[LG]《TreePO: Bridging the Gap of Policy Optimization and Efficacy and Inference Efficiency with Heuristic Tree-based Modeling》Y Li, Q Gu, Z Wen, Z Li... [ByteDance Seed] (2025)
TreePO:一种创新的基于树的策略优化训练框架,显著提升大型语言模型在复杂推理任务中的训练稳定性与推理效率。
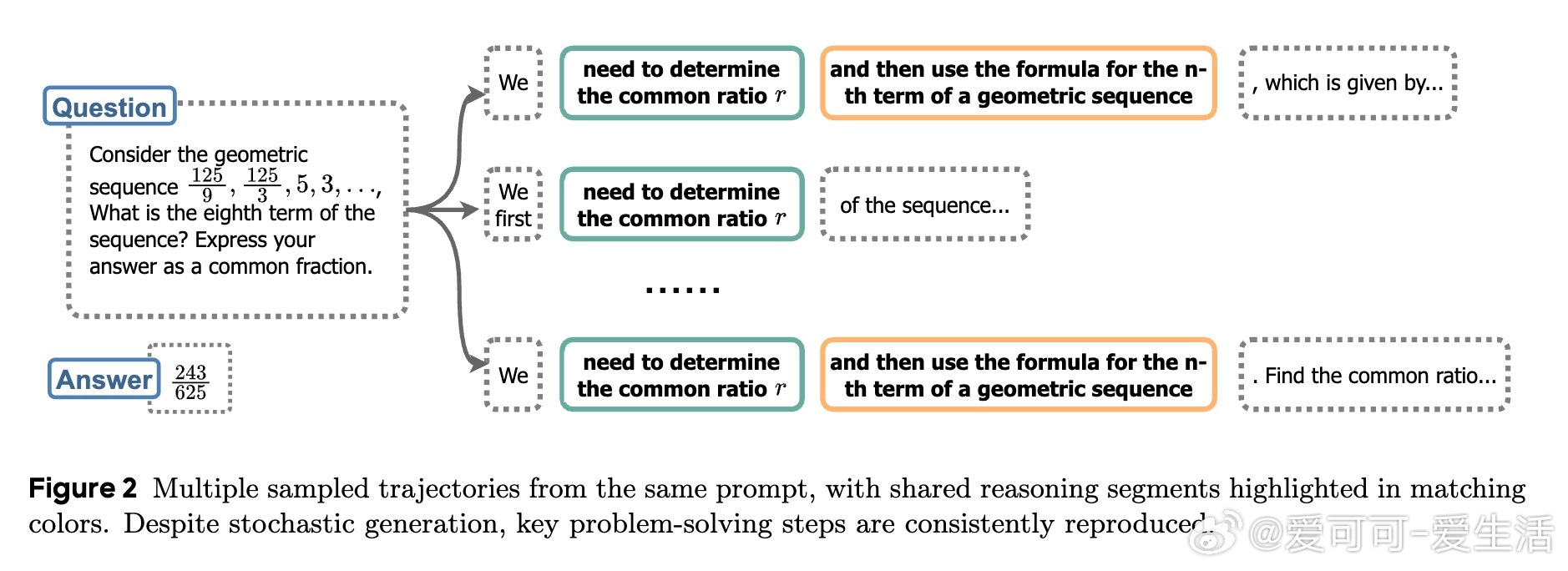
• 采用分段树形采样,将序列生成视为树结构搜索,充分利用共享前缀,避免重复计算与KV缓存浪费。
• 引入动态分支与概率回退策略,基于局部不确定性智能扩展推理路径,实现多样化探索与计算资源平衡。
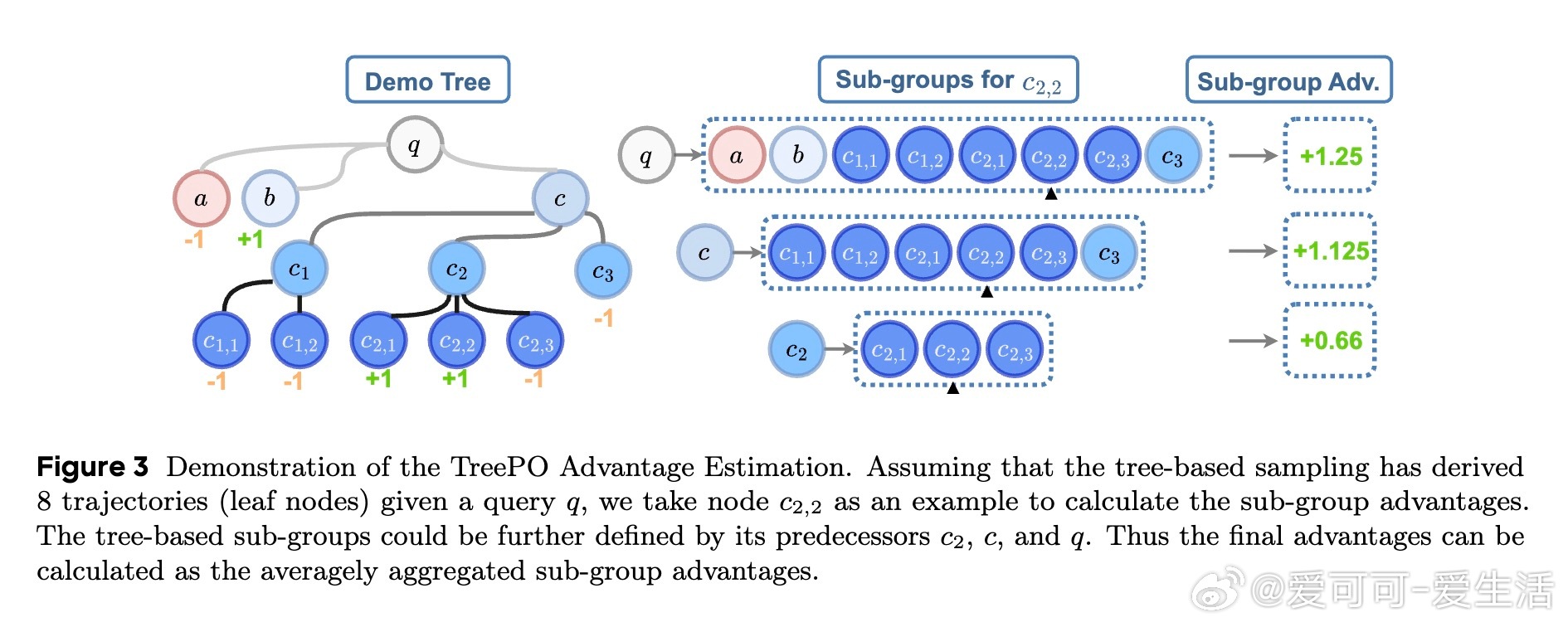
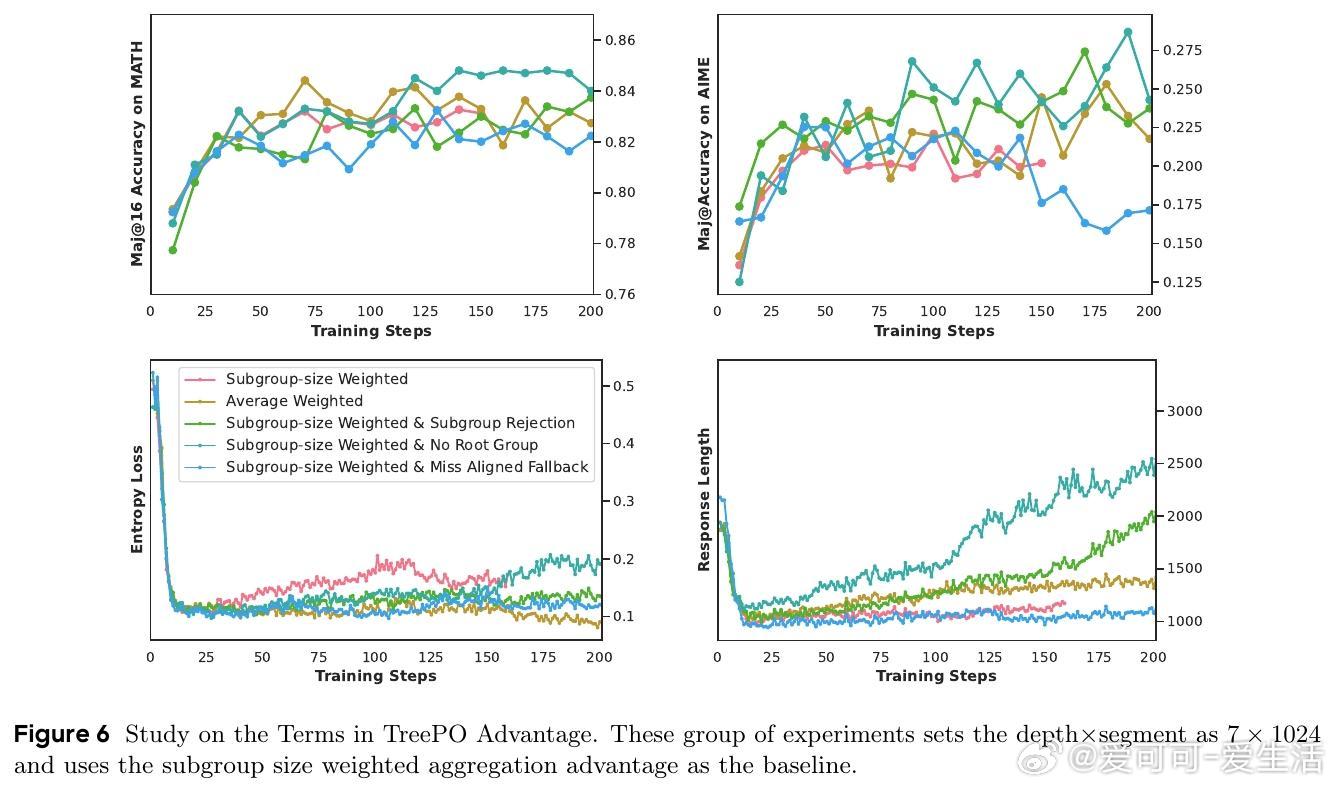
• 提出树形分段层次优势估计方法,基于子树集合的整体表现,精细化归因稀疏奖励,无需预先指令微调即可从基础模型直接强化训练。
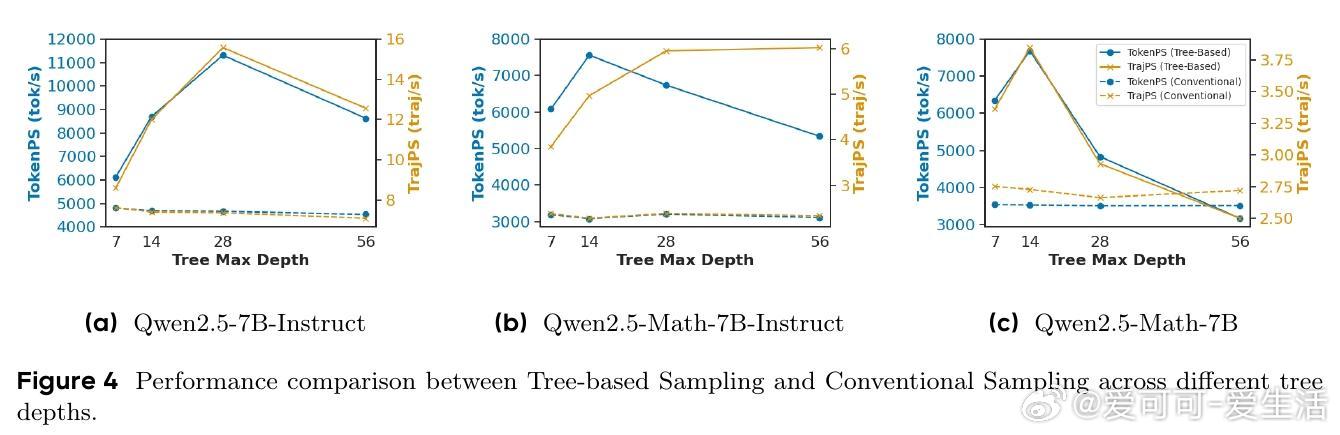
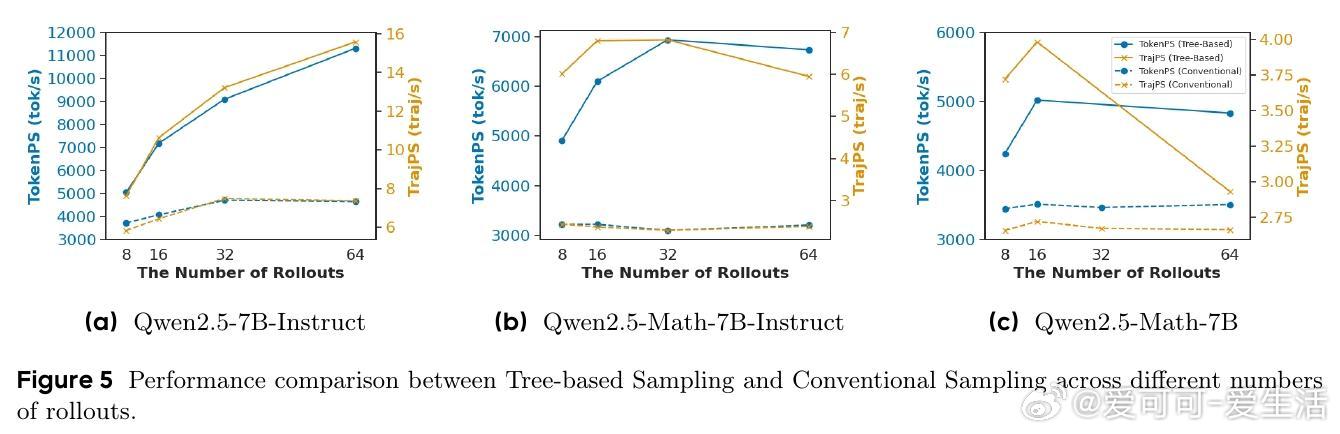
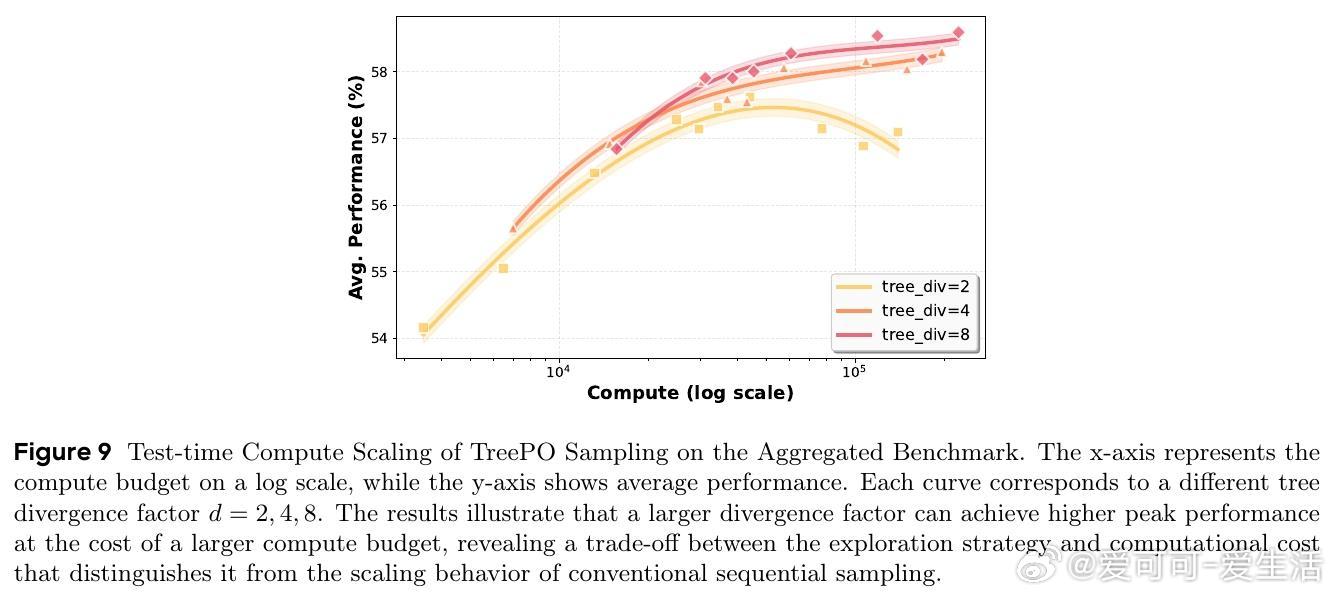
• 实验覆盖数学推理等多项基准,TreePO在保持甚至提升模型性能的同时,GPU采样计算减少22%至43%,轨迹级与token级推理开销分别降低40%和35%。
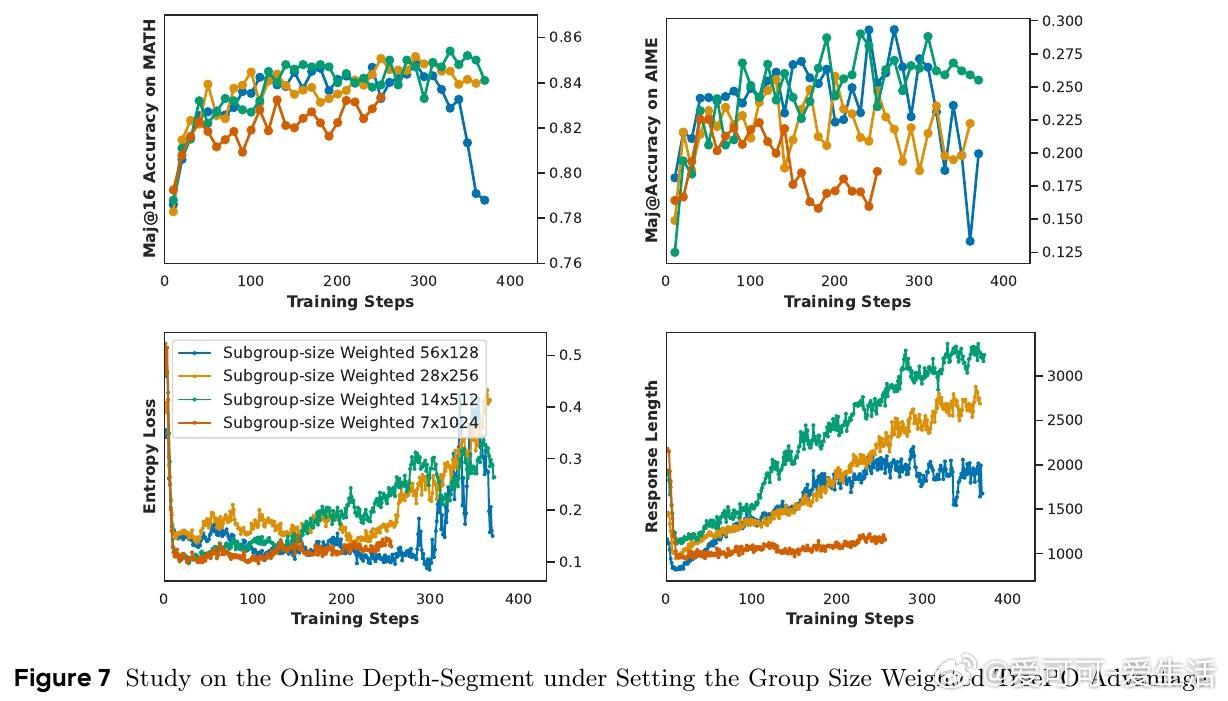
• 深度与分段长度的折中配置对性能和效率影响显著,最佳参数因模型与任务不同而异,体现灵活的计算资源与性能平衡能力。
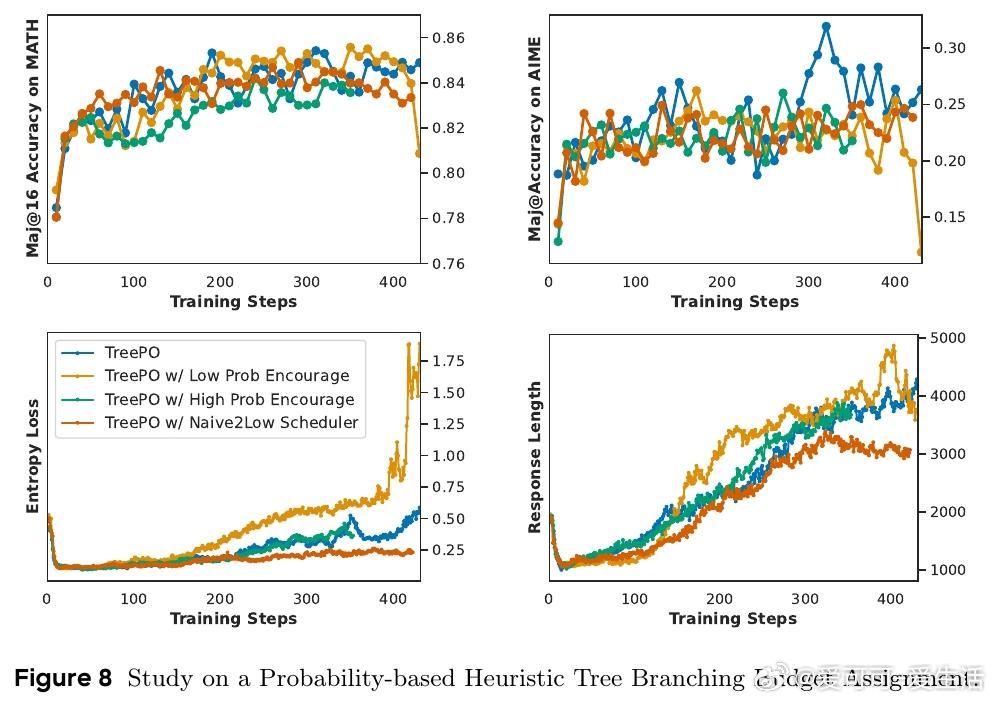
• 概率驱动的分支分配策略发现,单纯鼓励低概率路径虽增多探索多样性,但导致性能下降与响应冗长,合理平衡探索与利用更为关键。
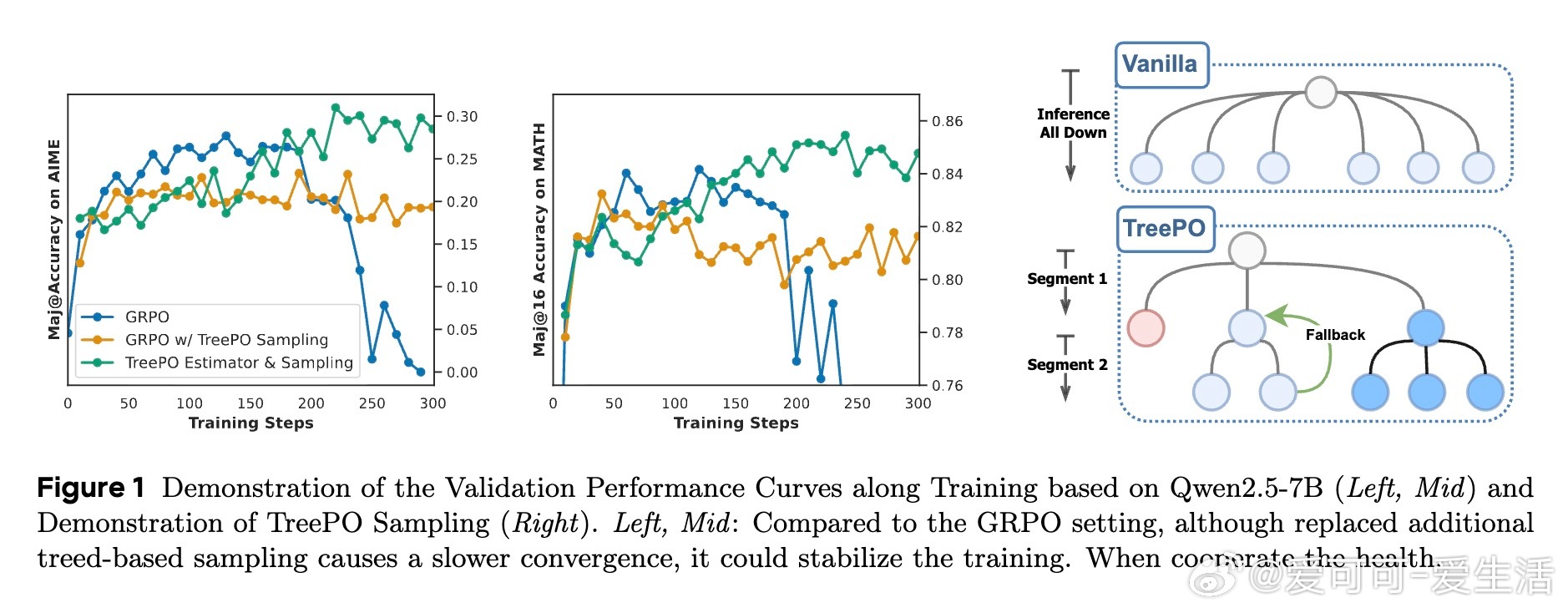
• 训练曲线表明,树基采样虽略减缓收敛速度,但增强训练过程稳定性,优势估计进一步提升训练效果,强化模型泛化能力。
心得:
1. 序列生成天然具备树状结构,利用共享前缀设计能大幅减少重复推理和计算浪费,提升采样效率。
2. 有效的探索不等于盲目多样性,合理的启发式分支策略需兼顾搜索质量与效率,避免误导模型进入无效路径。
3. 分段级别的优势估计通过层次化归因,更精准地反映不同推理路径贡献,促进训练稳定且具备更强泛化性。
详解👉 arxiv.org/abs/2508.17445
主页👉 m-a-p.ai/TreePO
强化学习大语言模型推理优化高效采样AI训练框架