技术已经被人工智能开发者使用多年,但从未取得像DeepSeek这样的成功。测试显示,DeepSeek创建的模型与OpenAI和谷歌的模型得分几乎一样高,而成本却远比竞争对手低。
DeepSeek真的是靠“蒸馏” OpenAI 的数据来实现“弯道超车”的吗?据美国彭博社周二(28日)引述知情人士报道,OpenAI和微软正在调查DeepSeek 是否以未经授权的方式, 获取了源自OpenAI技术的数据输出。去年秋季, 微软的安全研究人员观察到可能与DeepSeek有关联的个人,使用OpenAI应用程序编程接口(API)窃取了大量数据。OpenAI 还对英国《金融时报》表示,他们已看到了“蒸馏”的证据,尽管他们并未公开这些证据。
据日本媒体《日经亚洲》周四(30日)报道,蒸馏并非新技术,也不一定都具有争议性。自 2024 年以来,随着企业对于使用大型语言模型 (LLM) 的需求增加,蒸馏变得越来越受欢迎。日本一家 AI 初创公司的工程师表示,大型语言模型难以处理,这需要大量昂贵的图形处理单元 (GPU)。而蒸馏可大大缩短开发时间与成本,开发出比大型模型运行速度更快的模型。
报道指出,DeepSeek 的问题在于其低成本模型是否“更多地基于蒸馏而不是创新”。对此,Astris Advisory Japan 分析师 Kirk Boodry 说:“他们是否能够使用现有的大型语言模型来提炼他们的结果是一个问题。这似乎在讨论中出现了很多次。人们说,‘我不知道这其中有多少是真正前沿的。’”
Omdia 咨询总监 Kazuhiro Sugiyama 则指出,DeepSeek的影响只是“暂时且有限的”,业界仍需验证其持久性。分析师也怀疑DeepSeek的开发预算是否真的那么小。Boodry 说,当人们谈论 DeepSeek的开发时间和费用时,他们谈论的是这个非常具体的模型:“人们随意给出的数字可能太低了。”
不过,美国信息技术与创新基金会的人工智能问题专家霍丹·奥马尔(Hodan Omarr)以书面方式告诉媒体,DeepSeek 的确取得了一些值得认可的创新成就:“DeepSeek 的效率和性能源自多项创新的结合。其关键策略之一是混合专家 (MoE),即通过允许模型的不同部分专注于特定任务来降低训练成本。它还应用数据量化来显著缩小 AI参数,同时保持准确性。为了优化硬件性能,DeepSeek 将 GPU 工作负载划分到多个处理器上以加快计算速度,并采用 CPU 协调技术来高效管理大数据流。”
展望未来,《日经亚洲》引用专家Sugiyama的预测说,人工智能模型未来将逐渐“两极分化”,微软和谷歌等大公司将继续投资于更大、更强的模型用于其服务,而较小的公司则开发更小、更便宜而高效的模型,以适合有针对性市场。 另一位人工智能工程师也表示,缩小人工智能模型的规模是个大趋势:“随着时间的推移,将会有很多方法来实现这一点。”
过去一周,DeepSeek的出现被形容为中国向硅谷投下的一枚重型炸弹,令美国在人工智能领域的主导地位受到空前质疑。投资者一度抛售了一万亿美元的科技股,纳斯达克指数一度下跌超过3%。同时,在国内舆论界,DeepSeek引发热议,被视为中国AI能力超越美国的证据,之前美国遏制中国半导体与AI硬件设备的努力似乎付之东流。


![真服了这帮炒作的媒体……[捂脸哭][捂脸哭][捂脸哭]美国这次真是踢到了铁板,本想暴力](http://image.uczzd.cn/4342087259692479417.jpg?id=0)
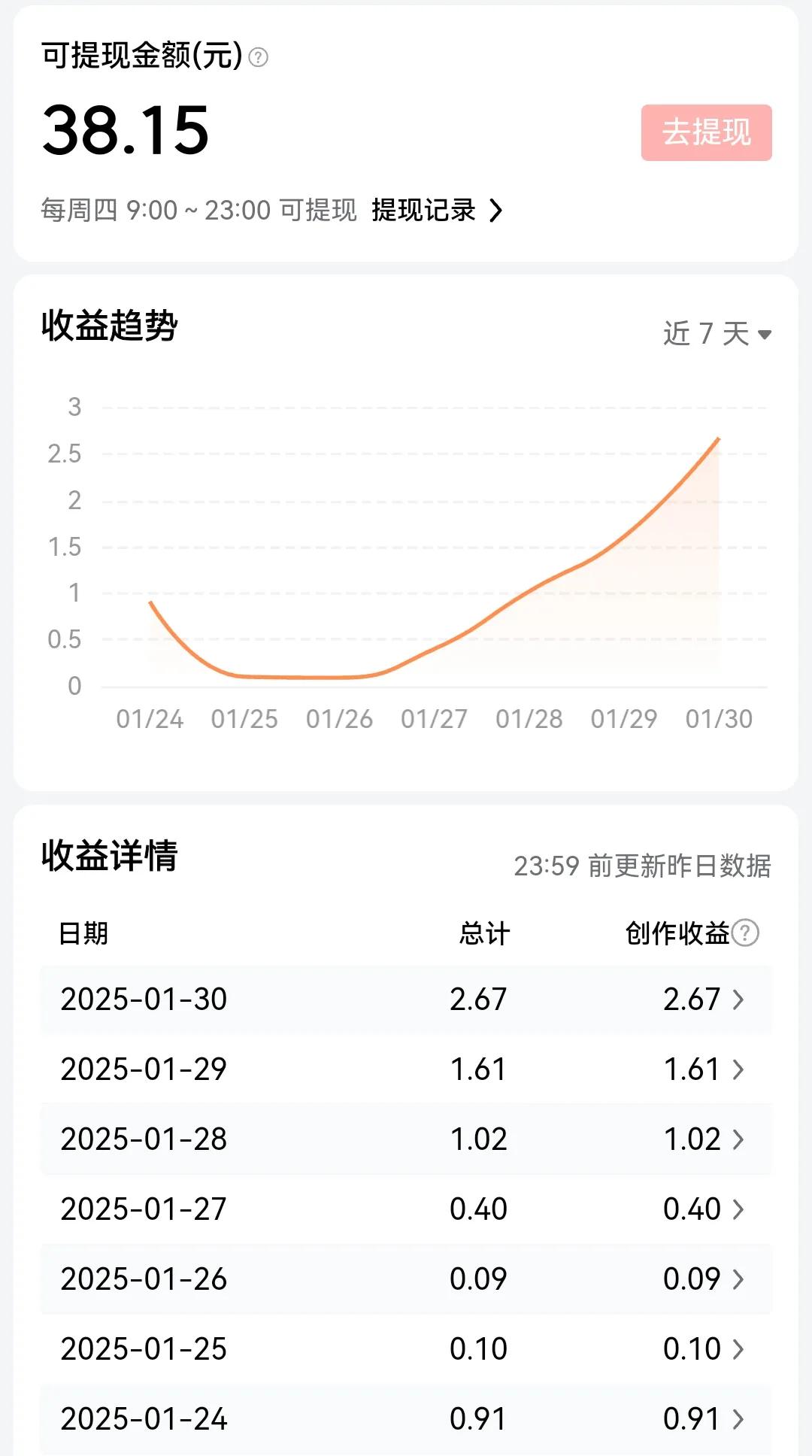






春之燕子
主要美帝股票跌多多就好了
我是你得不到的美男子
斯达克指数一度下跌超过3%,牛逼[点赞][点赞]
清茶与酒
开源的啊,重点是开源啊
望月怀远
自己蒸馏自己不更有优势吗?只能说明为了资本的利益,做着南辕北辙的事。
嫦娥姐姐
西边的恐怖分子天天想着祸害中国!!