UQ平台:以未解之问为核心,重塑AI语言模型评测范式📊
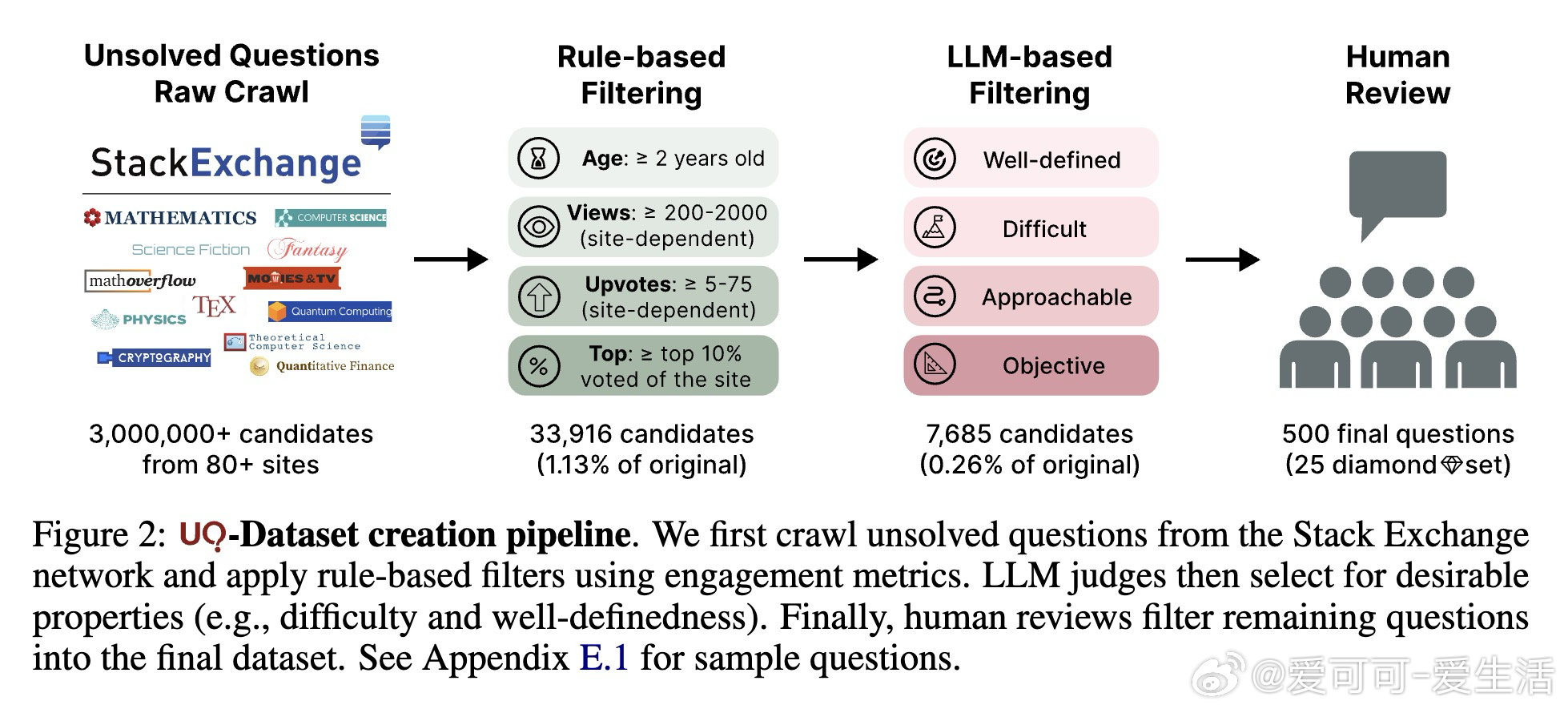
• 数据集规模:500道精心筛选的未解难题,涵盖数学、计算机科学理论、物理、生物声学、科幻、历史等80+领域,源自Stack Exchange,确保问题难度与现实需求高度契合。
• 筛选流程:结合基于规则的过滤、LLM智能判断(考察问题定义性、难度、可解性、客观性)与博士级人工审核,保证问题质量与挑战性。
• 验证策略:引入多层次UQ-Validator,利用生成器-验证器能力差距,结合循环一致性、事实逻辑检查、正确性判断及多轮反思迭代,辅以多数与全票投票机制,显著提升验证准确率和公平性。
• 评价平台:开放社区驱动的半动态平台(uq.stanford.edu),融合模型答案提交、验证结果展示、专家人审与讨论,实现持续演进的真实世界难题解答评估。
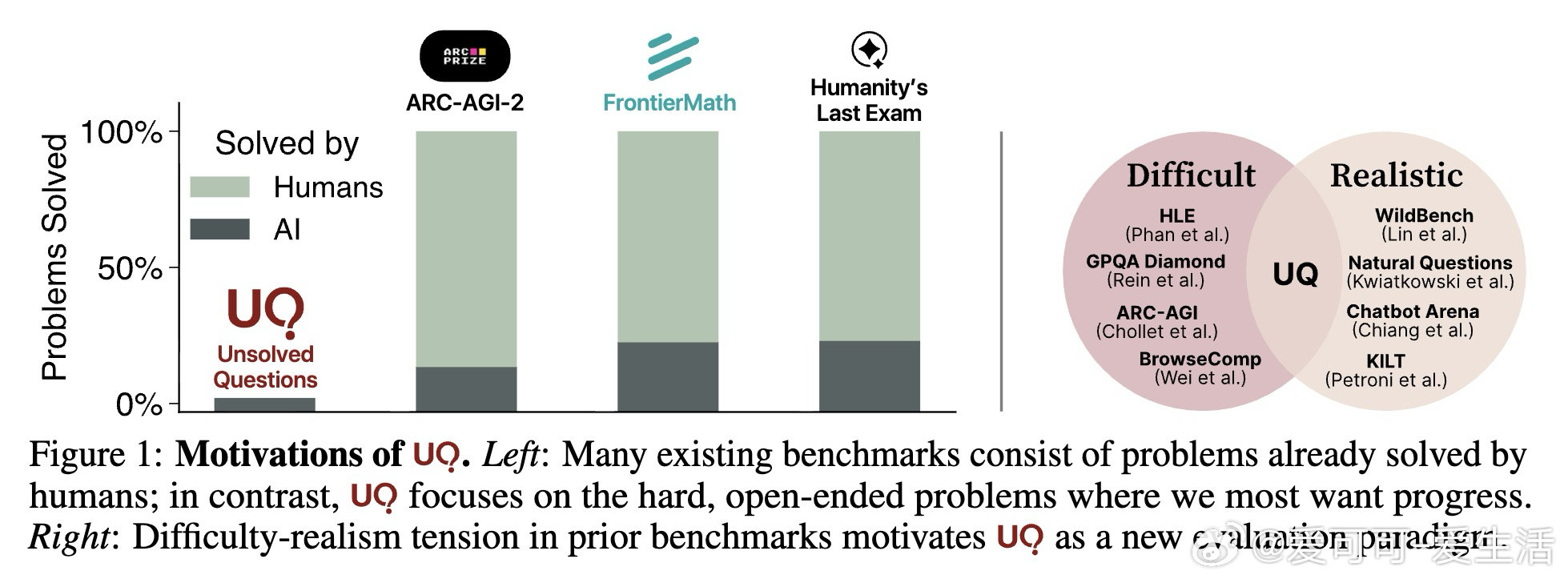
• 模型表现:当前顶尖模型仅在15%问题上通过自动验证,人工复核进一步揭示部分确凿解答,彰显未解问题的巨大挑战和潜在突破空间。
• 挑战与洞察:高精度验证仍面临“虚假正例”难题,评估结果存在模型自我偏见和评价不稳定性,提示需结合人工评审和多策略混合验证,推动可信AI评价体系建设。
心得:
1. 真实未解问题作为评价基准,天然兼顾难度与实用价值,避免传统考试题或用户频繁查询的局限,开辟AI评测新赛道。
2. 验证能力提升快于生成能力,验证器与生成器间的能力差距和跨任务迁移性为无监督质量评估提供坚实依据。
3. 社区参与和开放平台是破解未解问题评估难题的关键,有助于集体智慧促进模型持续进步与知识边界拓展。
论文详情🔗 arxiv.org/abs/2508.17580
深入了解👉 uq.stanford.edu
人工智能 语言模型 AI评测 未解之问 机器学习 社区驱动