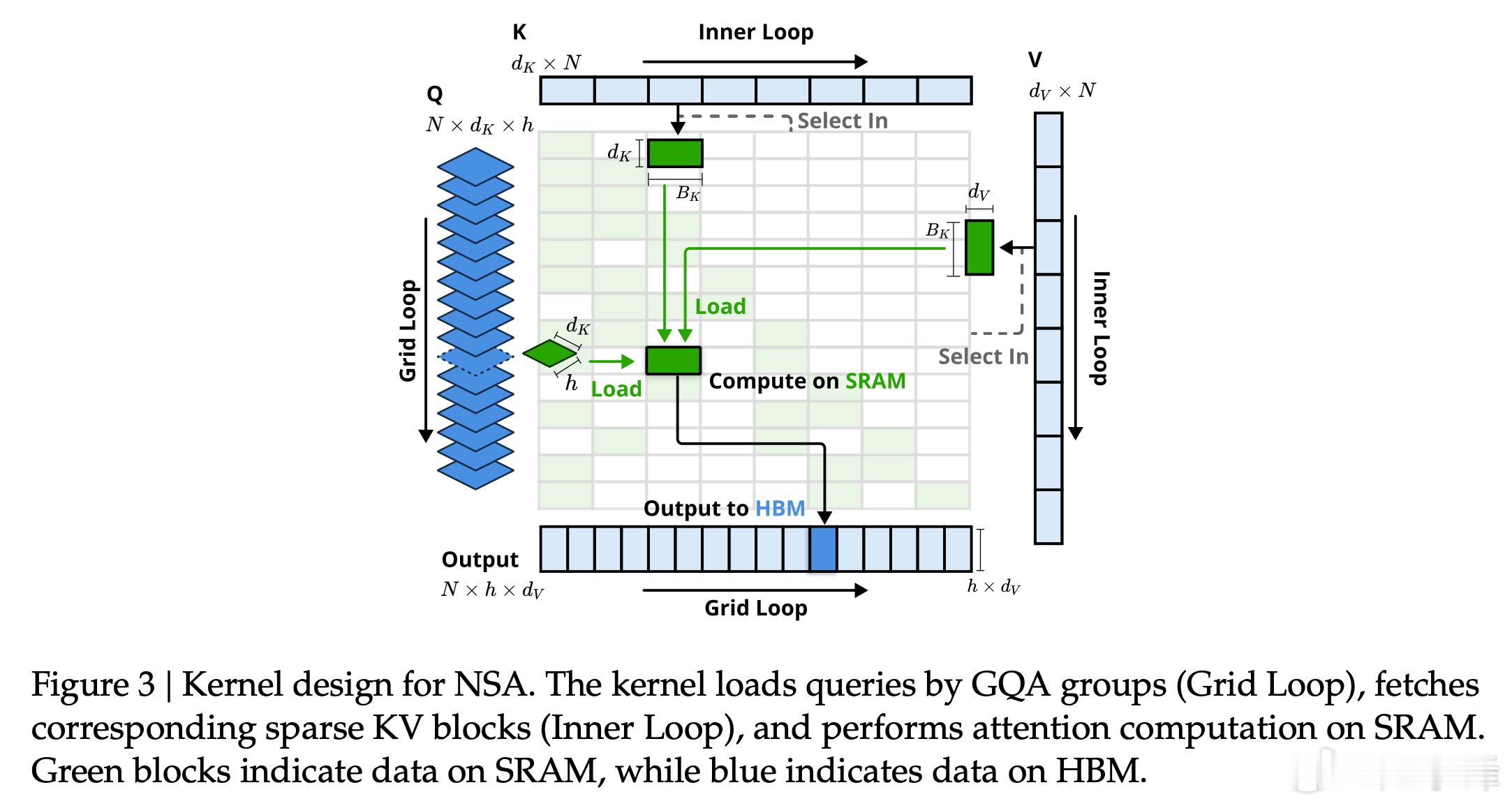
Deepseek官方X账号今日介绍团队最新发表的一篇论文。
🚀 推出NSA:一种硬件适配且可原生训练的稀疏注意力机制,用于超快速长上下文训练与推理!
NSA的核心组件:
• 动态分层稀疏策略
• 粗粒度词元压缩
• 细粒度词元选择
💡NSA针对现代硬件进行了优化设计,在不影响性能的前提下,加速推理过程并降低预训练成本。在通用基准测试、长上下文任务以及基于指令的推理任务中,它的表现与全注意力模型相当,甚至更优。
📖 欲了解更多详细信息,请查看我们的论文:arxiv.org/abs/2502.11089