[LG]《Language Models Coupled with Metacognition Can Outperform Reasoning Models》V Khandelwal, F Rossi, K Murugesan, E Miehling... [IBM Research] (2025)
大型语言模型(LLM)结合元认知机制,能在推理任务中超越专用推理模型(LRM)。核心亮点如下:
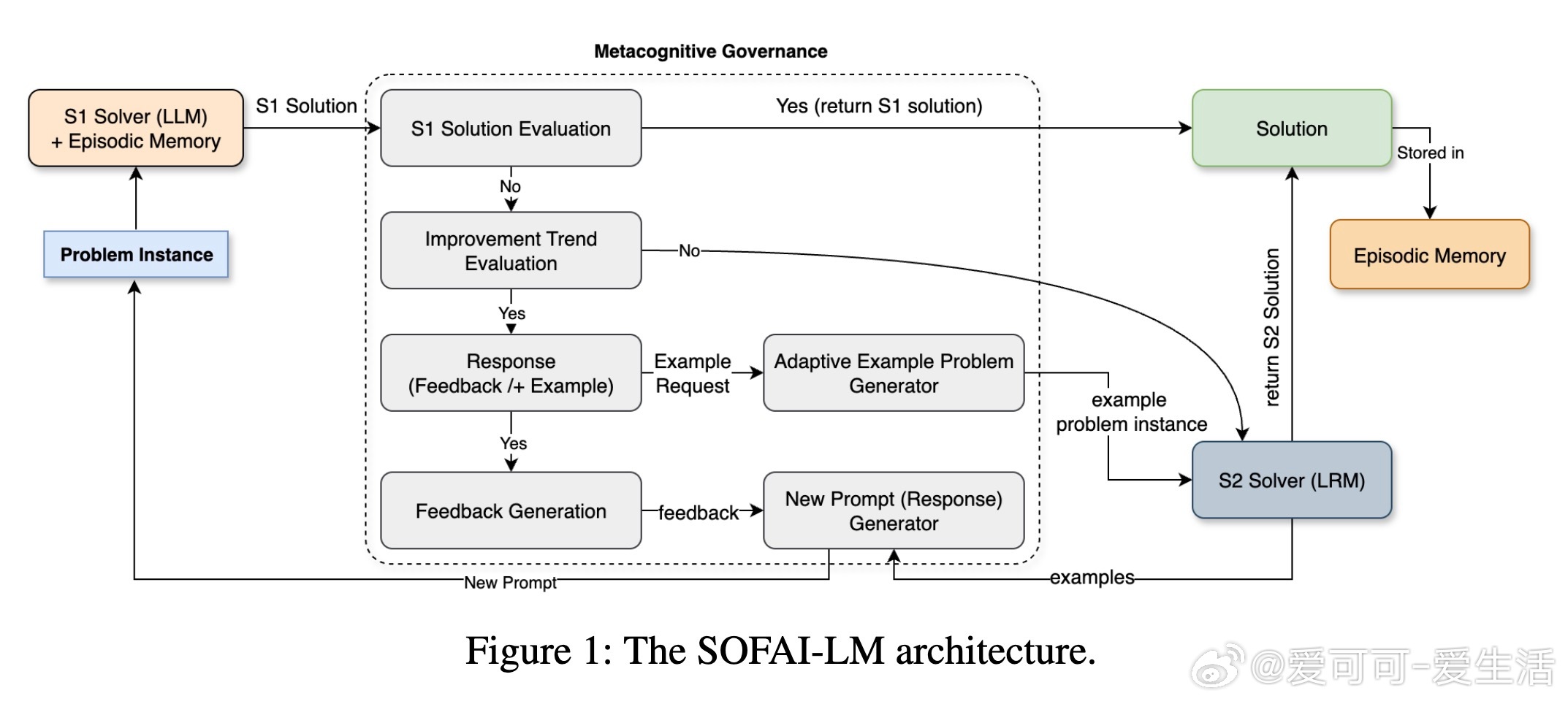
• SOFAI-LM架构创新地融合了快速但有时不严谨的LLM(系统1)与缓慢但逻辑严密的LRM(系统2),由元认知治理模块动态监控与反馈,促进LLM自我纠正,无需额外微调。
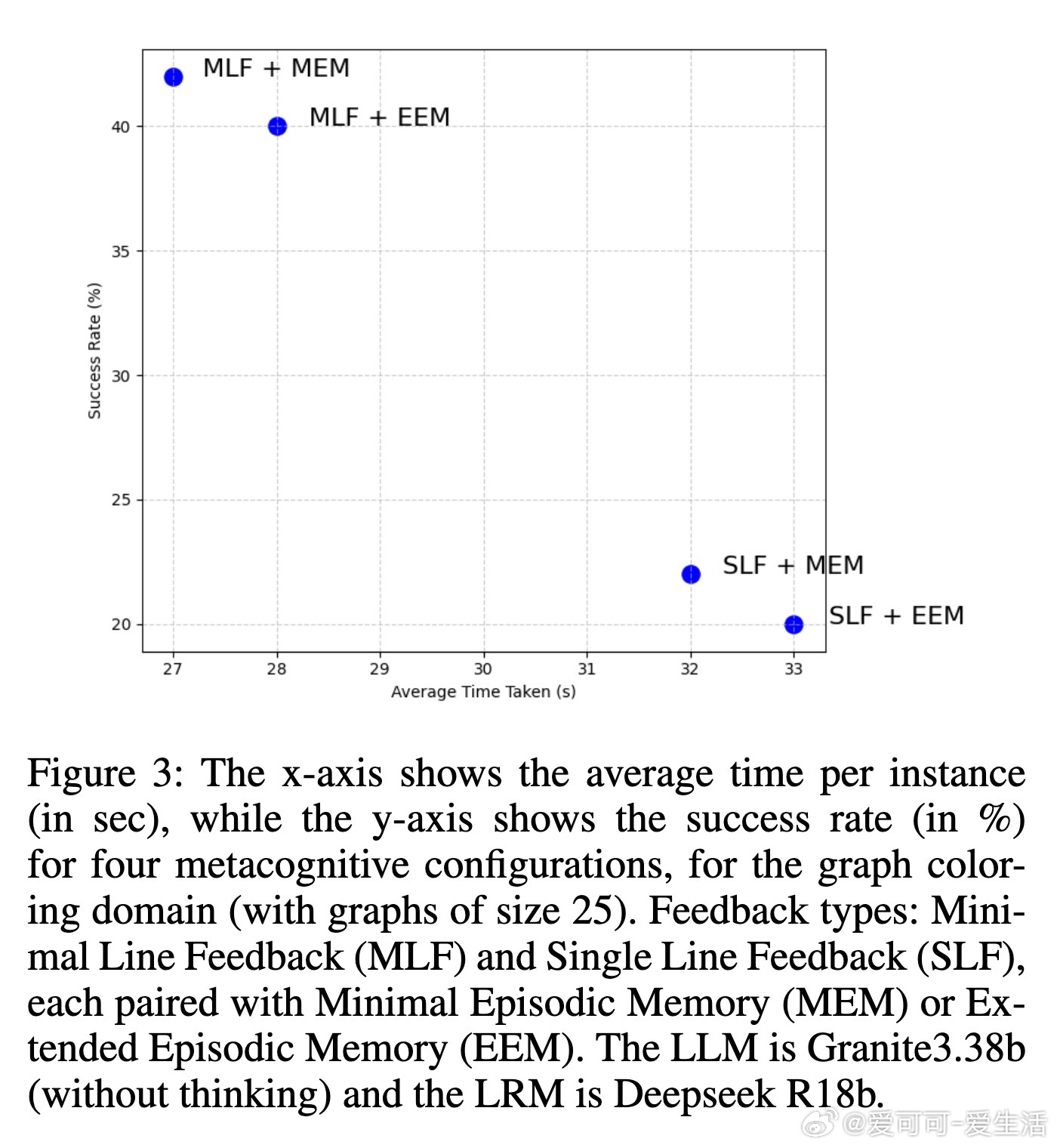
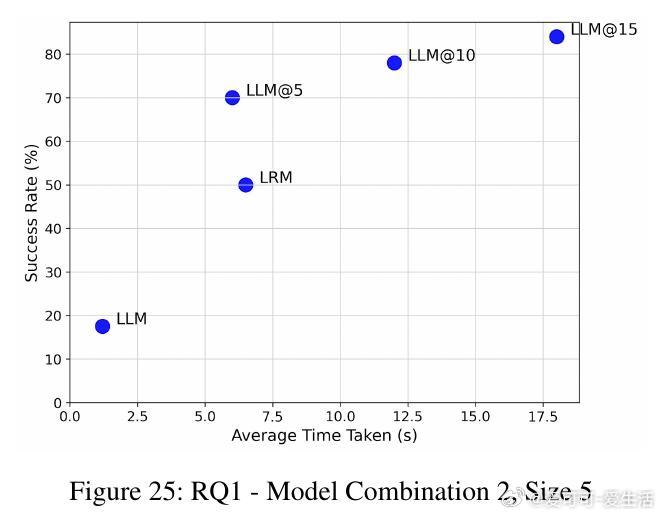
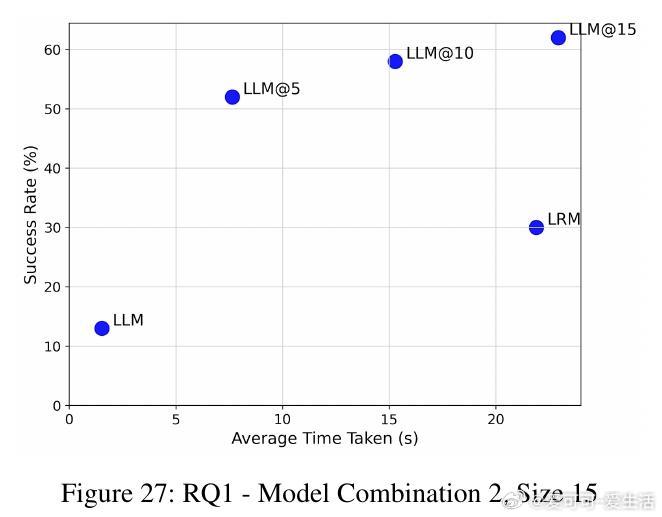
• 反馈形式分为多行(MLF)与单行(SLF),实验表明MLF结合简洁的最小情景记忆(MEM)效果最佳,既提高成功率又降低推理时间。
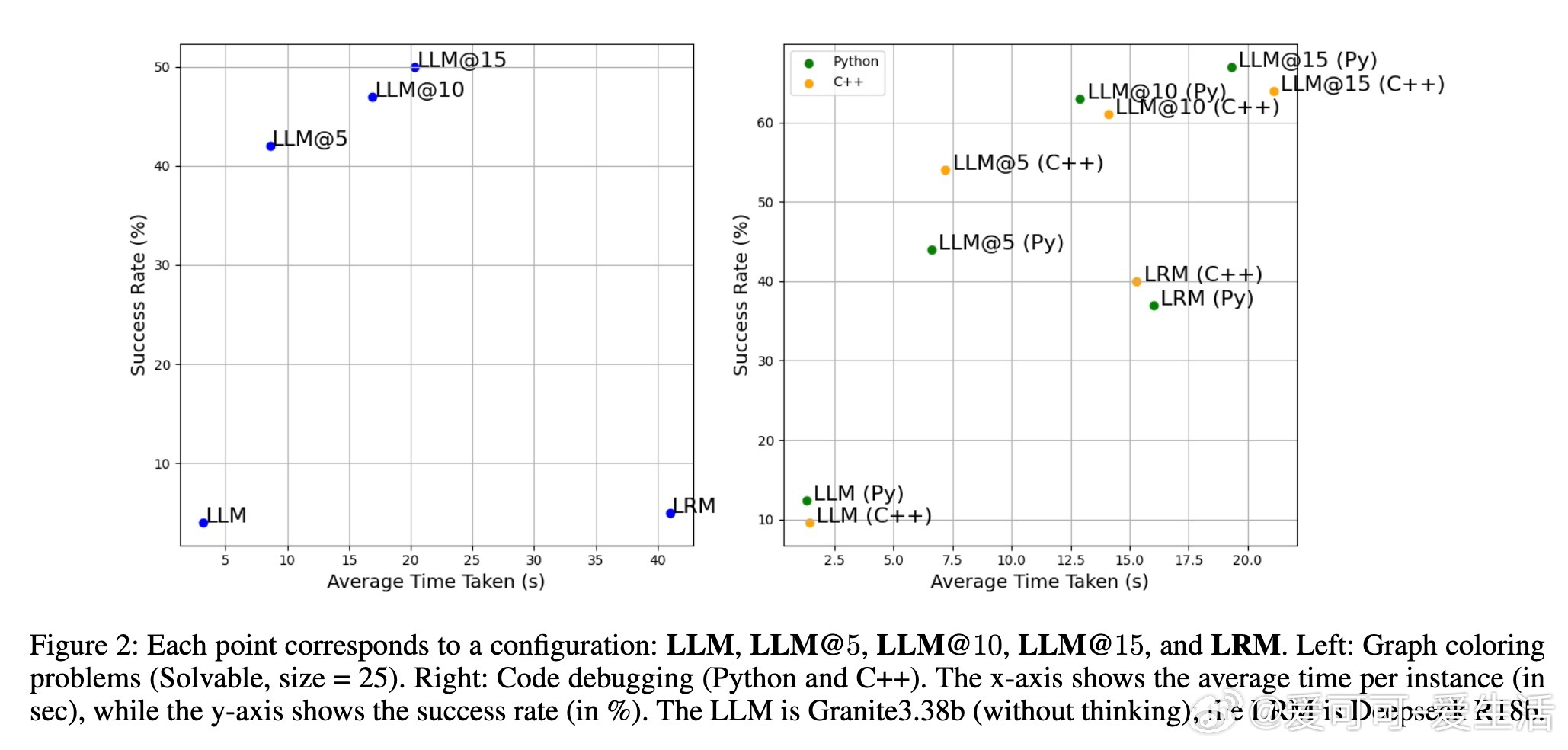
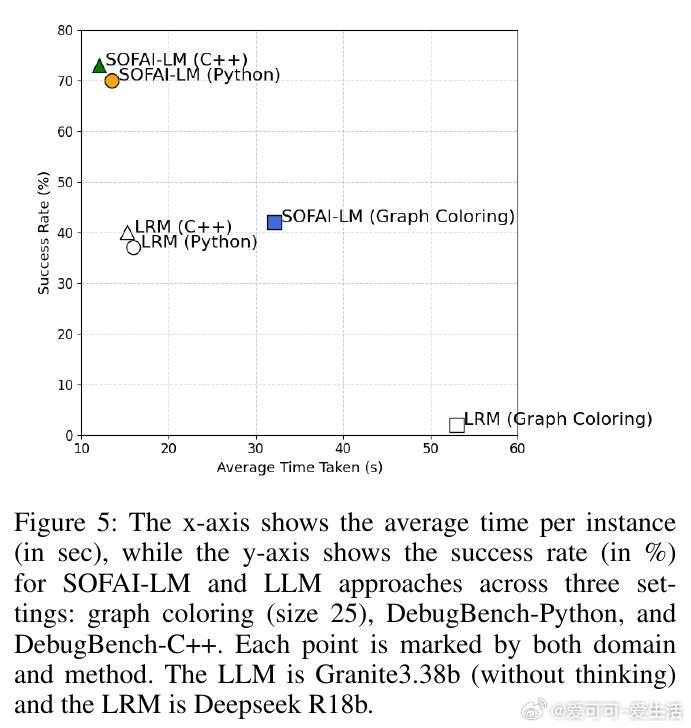
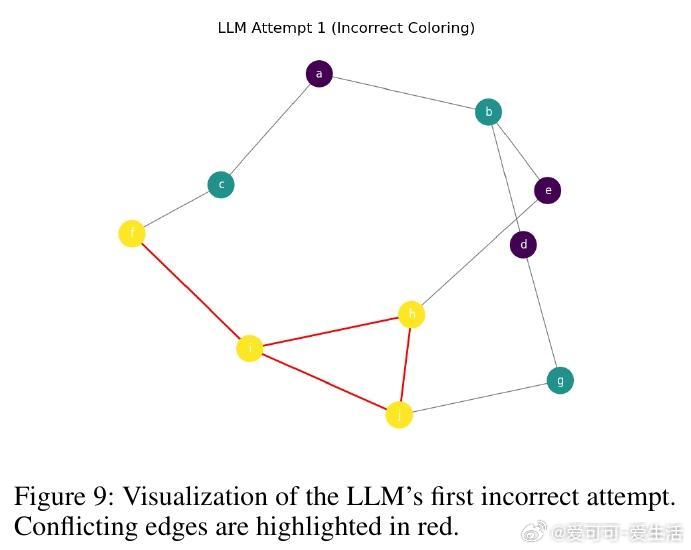
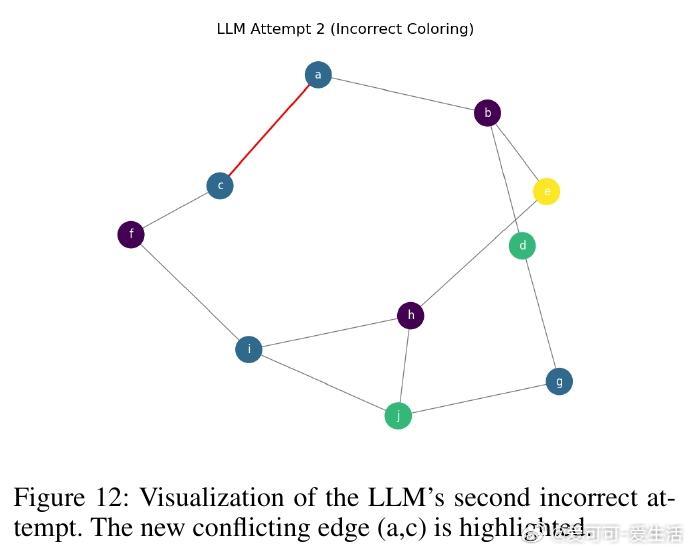
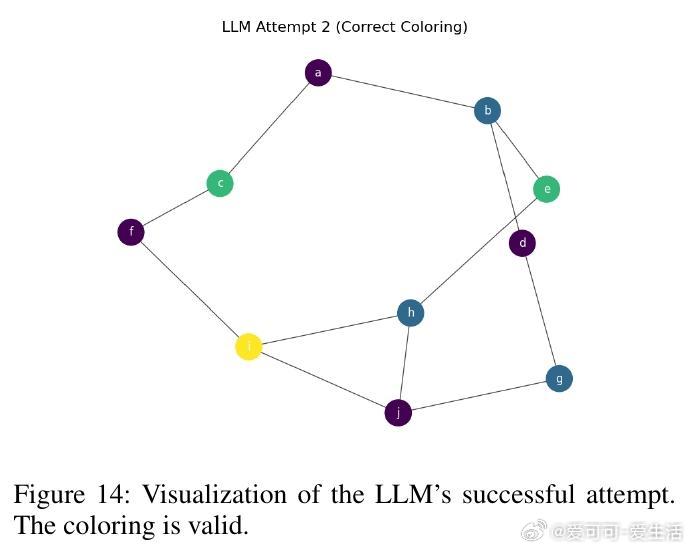
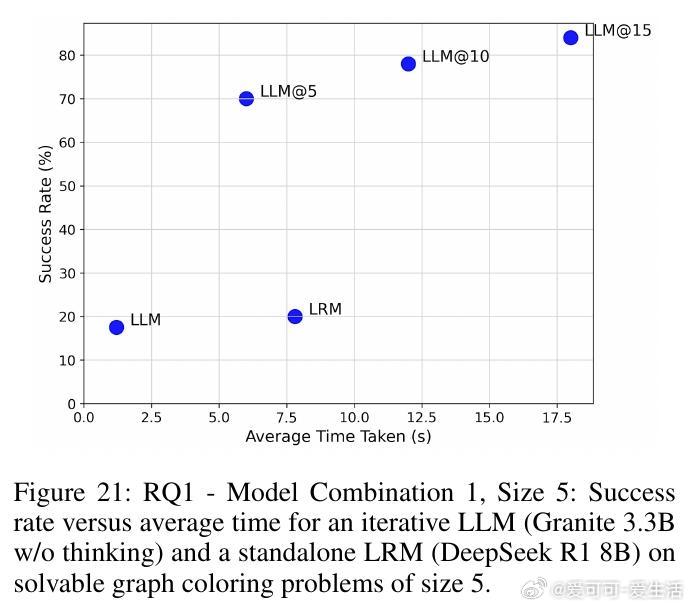
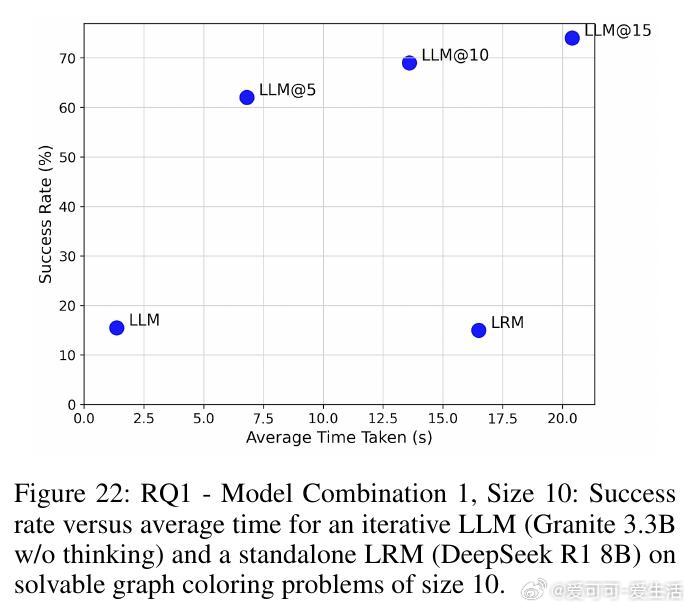
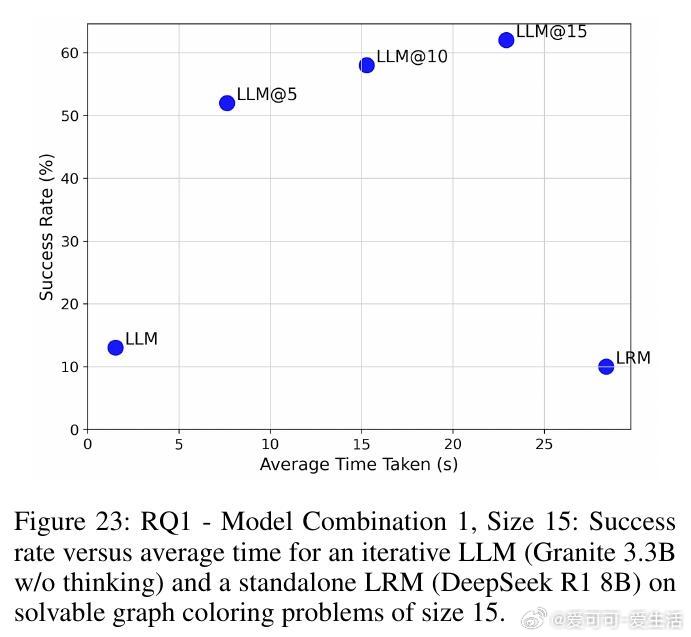
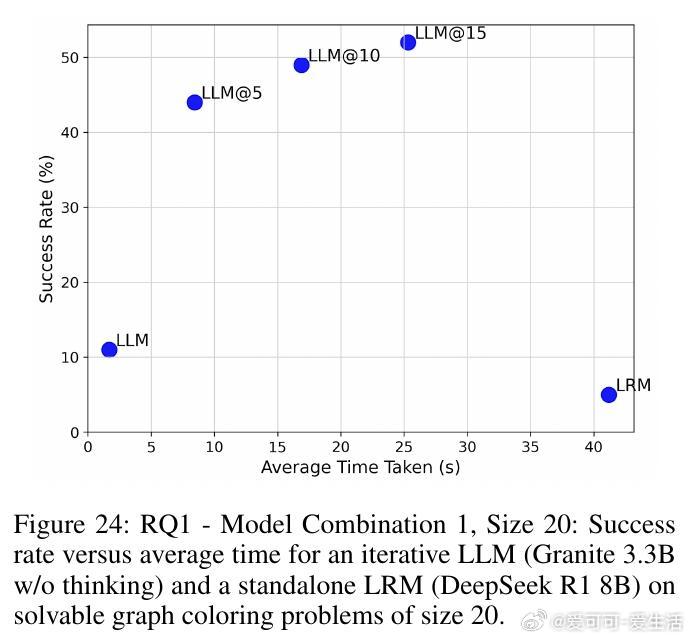
• 在图着色问题(需全局一致约束)与代码调试(局部修复)两个截然不同领域,SOFAI-LM均表现出色:通过迭代反馈,LLM的解题能力大幅提升,成功率远超单独LRM,同时推理时间显著缩短。
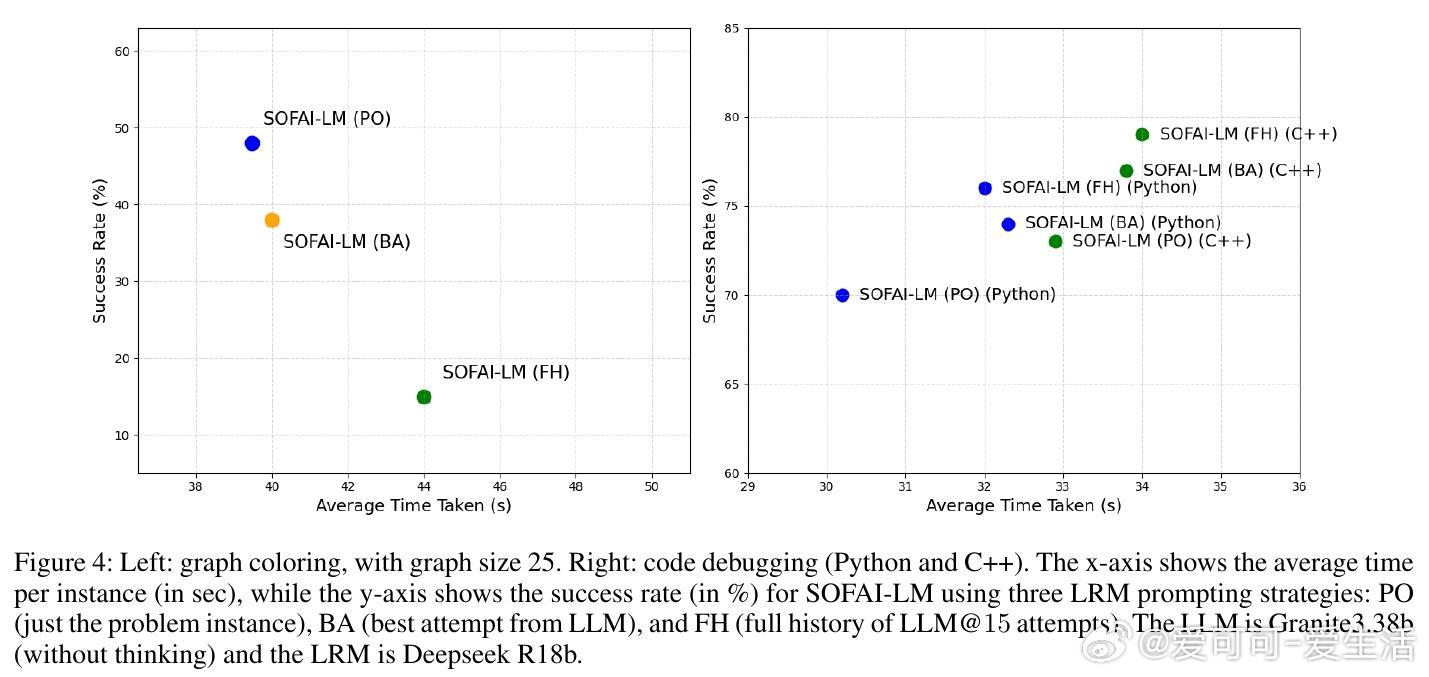
• 当LLM连续迭代未能收敛,元认知模块智能调用LRM,且针对图着色问题,单纯传递原始问题(Problem-Only,PO)给LRM效果最佳;而在代码调试中,传递包含历史尝试和反馈的上下文(Full History,FH)更有助于LRM高效解题。
• 实验涵盖多种模型组合(如Granite 3.3B、Llama 3.1、DeepSeek R1 8B、Qwen 2.5 Pro等),结果一致支持:迭代反馈驱动的LLM体系不仅能匹配甚至超越LRM的准确率,还能大幅提升计算效率。
• SOFAI-LM架构无需对LLM进行训练或微调,具备极强的模型通用性和领域适应性,提供了一种轻量且高效的“快思考+慢推理”协作范式。
这表明,将灵活快速的语言模型与严谨推理模型通过元认知反馈机制融合,是提升AI复杂推理任务表现的有效路径。未来,自动化元认知策略优化将进一步推动此类混合架构向通用、可扩展智能迈进。
详见👉 arxiv.org/abs/2508.17959
人工智能大语言模型元认知推理模型图着色代码调试神经符号