外国学者发文为DeepSeek辟谣 【 外国学者驳斥涉DeepSeek五大误区 】当地时间2月4日,国外学者Tanishq Mathew Abraham博士在其个人博客发文,驳斥了目前互联网上对DeepSeek的种种谣言和攻击。
文章指出,DeepSeek的推理模型R1在性能上与OpenAI的前沿模型o1相当,且训练成本相对较低,引发了广泛关注。然而,随之而来的是一些关于DeepSeek的误解和错误信息。Abraham博士逐一驳斥了这些谣言:
原文澄清了五大误区:
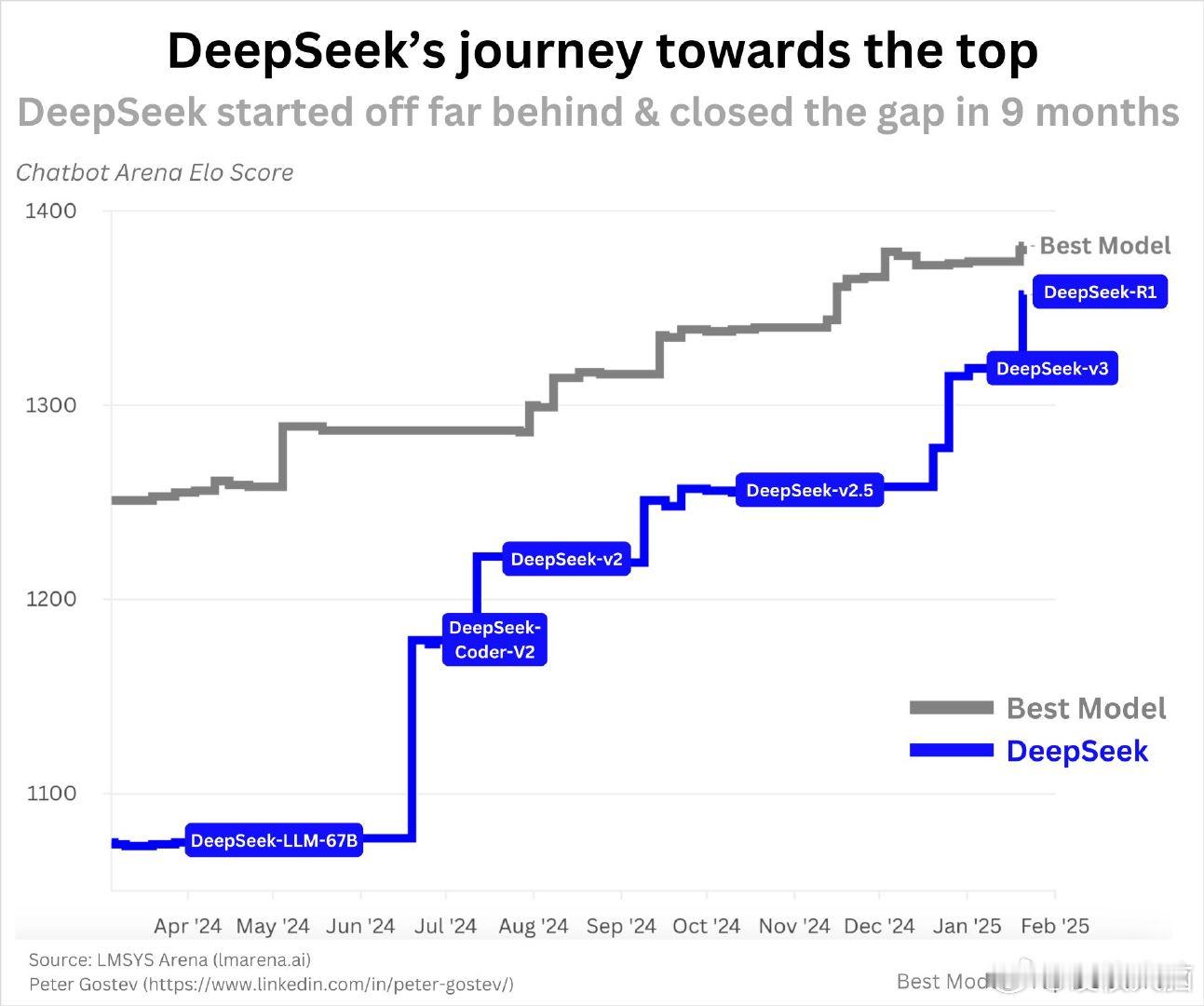
第一、DeepSeek并非一夜成名的公司:早在2023年11月,DeepSeek就发布了其首个开源模型DeepSeek-Coder,并在一年内逐步发展到R1,考虑到其强大的研究团队,其进展速度在AI领域非常正常。
第二、关于训练成本过低疑似造假的质疑:DeepSeek公布的600万美元训练成本是基于当前市场价格的估算,实际成本可能更低。此外,模型训练过程中的实验和研究人员薪资等额外成本并未被计入,但这在其他AGI公司中也是常见现象。
第三、DeepSeek的成功意味着美国AGI公司浪费资源:虽然DeepSeek在训练效率上表现出色,但更多的计算资源仍然有助于提升模型性能。美国AGI公司对扩展定律的信念使其继续投资于计算资源,这与DeepSeek的成功并不冲突。
第四、DeepSeek是否抄袭已有路径,缺乏创新性:DeepSeek在模型设计和训练方法上有多项创新,如多潜在注意力机制、GRPO强化学习算法和DualPipe多GPU训练方法等,这些创新已被开源并详细记录。
第五、关于DeepSeek从ChatGPT“违规蒸馏”的指控:Abraham博士认为,即使DeepSeek使用了ChatGPT生成的数据进行训练,这也无法解释其在模型性能和架构上的创新。此外,许多LLM都使用合成数据进行训练,这并不违反ChatGPT的使用条款。
据作者总结,一些 AI 人员,尤其是 OpenAI 的一些人,正试图低估 DeepSeek。另一方面,一些专家和自称专家的人对 DeepSeek 的反应是夸大其词的,甚至是危险的。同时,作者表示DeepSeek 值得认可,而 R1 是一个令人印象深刻的模型。
根据Tanishq Mathew Abraham 博士的个人简历,他10岁高中毕业,GPA 为 4.0;11 岁时,继续以 4.0 的成绩获得了 3 个副学士学位;14 岁时以优异成绩毕业于加州大学戴维斯分校,获得生物医学工程学士学位;19 岁时毕业于加州大学戴维斯分校,获得生物医学工程博士学位。曾任MedARC 首席执行官兼创始人,Stability AI 研究总监,加州大学戴维斯分校 Levenson 实验室成员。(来源:个人网页、领英网)