[LG]《Retrieval Capabilities of Large Language Models Scale with Pretraining FLOPs》J Portes, C Jennings, E J Yuen, S Doubov... [Databricks Mosaic Research] (2025)
大型语言模型(LLM)在信息检索任务中的表现与预训练计算量(FLOPs)密切相关。该研究通过对125M至7B参数规模的MPT解码器模型进行预训练,覆盖从10亿到2万亿以上的训练token,结合MS MARCO数据集的InfoNCE对比学习微调,系统评估了零样本BEIR检索基准的性能,得出以下关键发现:
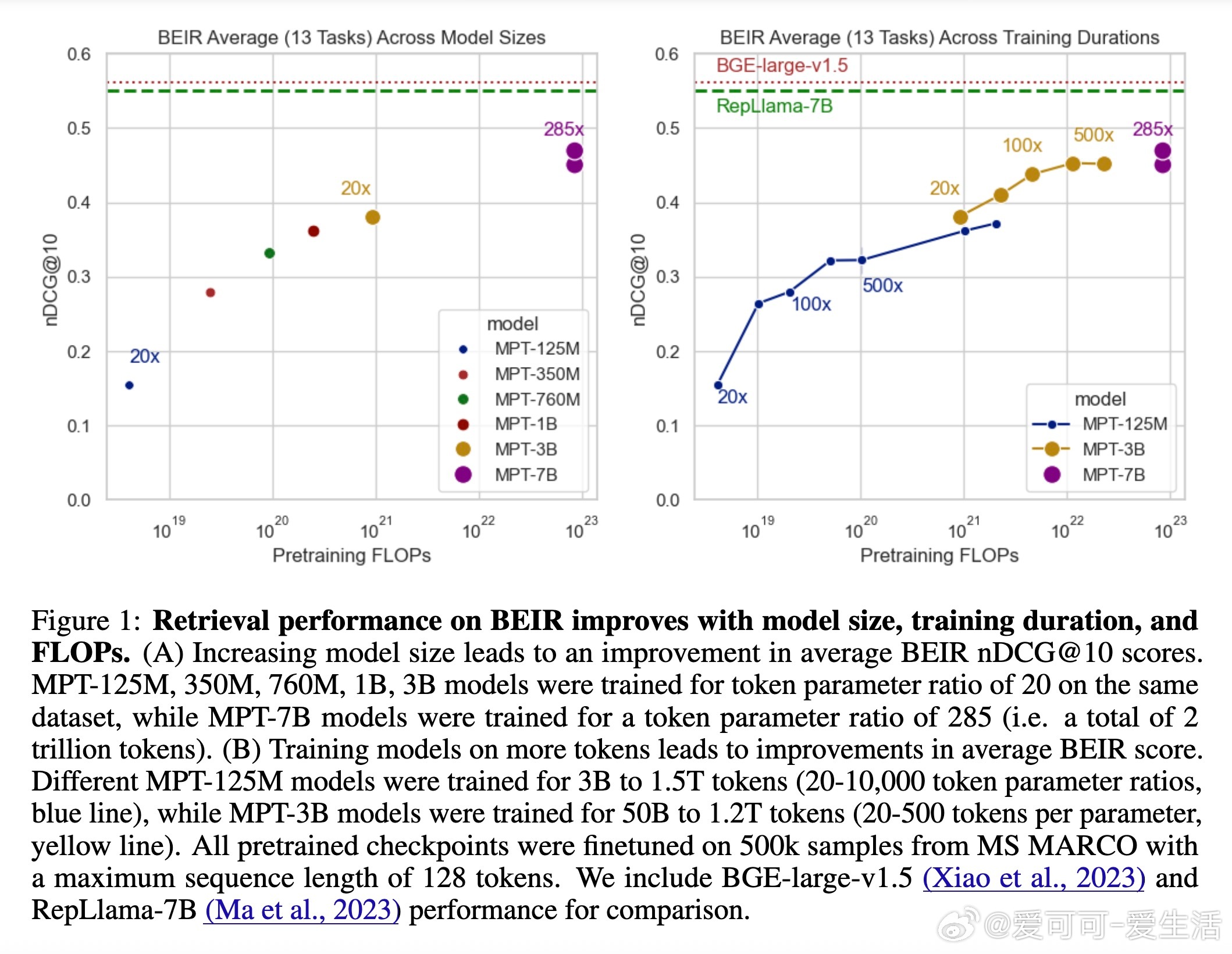
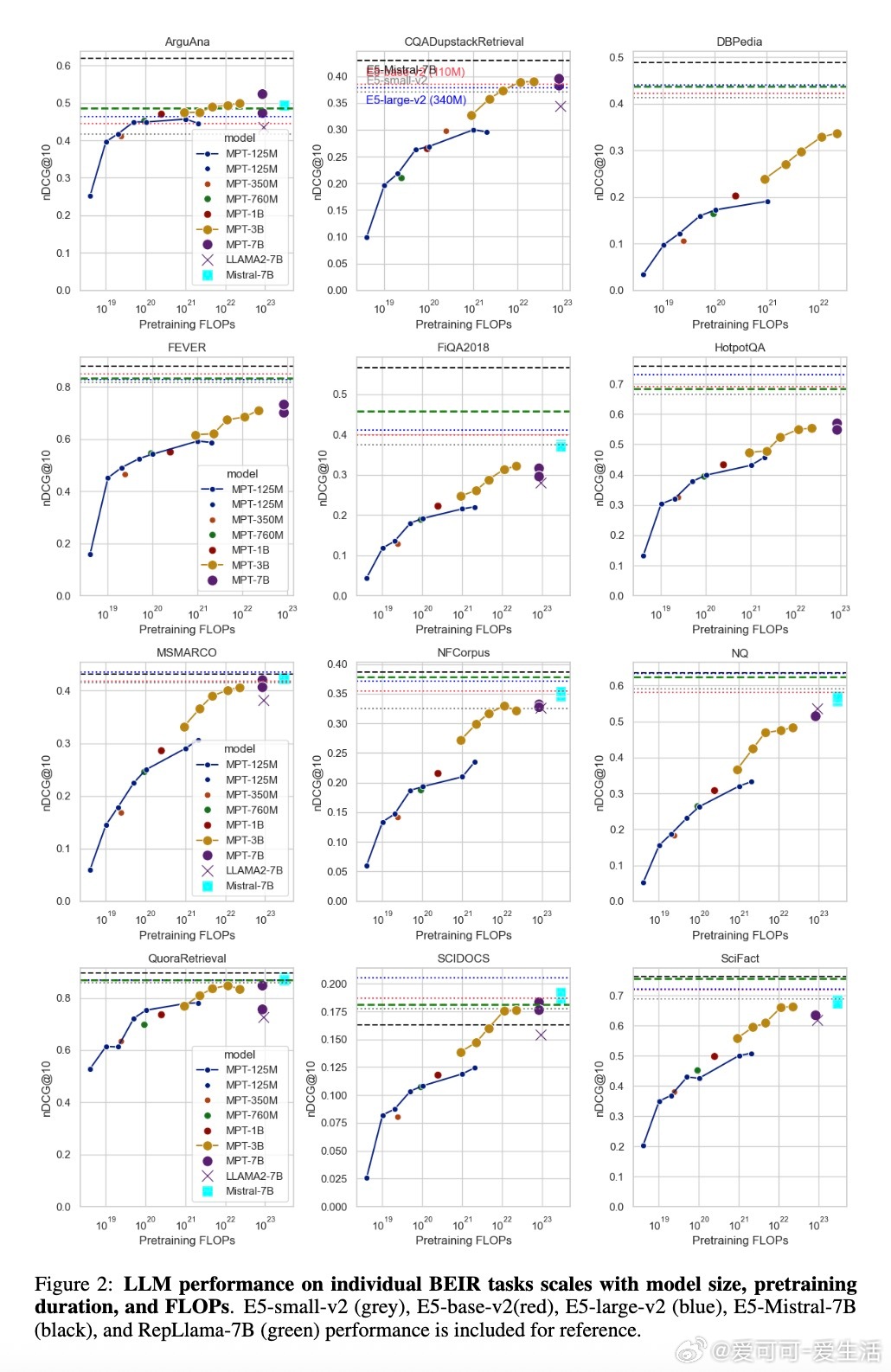
• 检索性能随模型规模和预训练时长线性提升,精确体现为与预训练FLOPs的正相关关系,表明计算资源投入是性能提升的核心驱动力。
• 小型模型通过增加预训练token数量(即更高token参数比)可达到甚至超越较大模型在较少训练数据下的表现,展示了训练数据规模对检索性能的巨大影响。
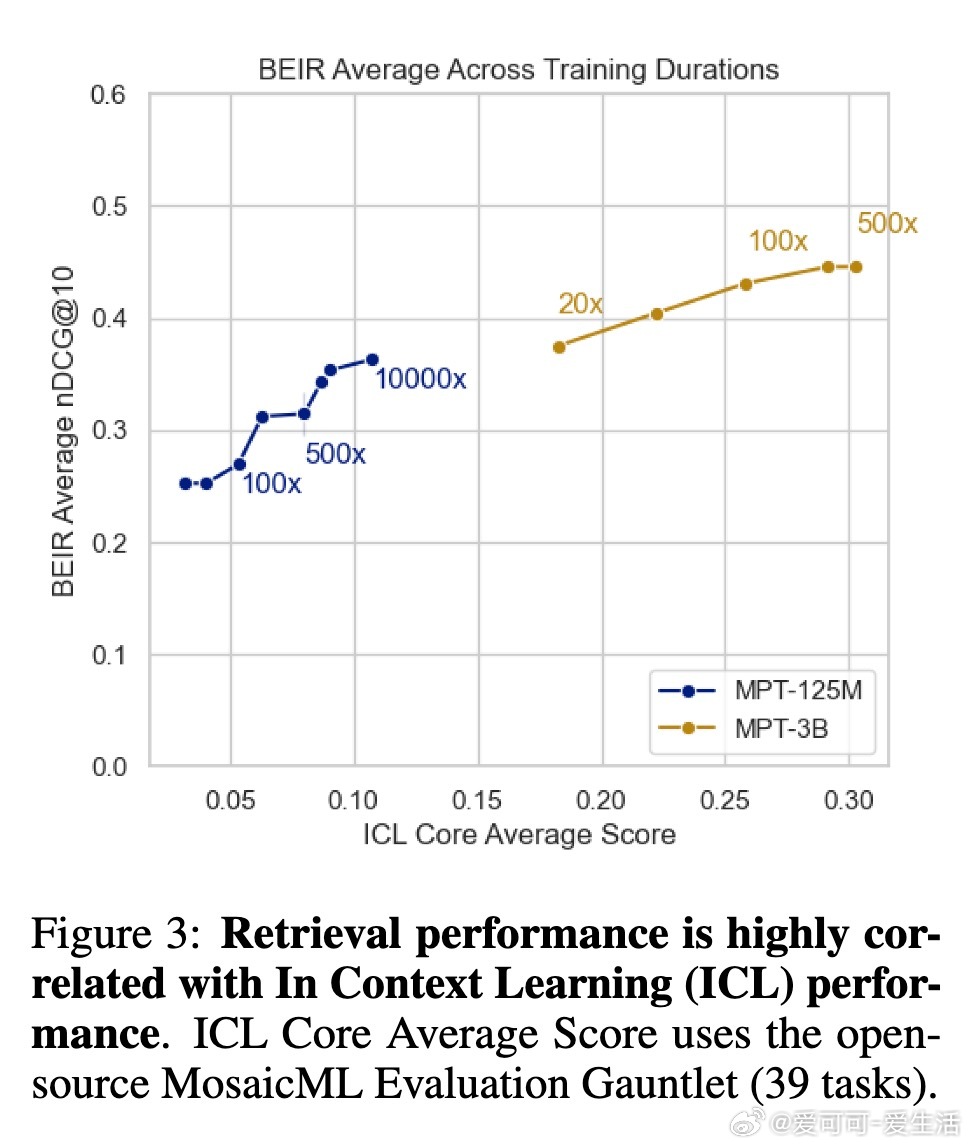
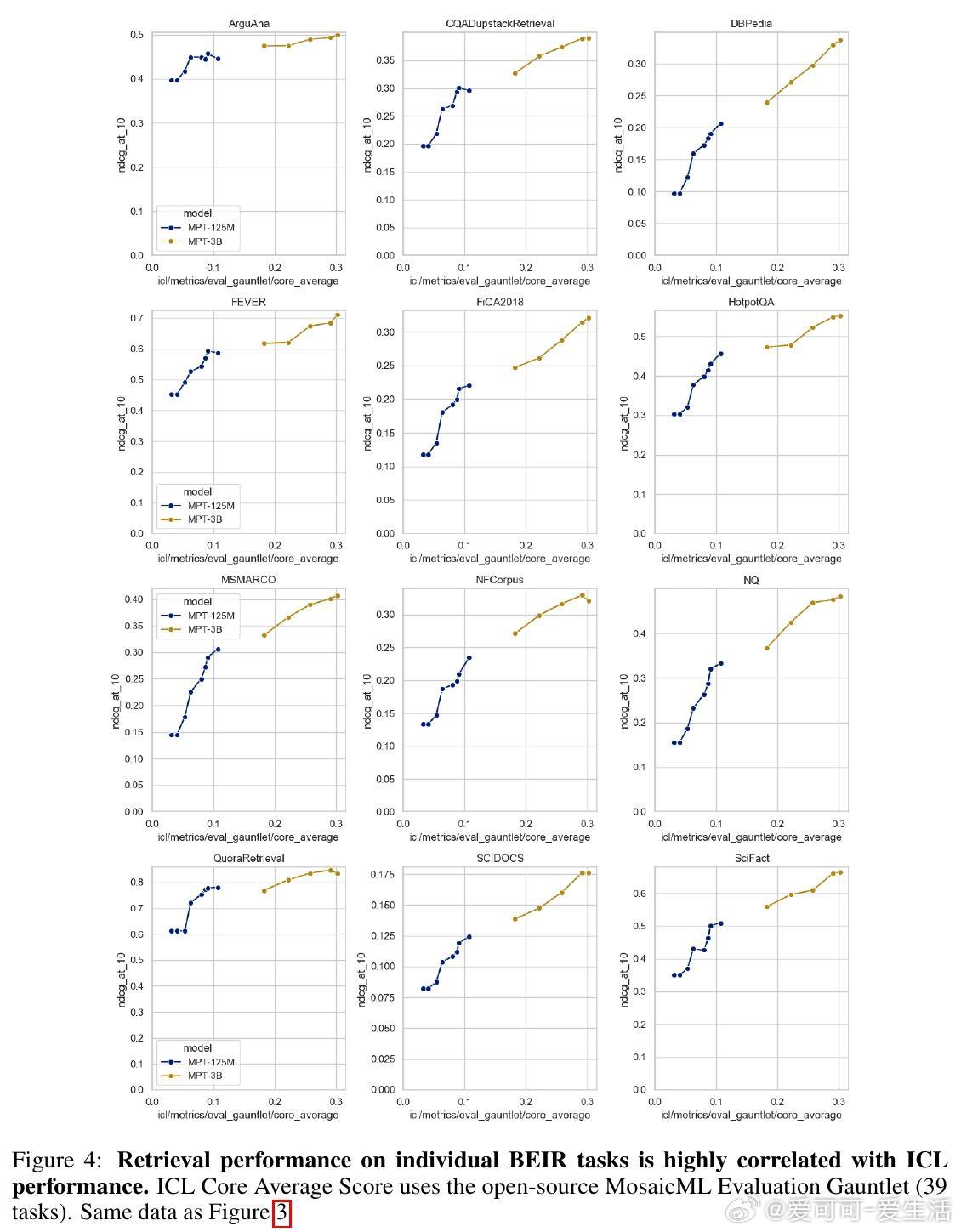
• 预训练模型的上下文学习(In-Context Learning, ICL)能力与检索性能高度相关,暗示两者可能共享基础表征学习机制。
• 该研究采用InfoNCE损失进行微调,利用MS MARCO数据中的硬负样本,有效提升了模型的判别能力。
• BEIR基准作为零样本多任务检索评测,涵盖多个复杂检索任务,研究中对部分特殊任务(如ArguAna反驳检索)发现性能瓶颈,提示指令微调可能是提升这类任务表现的关键。
• 研究证实,当前主流7B级别解码器模型(如Llama 2 7B,Mistral 7B)因其庞大的预训练数据量和强大的上下文处理能力,已成为开源检索嵌入模型的新标准。
• 本研究强调了传统基于BERT的编码器模型在检索领域的逐渐式微,未来趋势倾向于大规模解码器模型的嵌入应用。
• 目前模型微调在序列长度(128 tokens)和超参数统一设置上存在限制,实际检索性能有较大提升空间,提示未来通过更长序列和多样化微调数据可进一步突破。
该成果为理解LLM检索能力的规模效应和训练策略提供了系统量化依据,指导检索模型设计和资源分配优化。详情见👉 arxiv.org/abs/2508.17400
大型语言模型信息检索检索嵌入预训练规模对比学习BEIR基准