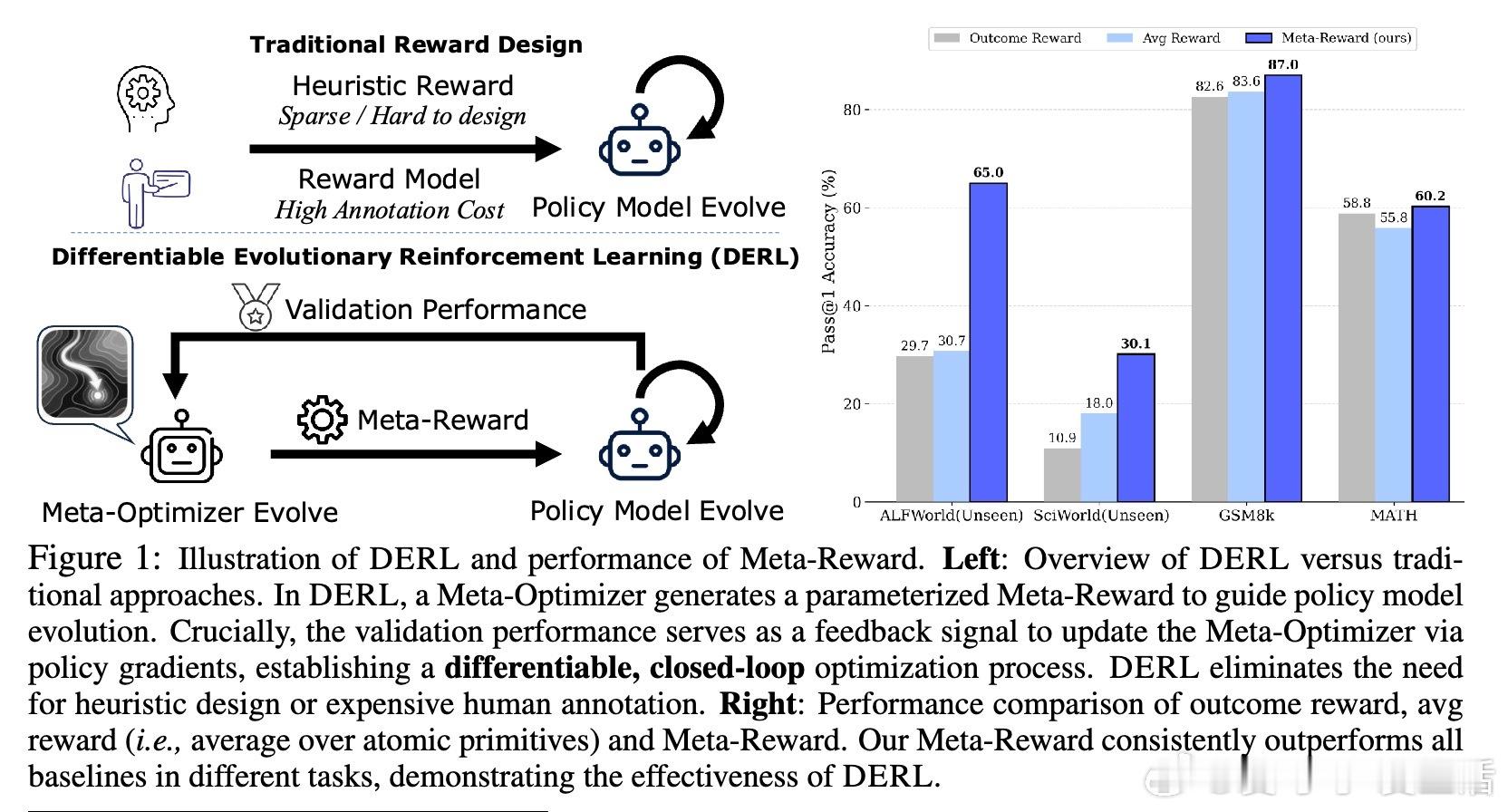
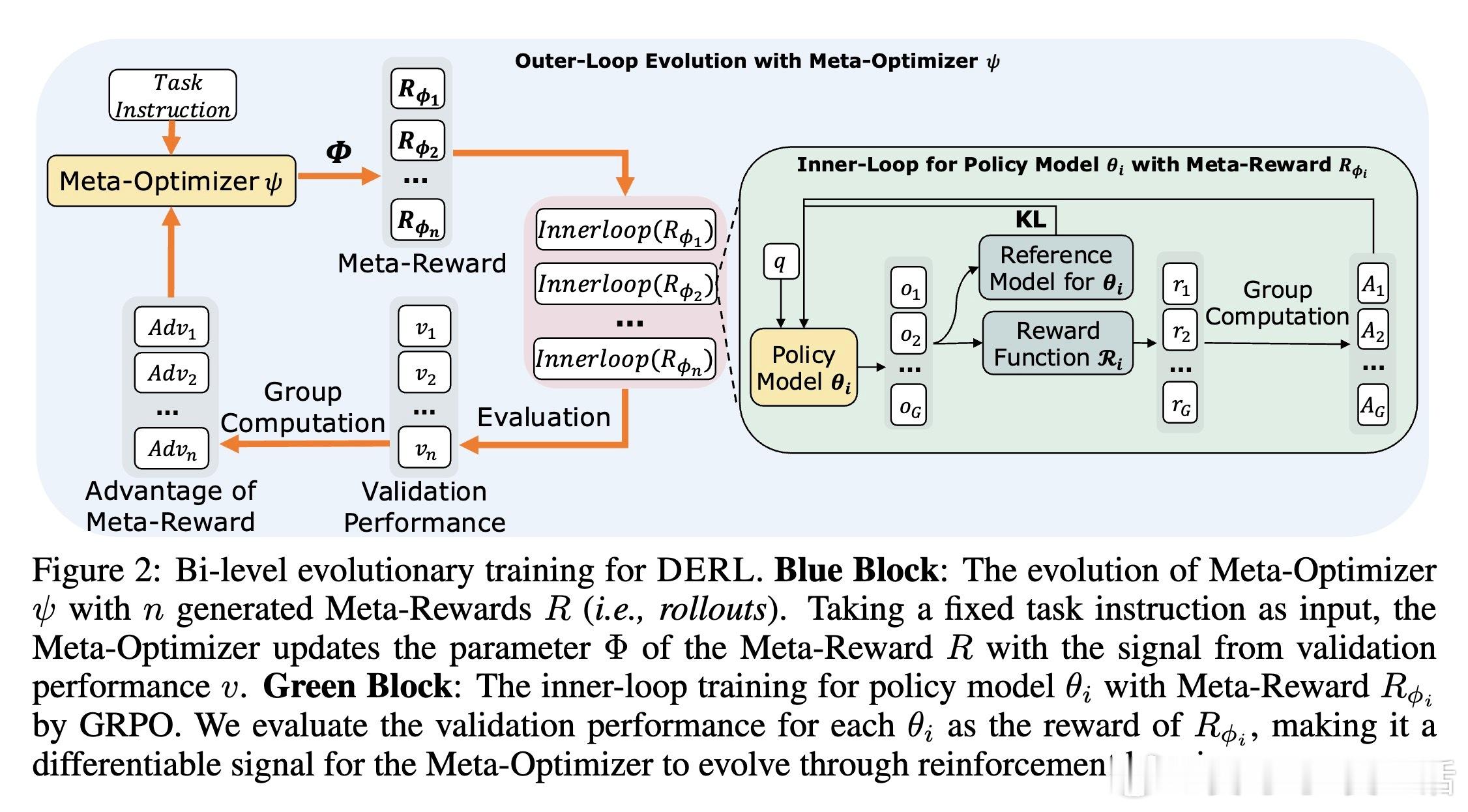
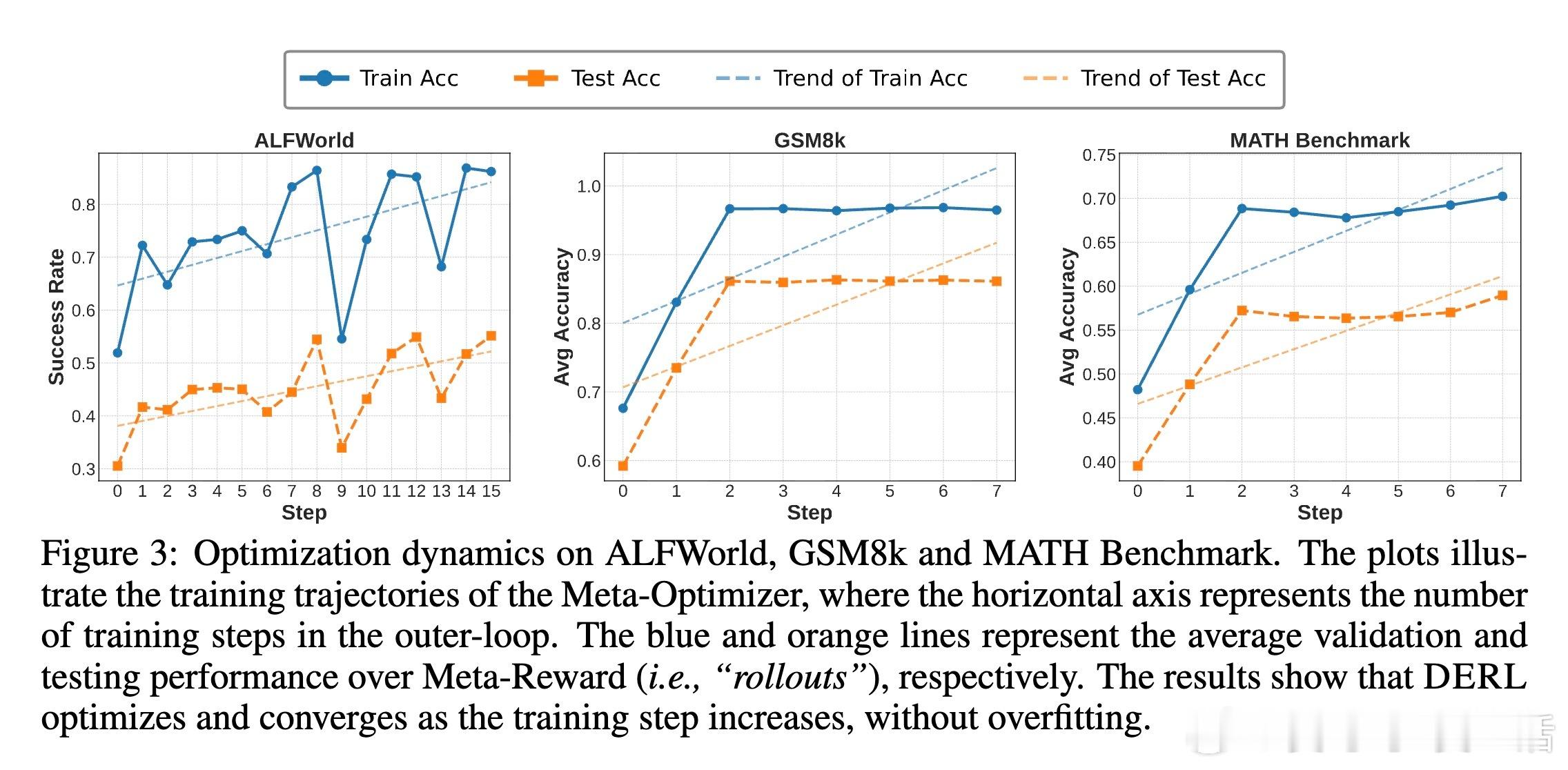
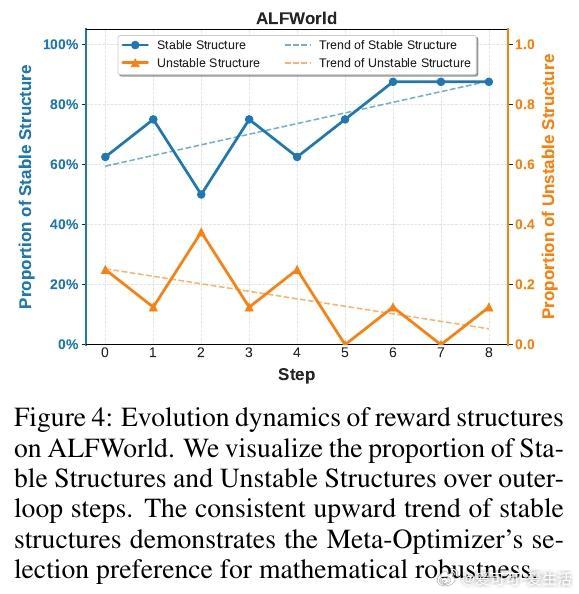
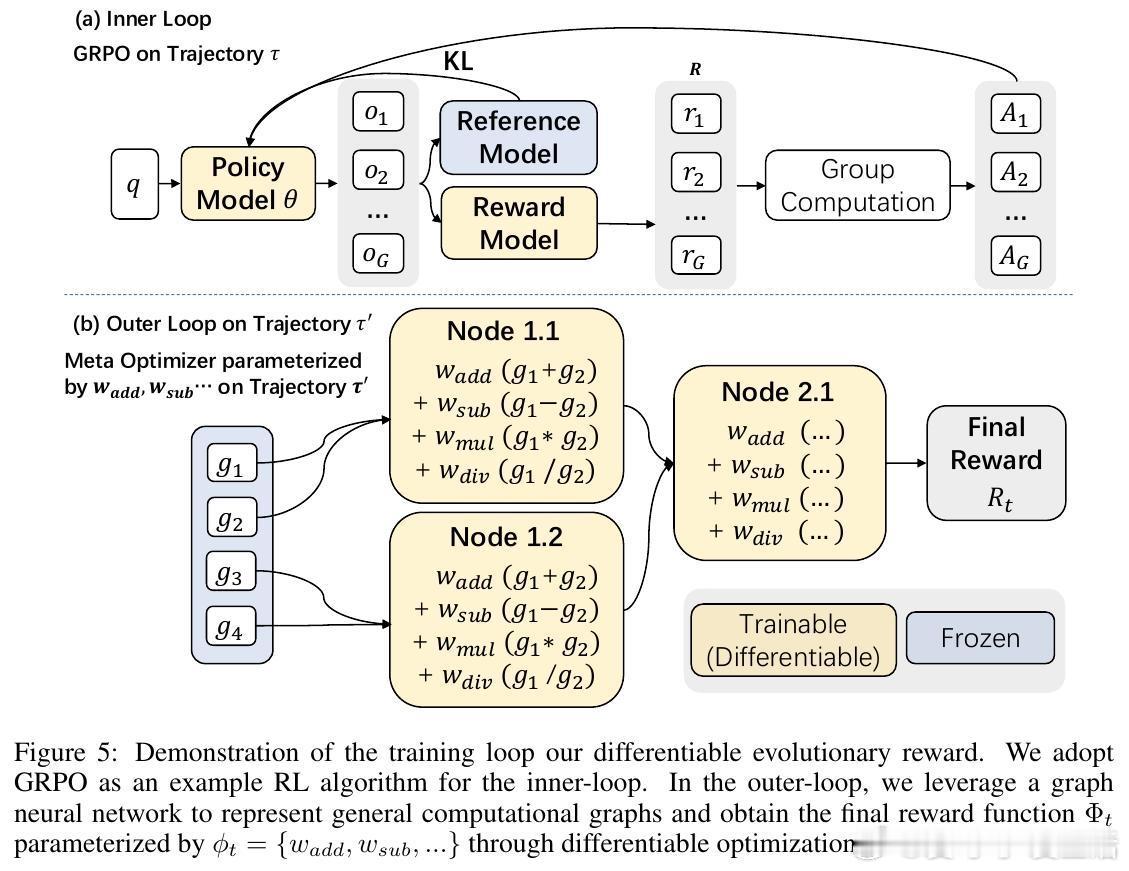
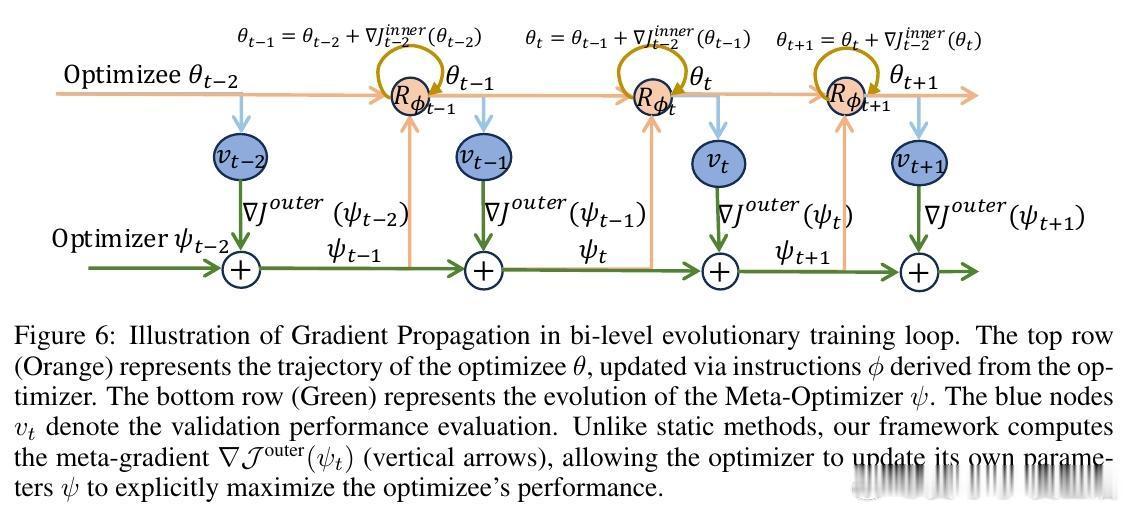
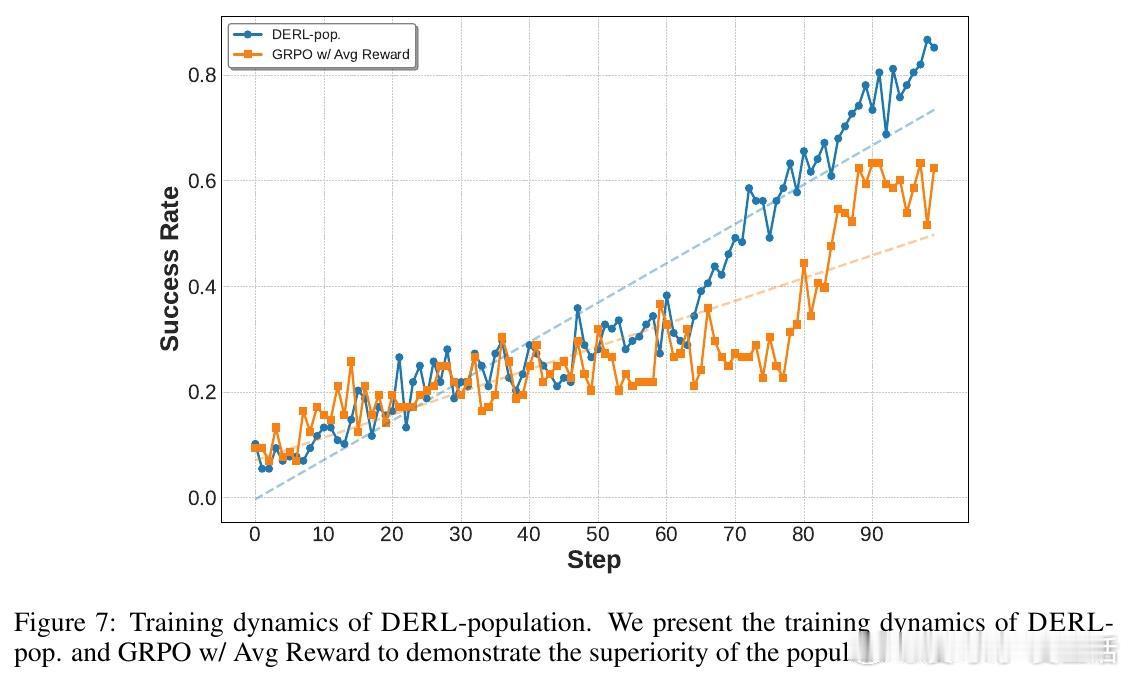
[AI]《Differentiable Evolutionary Reinforcement Learning》S Cheng, T Li, X Huang, X Yin... [University of Waterloo & The University of Hong Kong & The Chinese University of Hong Kong, Shenzhen] (2025) 在强化学习中,设计有效的奖励函数是智能体实现复杂推理任务的关键难题。传统自动优化奖励的方法通常依赖非微分的进化启发式,将奖励函数视为黑盒,难以捕捉奖励结构与任务表现之间的因果关系。为此,本文提出了“可微进化强化学习”(Differentiable Evolutionary Reinforcement Learning,DERL),通过双层优化框架实现奖励信号的自主发现。DERL由两个层次组成:内循环利用生成的“元奖励”训练策略模型,外循环则根据内循环策略的验证性能,用强化学习方法优化“元优化器”(Meta-Optimizer),使其逐步学习产生更密集、有效的反馈信号。不同于传统进化方法的盲目搜索,DERL通过可微分的元优化捕获“元梯度”,显著提升样本效率和优化效果。本文在机器人代理(ALFWorld)、科学模拟(ScienceWorld)和数学推理(GSM8k、MATH)三个多样化领域验证了DERL。实验结果显示,DERL在机器人和科学模拟任务上达到了最新的最优性能,特别是在数据分布外(O.O.D.)场景下展现出强大的鲁棒性,远超以启发式奖励为基础的方法。数学推理任务中,DERL突破了静态启发式奖励的局限,通过自动优化奖励结构获得更高的准确率。深入分析表明,DERL的元优化器能够自然筛选出数值稳定且结构合理的奖励组合,避免了不稳定或无效的奖励设计,体现了其自动发现任务内在结构的能力。本文还提出了基于原子原语(atomic primitives)的奖励参数化方式,这些模块化功能单元构成了奖励函数的结构化搜索空间,既保证了表达力,也降低了搜索复杂度。尽管DERL目前在计算资源上成本较高,且奖励表达依赖预定义的原子原语,未来可通过轻量级代理任务或高效元优化算法进一步提升效率,并拓展原语集合实现更广泛的任务适应性。此外,探索长时程的元监督信号也将有助于解决复杂任务中的信用分配难题。总结而言,DERL实现了从黑盒进化向可微分元优化的跨越,赋能强化学习奖励设计自动化与自提升,推动智能体在复杂推理领域的自主进化。详细内容和代码见:arxiv.org/abs/2512.13399 GitHub地址:网页链接




![高情商的人怎么处理[捂脸哭][捂脸哭][捂脸哭]](http://image.uczzd.cn/3512081917995301629.jpg?id=0)

