🔻大胆猜测:Deepseek 在五天解锁活动结束后或不久,将发布新版本号模型。
🔻继续推进 AGI 的开源社区建设。
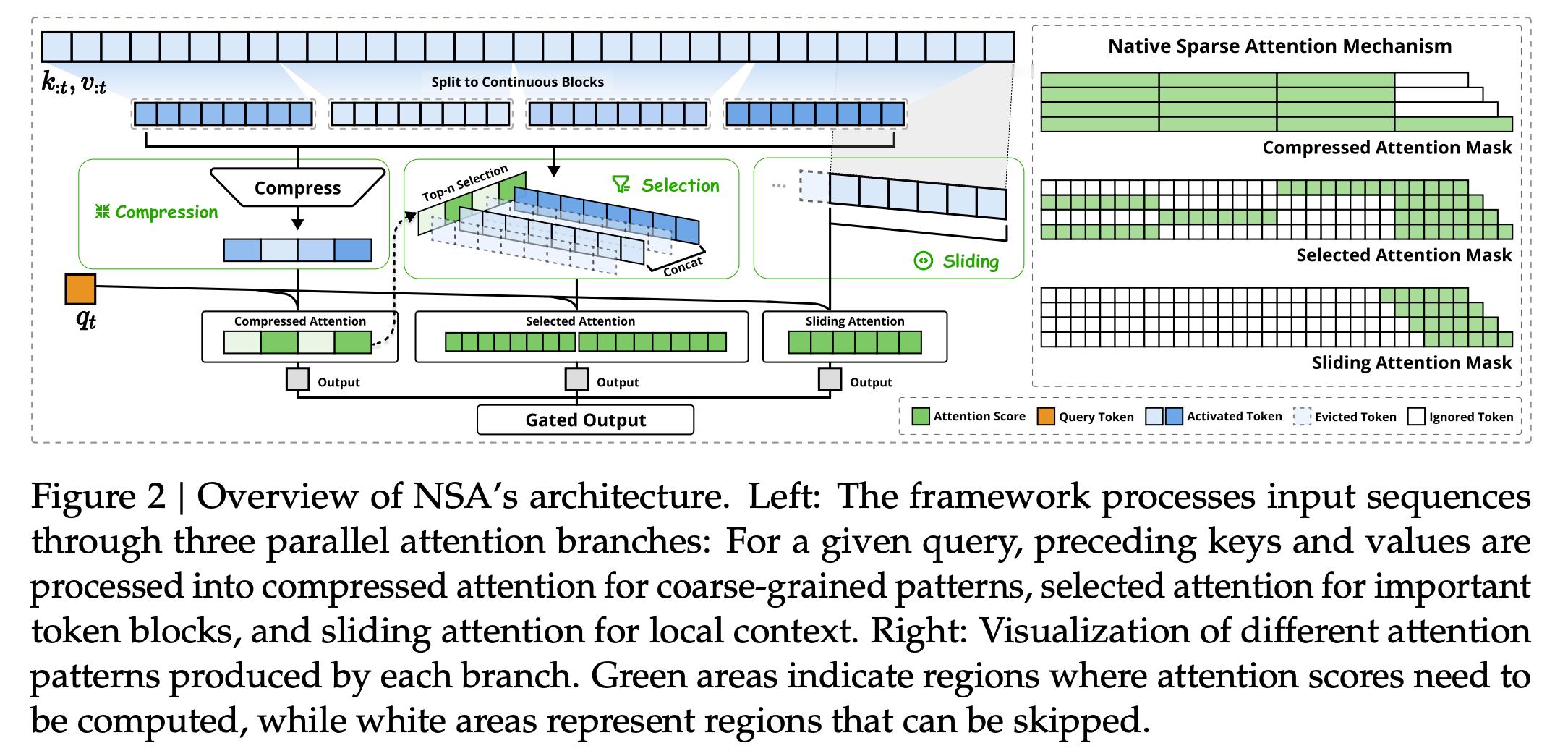
🔻据我了解,一月份的时候,Deepseek 团队的首要任务是准备开源社区所需的一切最低限度+必要的东西,同时将大部分精力放在迭代下一代模型上。2月18日的时候,Deepseek 发布了介绍 NSA的新论文:用于超快速长上下文训练和推理的硬件对齐和本地可训练稀疏注意力机制。
🔻NSA 将算法创新与硬件对齐的优化相结合,以实现高效的长上下文建模。采用动态分层稀疏策略,将粗粒度标记压缩与细粒度标记选择相结合,以保持全局上下文感知和局部精度。
🔻在过去,长上下文建模是下一代语言模型的关键,但传统注意力机制的高计算成本成为瓶颈。现有稀疏注意力方法虽具潜力,但在实际部署中常因硬件不匹配或缺乏训练支持而效率低下。
🔻Deepseek 的方法通过两项关键创新推进了稀疏注意力设计:
🔹通过算术强度平衡算法设计实现了显著加速,并针对现代硬件进行了实现优化。
🔹支持端到端训练,在不牺牲模型性能的情况下减少了预训练计算。
🔻实验表明,使用 NSA 预训练的模型在一般基准、长上下文任务和基于指令的推理中保持或超过了全注意力模型。同时,NSA 在 64k 长度序列的解码、前向传播和后向传播过程中实现了比全注意力机制显著的加速,验证了其在整个模型生命周期中的效率。
🔻DeepSeek 的新 NSA 技术只关注最重要的数据,使人工智能模型更快、更便宜,非常适合处理长时间对话或复杂任务。该技术与现代计算机硬件配合使用,可将人工智能的思维速度提高 11 倍(在27B参数模型上预训练,NSA在通用基准(平均0.456 vs 全注意力0.443)、长上下文任务(LongBench 0.469 vs 0.437)和数学推理(AIME 0.146 vs 0.092)中表现优异。在64k序列上,NSA实现解码11.6倍、前向9倍和反向6倍加速),在保持模型能力的同时显著降低计算延迟。
🔻与传统方法不相上下甚至更胜一筹(与推理阶段稀疏方法(如H2O、Quest)相比,NSA因其训练支持和硬件优化更具优势。克服了现有方法的局限性,如阶段限制稀疏性和不可训练组件),同时还能节省能源。这似乎与他们之前的许多工作以及他们训练 V3 和 R1 的一些专家混合元素相吻合,只是应用到了 LLM堆栈 的不同部分。
🔻他们已经把所有东西都清楚地写在技术报告中(最优美的部分依然是数学的部分),并鼓励社区参与复制,我认为这也是 Deepseek 团队的独特见解。