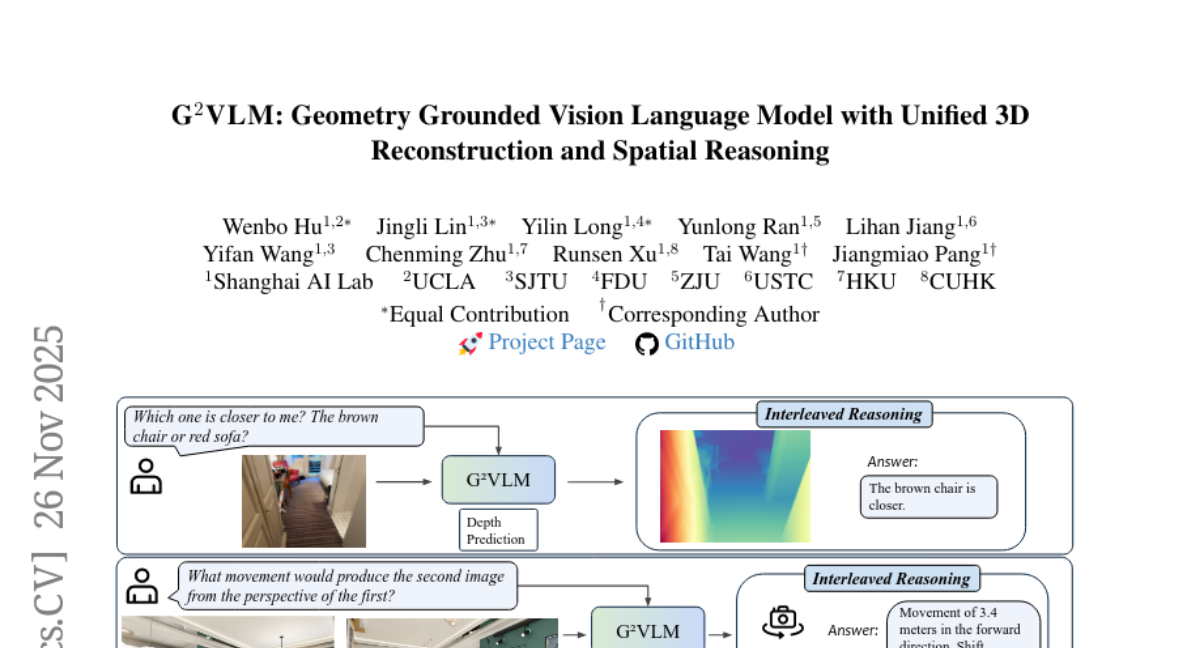
这项由上海AI实验室联合UCLA、上海交大、复旦大学、浙江大学、中科大、香港大学和香港中文大学等多所知名院校共同完成的突破性研究发表于2025年11月,论文编号为arXiv:2511.21688v1。研究团队开发出了名为G?VLM的革命性AI系统,这是全球首个能够同时进行3D空间重建和高级空间推理的统一视觉语言模型。有兴趣深入了解的读者可以通过该论文编号查询完整研究内容。
说到人类视觉系统的奇妙之处,我们的大脑其实运作着两套截然不同却又密切配合的视觉通道。第一套叫做腹侧通路,专门负责识别"这是什么"——当你看到一只猫时,正是这套系统告诉你"这是猫"。第二套叫做背侧通路,专门处理"在哪里"的问题——它告诉你这只猫距离你多远,在房间的哪个角落。这就像我们的大脑里住着两位专家:一位是"物体识别专家",另一位是"空间定位专家",它们协同工作让我们能够完美地理解和导航这个三维世界。
然而,现在的AI视觉系统却像是只有"识别专家"而缺少"定位专家"的残缺大脑。它们虽然能够识别图像中的各种物体,甚至能和人类进行对话,但在空间理解方面却表现得像个路痴——无法准确判断物体之间的距离关系,不能理解复杂的空间布局,更别说进行空间推理了。这就好比一个人能够认出所有的家具,却永远搞不清楚沙发和茶几谁离自己更近,或者如何从客厅走到厨房。
研究团队意识到这个问题的根源在于现有AI系统的学习方式过于"平面化"。它们就像一直生活在二维世界的生物,只能从大量的平面图片和文字描述中学习,却从未真正体验过三维空间的深度和立体感。正如一个从未离开过平面王国的居民无法理解立体几何一样,这些AI系统自然也就无法掌握真正的空间智能。
基于这样的洞察,研究团队决定创造一个革命性的AI系统——G?VLM,它模仿人类大脑的双通路视觉系统,同时拥有"几何感知专家"和"语义感知专家"。这就像为AI装上了一双真正的眼睛,让它不仅能看懂世界,还能感受空间。
一、双专家协作的奇妙架构
G?VLM的核心设计灵感来源于人类大脑的视觉处理机制,研究团队巧妙地构建了一个双专家协作系统。这个系统就像一个高效的建筑事务所,里面有两位各司其职却又密切配合的专家。
几何感知专家就像一位精密的测量师,它的工作是从二维图片中"看出"三维世界的几何结构。当你给它一张照片时,它能够准确地告诉你照片中每个像素点在真实世界中的三维坐标,就像拥有X光视觉一样能透过平面看到立体。更令人惊叹的是,它还能推算出拍摄这张照片时相机的确切位置和角度,仿佛能够逆转时光回到拍摄现场。
语义感知专家则更像一位博学的翻译官,专门负责理解图像内容并与人类进行自然对话。它能够识别画面中的物体,理解场景的含义,回答关于图像内容的各种问题。但与传统的视觉语言模型不同,这位专家并不是独自工作,而是时刻与几何专家保持着密切的信息交流。
这两位专家的协作方式特别巧妙。它们通过一种叫做"共享自注意力"的机制进行交流,就像两个人在同一个办公室里工作,随时可以互相请教和分享信息。几何专家发现的空间结构信息会实时传递给语义专家,帮助后者更准确地理解空间关系和进行推理。同样,语义专家对场景内容的理解也会反馈给几何专家,让它的三维重建更加精确。
与以往那些简单拼凑不同模块的系统相比,G?VLM的双专家是真正融为一体的。它们不是各自独立工作然后简单地把结果拼接起来,而是在整个处理过程中都保持着有机的互动和协作,就像一对配合默契的舞伴,每一个动作都是协调一致的。
这种设计的另一个巧妙之处在于它的可扩展性。由于系统可以直接从大量的普通图片和视频中学习三维几何知识,而不需要昂贵的三维标注数据,因此能够利用互联网上海量的多视角图像和视频资源进行训练。这就像让AI在虚拟的三维世界中自由探索和学习,逐渐掌握空间感知的奥秘。
二、循序渐进的学习策略
G?VLM的训练过程就像培养一个孩子逐渐掌握复杂技能一样,采用了精心设计的两阶段学习策略。这种方法确保系统能够稳步建立从基础几何感知到高级空间推理的完整能力体系。
第一阶段就像让孩子先学会走路。研究团队首先让几何感知专家专注于最基础也最关键的技能——从二维图像中感知三维几何结构。在这个阶段,语义感知专家暂时"休息",保持其预训练的状态不变,就像一个已经掌握语言技能的助手在一旁静静等待。
几何专家在这个阶段接受的是"魔鬼训练"。研究团队为它准备了一个包含大量三维场景数据的训练营,涵盖了从室内房间到户外街景的各种环境。这些数据就像一本本立体几何教科书,每一页都详细标注了空间中每个点的准确位置、相机的拍摄角度、表面的法向量等关键信息。
几何专家需要学会三项核心技能。首先是点云重建,就像雕塑师要能从一块石头中看出最终作品的形状一样,它要能从平面图像中准确预测每个像素在三维空间中的位置。其次是相机姿态估计,这相当于要能推算出拍摄者当时站在哪里、面向哪个方向、用什么角度拍摄。最后是表面法线估计,这涉及到对物体表面朝向的精确判断,就像要能感知每个表面是朝上、朝下还是朝向其他方向。
为了确保学习效果,研究团队设计了一个综合损失函数,就像设置了多个考核标准来全面评价学生的掌握程度。这个函数不仅要求几何专家能够准确重建三维点云,还要求它在相机姿态估计和表面法线预测方面达到很高的精度。通过这样的严格训练,几何专家逐渐练就了敏锐的空间感知能力。
第二阶段则像是让已经会走路的孩子学会跑步和跳跃。在这个阶段,研究团队解冻了语义感知专家,让两位专家开始真正的协同工作。这时的训练目标不再是简单的几何重建,而是要学会利用几何信息进行高级的空间推理和对话。
在联合训练中,系统面对的是更具挑战性的任务,比如"坐在墙上挂画下方的椅子上,书架相对于你在什么位置?"这样的空间推理问题。要回答这类问题,系统不仅需要识别出图像中的物体,还需要准确理解它们的空间关系,并且能够从不同的视角进行推理。
研究团队发现了一个有趣的现象:当几何专家的性能越好时,整个系统在空间推理任务上的表现也越出色。这证明了几何感知和语义理解之间确实存在着深度的相互促进关系,就像一个人的空间感越好,越能准确描述和理解复杂的空间场景。
三、令人惊叹的空间智能表现
G?VLM在各项测试中展现出的能力令人刮目相看,它不仅在传统的三维重建任务上达到了业界顶尖水平,更在复杂的空间推理任务上展现出了前所未有的智能。
在三维重建能力测试中,G?VLM就像一位技艺精湛的建筑师,能够仅从几张普通照片就准确还原出完整的三维场景结构。在著名的Sintel数据集上进行的单目深度估计测试中,系统将误差从之前最好模型的0.335降低到了0.297,这相当于把测量精度提高了10%以上。这种改进虽然在数字上看起来不大,但在实际应用中却意义重大,就像GPS定位精度的小幅提升就能带来导航体验的显著改善。
在点云重建和相机姿态估计等更复杂的任务上,G?VLM同样表现出色。它能够准确预测图像中每个像素对应的三维坐标,并且能够推算出拍摄时的相机位置和角度,精度达到了与专业三维重建软件相当的水平。更重要的是,G?VLM实现这些功能只需要普通的二维图像,不需要任何额外的三维传感器或特殊设备。
然而,G?VLM最令人印象深刻的还是它在空间推理任务上的表现。在SPAR-Bench这个权威的空间推理测试基准上,G?VLM-SR(专门优化过的空间推理版本)取得了54.87分的成绩,超越了之前表现最好的GPT-4o模型18.5个百分点。这个差距之大,就像在考试中一个学生得了90分而另一个只得了70分一样显著。
更让人惊叹的是,G?VLM能够进行复杂的多步推理。比如当面对"面向冰箱,如何导航到桌子上的电脑显示器?"这样的问题时,系统不仅能够识别出场景中的各个物体,还能准确理解它们的空间关系,并给出详细的导航指令:"转身,直走到白色打印机那里,然后右转,直走经过箱子就能到达黑色显示器。"
在一个特别有趣的任务演示中,G?VLM展现了令人惊叹的空间记忆和推理能力。系统需要在一个复杂的室内环境中找到最合适的礼品盒来装泰迪熊。它不仅能够记住在不同房间发现的礼品盒的大小,还能进行比较和权衡,最终找到大小最合适的那一个。整个过程就像一个人在现实中进行物品收纳时的思考过程,体现出了接近人类的空间智能水平。
系统还展现出了出色的视角转换能力。当被问到"坐在墙上挂画下方的椅子上,书架相对于你在什么位置?"时,G?VLM能够准确地进行视角转换,从询问者的假想位置出发判断空间关系,并给出"书架在我的右边"这样准确的回答。
四、技术创新的深度解析
G?VLM的技术创新不仅体现在架构设计上,更体现在解决了一系列关键的技术难题,这些突破为整个AI领域的发展开辟了新的可能性。
在视觉编码器的选择上,研究团队做出了一个看似简单却极其关键的决定:为两个专家配备不同的"眼睛"。几何感知专家使用DINOv2编码器,这是一个专门擅长捕捉低层次视觉特征的系统,就像一个精密的测量仪器,能够敏感地察觉到图像中细微的几何线索。而语义感知专家则使用Qwen2视觉编码器,这个编码器在理解图像语义内容方面表现出色,就像一位博学的学者能够深度理解画面的含义。
这种双编码器的设计最初引起了一些质疑,因为传统观念认为使用统一的编码器会更简洁高效。然而,实验结果证明了这种设计的明智性。双编码器系统在几何重建和空间推理两个任务上都显著优于单编码器方案,这说明不同类型的视觉任务确实需要不同的视觉表示方法。
在注意力机制的设计上,研究团队也进行了深入的探索。传统的三维重建模型通常使用帧间交替注意力,也就是有时关注单个图像的局部特征,有时关注多个图像之间的对应关系。但是这种交替机制与现代语言模型的架构不太兼容,就像试图让两种不同的机器共用一套控制系统一样困难。
经过大量实验,团队发现全局注意力机制效果最好。这种机制让系统能够同时考虑所有输入图像的所有位置,就像一个指挥家能够同时聆听整个交响乐团的演奏一样。虽然这种方法计算量更大,但它能够更好地捕捉复杂的空间对应关系,为准确的三维重建奠定了基础。
损失函数的设计也体现了研究团队的巧思。他们没有简单地使用单一的评价标准,而是设计了一个多目标优化函数,同时考虑点云重建精度、相机姿态估计准确性和表面法线预测质量。这就像用多个不同的尺子同时测量一件作品的质量,确保系统在各个维度上都达到很高的标准。
特别值得一提的是,研究团队还解决了训练稳定性这个困扰大规模几何学习的关键问题。他们发现在训练过程中经常出现数值爆炸,导致训练失败。通过仔细分析,团队发现这主要是由于三维标注数据中的噪声造成的。于是他们设计了一个智能的损失截断机制,当损失值超过阈值时会被平滑处理,这就像在激烈的学习过程中设置了安全阀,确保训练过程的稳定性。
五、广阔的应用前景
G?VLM的突破性能力为众多实际应用场景打开了全新的可能性,这些应用将深刻改变我们与数字世界交互的方式。
在机器人导航领域,G?VLM的空间理解能力可以让家用机器人变得真正实用。传统的机器人往往需要预先建立详细的环境地图才能工作,就像一个路痴必须事先背熟地图才敢出门。而配备了G?VLM的机器人就像拥有了天生的方向感,它们可以仅通过观察就理解复杂的室内环境,准确判断物体之间的空间关系,并且能够理解和执行复杂的导航指令。
在增强现实(AR)应用方面,G?VLM的三维重建能力可以让AR体验变得更加自然和准确。目前的AR系统往往需要特殊的标记或长时间的环境扫描才能建立空间锚点,而G?VLM可以即时理解场景的三维结构,让虚拟物体能够准确地放置在现实世界中的合适位置。这就像让虚拟世界和现实世界之间有了完美的桥梁。
在建筑和室内设计行业,G?VLM可以成为设计师的得力助手。设计师只需要拍摄几张现有空间的照片,系统就能自动生成精确的三维模型,并且能够理解空间的功能布局和使用需求。更进一步,系统还可以通过对话的方式协助设计师进行空间规划,比如"这个客厅怎样布置能让空间显得更宽敞?"
在电商和零售领域,G?VLM的应用同样前景广阔。消费者可以通过简单的语言描述和几张照片,让系统理解自己的空间需求,并获得个性化的产品推荐。比如"我的卧室比较小,需要一个既能当书桌又能当梳妆台的家具",系统可以准确理解空间限制和功能需求,提供最合适的建议。
在教育领域,G?VLM可以革命性地改变几何和空间概念的教学方式。传统的几何教学往往依赖抽象的图形和公式,而G?VLM可以让学生通过与真实场景的互动来理解空间概念。学生可以拍摄教室的照片,然后通过与系统的对话来探索几何关系和空间概念,让抽象的知识变得具体和生动。
在文娱创作领域,G?VLM可以成为内容创作者的强大工具。电影制作者可以利用系统快速生成场景的三维模型,进行镜头规划和特效设计。游戏开发者可以通过简单的照片快速构建游戏场景的几何基础。而普通用户也可以利用这项技术创作具有空间感的互动内容。
研究团队还指出,G?VLM的统一架构为未来的3D场景编辑功能奠定了基础。用户未来可能可以通过自然语言指令直接修改三维场景,比如"把这个房间的墙壁颜色改成蓝色"或"在客厅里添加一张沙发",系统不仅能理解指令,还能准确地在三维空间中执行操作。
六、面临的挑战与未来展望
尽管G?VLM取得了令人瞩目的成果,但研究团队也坦诚地指出了当前面临的挑战和未来的发展方向。这些挑战不仅是技术问题,更是整个AI空间智能发展道路上需要跨越的里程碑。
训练稳定性是目前面临的主要技术挑战之一。由于G?VLM需要同时学习几何感知和语义理解两套复杂的技能,训练过程就像同时教一个人学习高等数学和文学创作一样困难。特别是在模型规模扩大时,训练过程变得更加不稳定,需要更加精心的调优和更多的计算资源。研究团队正在探索更先进的优化技术和训练策略来解决这个问题。
计算资源需求是另一个现实挑战。G?VLM的训练需要大量的GPU资源和时间,几何感知专家的预训练阶段就需要32-64张A800 GPU运行数天到数周。这样的计算需求目前只有大型研究机构和科技公司能够承担,限制了技术的普及和应用。团队正在研究如何通过模型压缩、知识蒸馏等技术降低计算门槛。
数据质量和标注成本也是一个持续的挑战。虽然G?VLM可以从普通的多视角图像中学习,但高质量的三维几何标注数据仍然稀缺且昂贵。现有的三维数据集往往存在标注噪声和覆盖范围有限的问题,这影响了模型在真实世界复杂场景中的表现。研究团队正在探索自监督学习和弱监督学习方法来减少对高质量标注数据的依赖。
模型规模扩展是团队特别关注的发展方向。目前的G?VLM基于2B参数的基础模型构建,相对于动辄数十亿参数的大型语言模型来说还比较小。研究表明,在某些复杂的空间推理任务上,更大的模型确实能带来更好的性能。团队计划在未来推出更大规模的版本,探索空间智能的上限。
泛化能力的提升也是重要的研究方向。虽然G?VLM在测试数据集上表现出色,但在面对完全未见过的场景类型时,性能仍有下降。特别是在处理极端光照条件、复杂动态场景或者文化背景差异较大的环境时,模型的鲁棒性还有待提高。
跨模态能力的扩展是另一个令人兴奋的方向。目前G?VLM主要处理视觉和语言信息,但真实的空间智能还应该包括触觉、听觉等其他感官信息。比如通过声音定位、通过触摸感知材质和形状等。研究团队正在考虑如何将这些能力整合到统一的框架中。
实时性优化是实际应用的关键需求。目前G?VLM的推理速度虽然可以接受,但对于需要实时反馈的应用场景(如机器人控制、AR交互)来说还有提升空间。团队正在研究模型加速技术和硬件优化方案,力求在保持精度的同时显著提升推理速度。
说到底,G?VLM代表了AI向真正空间智能迈出的关键一步。它不仅解决了长期困扰视觉语言模型的空间理解问题,更重要的是为构建能够真正理解和操作三维世界的AI系统奠定了坚实基础。虽然距离完美的空间智能还有距离,但这项研究已经清晰地勾勒出了前进的方向。
正如人类婴儿需要通过不断的探索和学习才能掌握空间认知能力一样,AI的空间智能发展也是一个循序渐进的过程。G?VLM的成功证明了通过模仿人类大脑的视觉处理机制,AI确实可以获得更接近人类的空间理解能力。这不仅是技术上的突破,更是我们对智能本质理解的深化。
随着这项技术的不断完善和普及,我们有理由期待一个AI能够真正理解和参与三维世界的未来。那时,AI助手不再是只能"看图说话"的被动工具,而是能够真正理解空间、进行空间推理、甚至协助我们改造空间环境的智能伙伴。这样的未来或许比我们想象的更近,而G?VLM正是通向这个未来的重要桥梁。
Q&A
Q1:G?VLM是什么?
A:G?VLM是由上海AI实验室等多所院校联合开发的革命性AI系统,它是全球首个能够同时进行3D空间重建和高级空间推理的统一视觉语言模型。该系统模仿人类大脑的双视觉通路,拥有几何感知和语义感知两个专家,既能从二维图片重建三维场景,又能进行复杂的空间对话和推理。
Q2:G?VLM与现有AI视觉系统有什么不同?
A:传统AI视觉系统就像只有"识别专家"而缺少"定位专家"的残缺大脑,只能识别物体但不懂空间关系。而G?VLM通过双专家协作设计,不仅能识别"这是什么",还能精确理解"在哪里"、"距离多远"等空间信息,能够进行真正的三维空间推理,就像拥有了完整的人类视觉系统。
Q3:G?VLM在实际应用中表现如何?
A:G?VLM在多项测试中表现出色,在三维重建精度上超越了专业模型,在空间推理测试中比GPT-4o高出18.5分。它能够进行复杂的多步推理,比如准确规划室内导航路线,进行视角转换判断空间关系,甚至能记住和比较不同房间物品的大小特征,展现出接近人类的空间智能水平。