[LG]《On the Edge of Memorization in Diffusion Models》S Buchanan, D Pai, Y Ma, V D Bortoli [TTIC & UC Berkeley] (2025)
扩展理解扩散模型中的记忆与泛化边界,助力版权与隐私风险管控
• 本文建立了“记忆/泛化实验室”框架,以高维高斯混合模型为数据基础,数学刻画扩散模型记忆训练数据与生成新颖样本的临界机制。
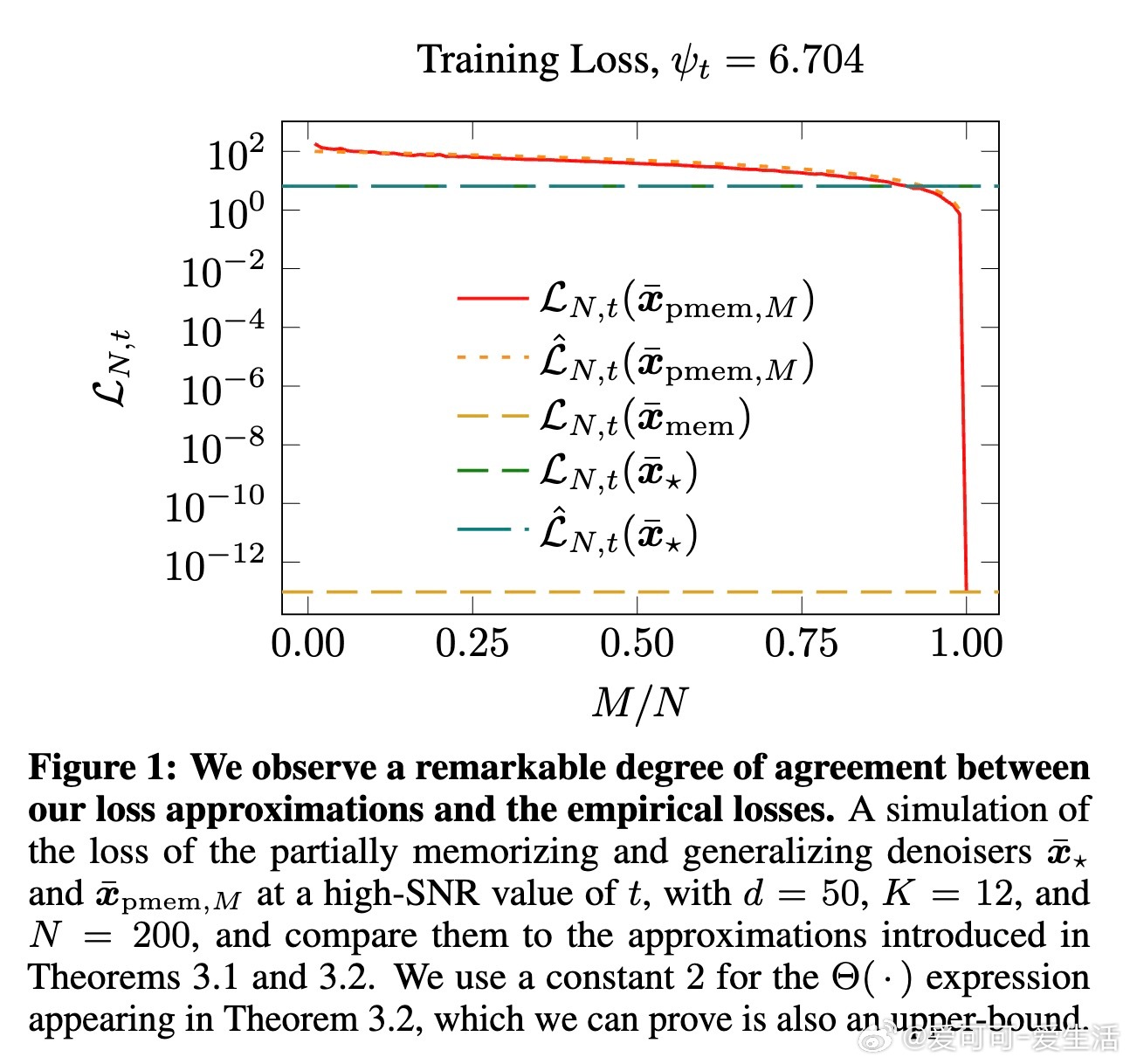
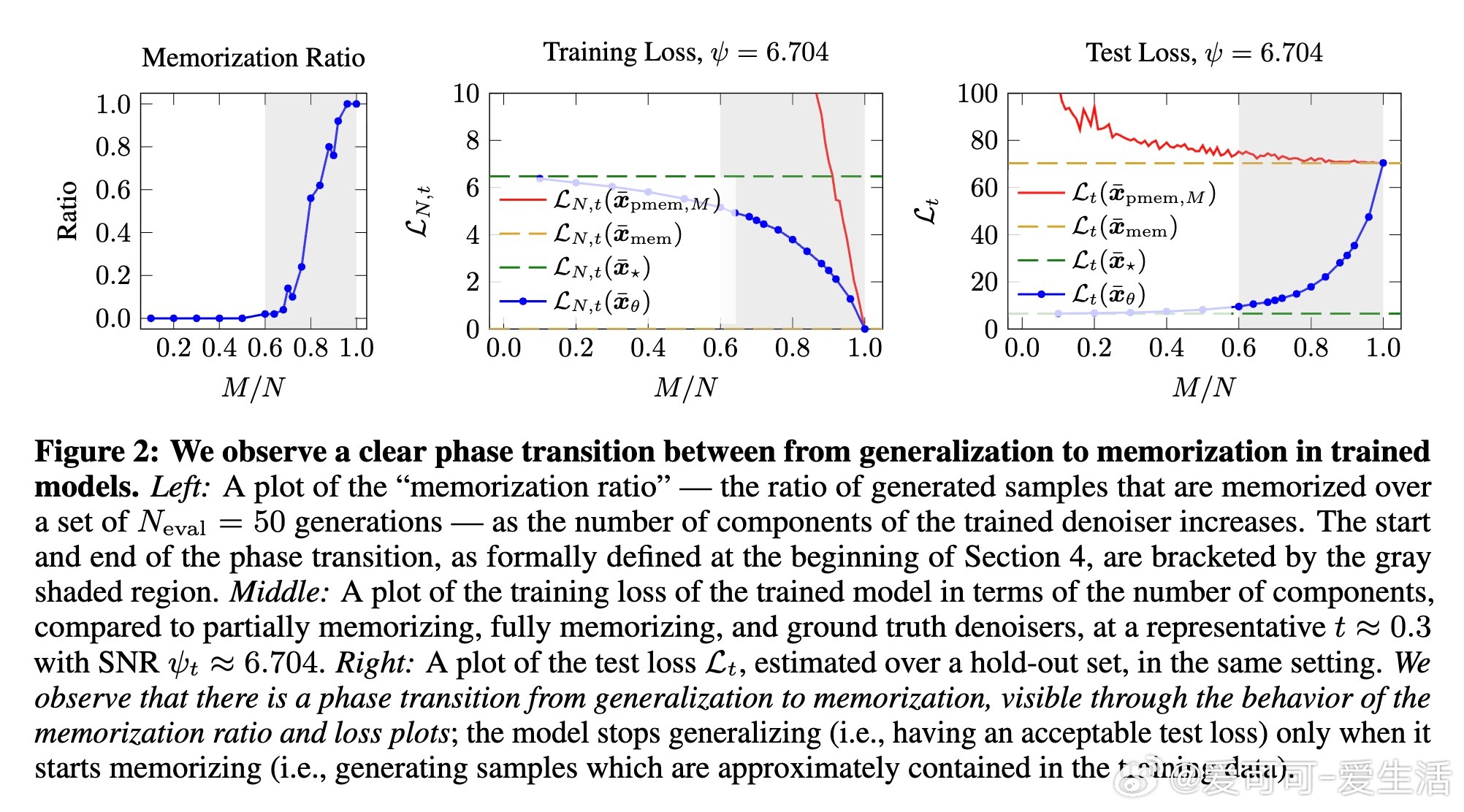
• 提出关键假设:模型是记忆还是泛化,取决于训练损失在“部分记忆模型”与“理想泛化模型”之间的差异,发现参数化程度存在“交叉点”决定相变。
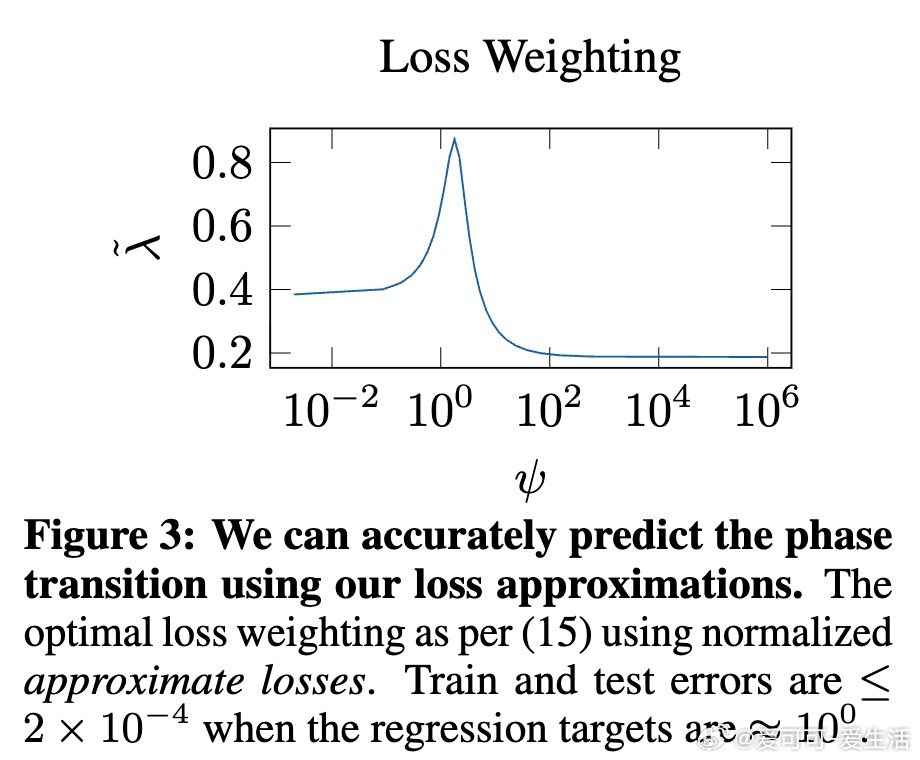
• 理论上准确预估该交叉点随样本数量线性增长,实验中验证了扩散模型在训练参数规模变化时从泛化到记忆的相变行为。
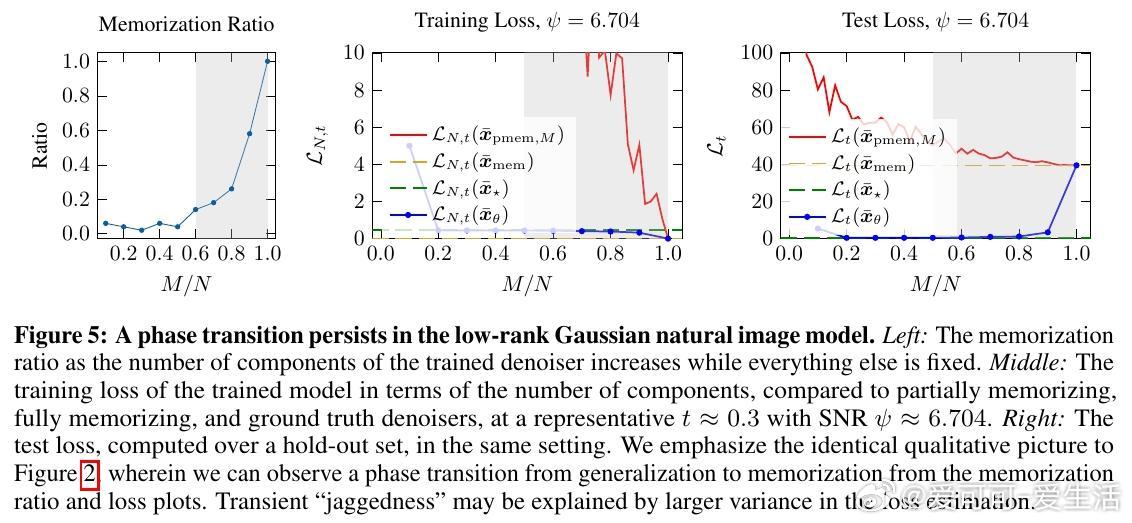
• 研究涵盖标准各向同性高斯混合及近似自然图像的低秩高斯混合,均表现出定性一致的记忆-泛化相变,支持模型泛用性。
• 论文提供了详细的训练损失近似式与概率界,揭示扩散模型训练中记忆行为非简单过拟合,区别于传统的“双下降”现象,强调唯一最优记忆模型的特殊性。
• 开源实验代码助力社区复现与扩展:
• 本框架为未来探索更复杂高维数据、内在维数及部分数据复用情况下的记忆与泛化提供了理论与实验基础,具有重要的长期参考价值和实践指导意义。
🔍 深入解析扩散模型的记忆边界,助力理解生成模型的法律风险与技术本质,推动AI伦理与安全发展。
了解详情🔗 arxiv.org/abs/2508.17689
人工智能扩散模型机器学习理论生成模型数据隐私版权保护