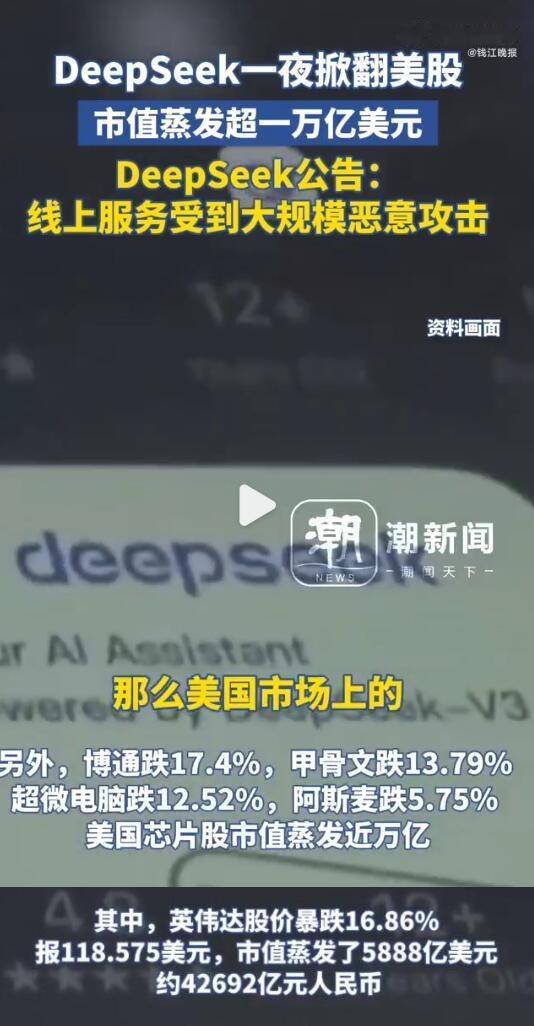
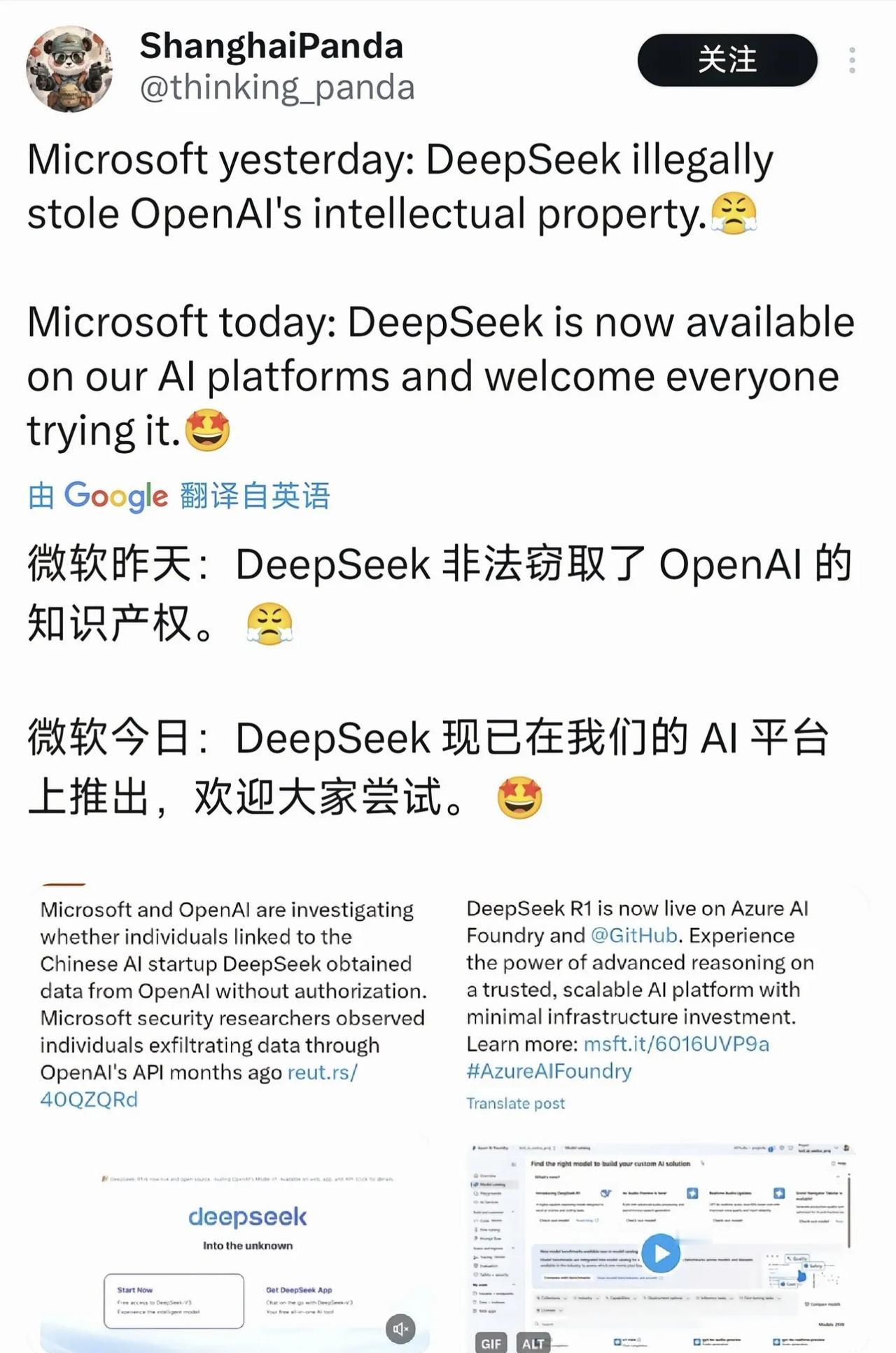
DeepSeek有什么独特之处?
技术架构
- 绕开CUDA技术:DeepSeek的V3模型绕开英伟达的CUDA技术,直接针对PTX进行优化,在2048个H800 GPU构建的集群上,成功训练出6710亿参数的MoE语言模型,效率比市场上最顶尖的AI模型高出10倍。
- 采用MoE架构:大胆采用业界非主流的MoE(混合专家)架构,体现了对技术路线的深刻理解和坚定信念。
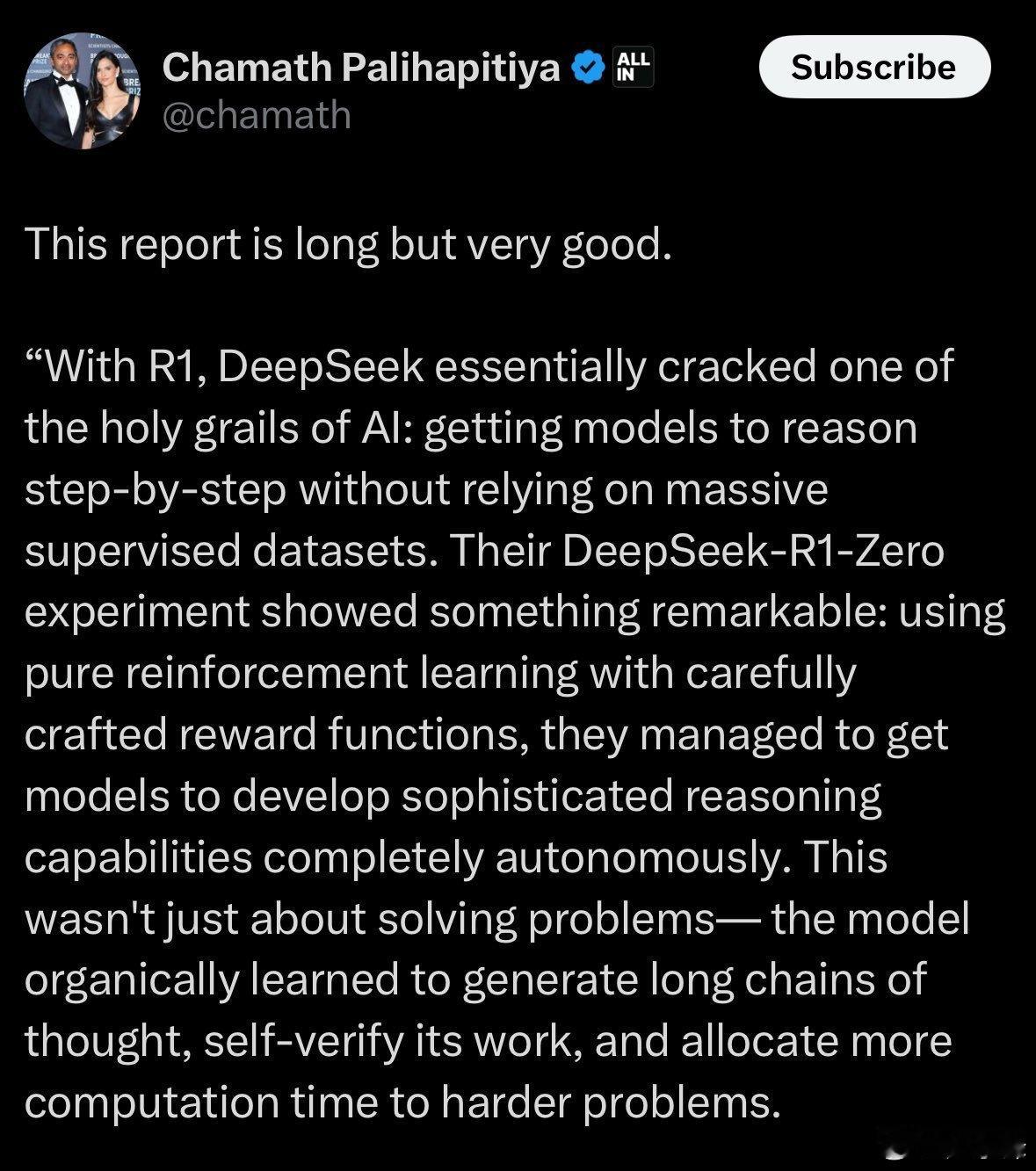
- 强化学习技术:DeepSeek的R1模型在后训练阶段大规模使用强化学习技术,在极少标注数据的情况下极大提升了模型推理能力。
功能特性
- 清晰的思维逻辑:能像人类专家一样通过思维链逐步分析问题,给出靠谱答案,而不是简单地给出结果,思维逻辑超清晰。
- 实时联网搜索:通过联网搜索功能能即时获取最新信息,让回答永远保持与时俱进,知识储备更新速度快。
- 多模态交互可能:可能支持文本、图像、语音等多模态交互,满足用户多样化需求,不过在图像生成上不占优势。
平台优势
- 开源协作:是开源平台,开发者可自由定制、修改和贡献代码,形成了活跃的社区,能不断更新和完善。
- NLP能力强:在情感分析、文本分类、命名实体识别等自然语言处理任务上表现出色,能处理海量数据并提取有价值的信息。
- 云平台集成灵活:可与亚马逊网络服务、谷歌云平台、微软Azure等多个云服务集成,方便开发者选择适合的云环境。
- 高度可定制化:可根据项目具体需求进行定制,能适应特定数据处理流程和小众应用场景。
- 训练成本低:训练和开发成本仅为OpenAI或Meta等公司同类产品的一小部分,具有极高的性价比。