
英文题目:Controlling diverse robots by inferring Jacobian fields with deep networks
中文题目: 通过深度网络推断雅可比场控制多样化机器人
作者:Sizhe Lester Li, Annan Zhang, Boyuan Chen, Hanna Matusik, Chao Liu, Daniela Rus, Vincent Sitzmann
作者单位: 麻省理工学院(MIT)
期刊:Nature(IF 48.5中科院一区,JCR Q1)
发表时间:2025年6月25日
链接:https://doi.org/10.1038/s41586-025-09170-0
引文格式:Li S L, Zhang A, Chen B, et al. Controlling diverse robots by inferring Jacobian fields with deep networks[J]. Nature, 2025.
01 全文速览
传统机器人是“可建模”的——刚性连杆、低公差关节、每个关节都有编码器。但仿生机器人(软体、3D 打印、气动、多材料)很难用数学模型描述:材料非线性、大变形、迟滞、 backlash……专家花一个月建立的模型,换一个工况就失效。
MIT 计算机科学与人工智能实验室(CSAIL)团队提出了一种通用的机器人控制方法——视触雅可比场(Visuomotor Jacobian Field)。图 1a 展示了核心思想:从单张图像出发,深度网络推断出机器人的 3D 几何(Neural Radiance Field)和运动敏感性(Jacobian Field),后者能预测任意 3D 点在任意电机指令下的运动方向(颜色代表对不同指令通道的敏感度)。图 1b 展示了闭环控制:给定期望轨迹(像素空间或 3D),利用雅可比场优化电机指令,以约 12Hz 的频率实时执行。
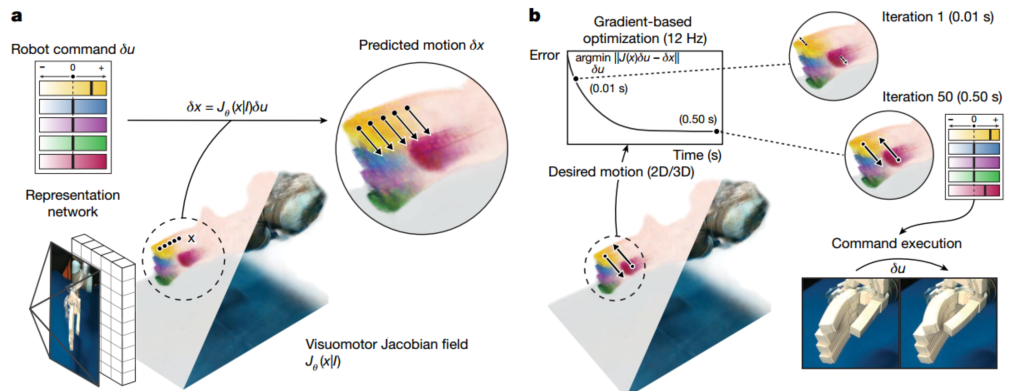
图 1 用视觉运动雅可比场控制机器人。视觉运动雅可比场的重建和运动预测。从单个图像,机器学习模型推断场景中机器人的3D表示,我们将其命名为视觉运动雅可比场。它对机器人的几何形状和运动学进行了编码,使我们能够在所有可能的命令下预测机器人表面点的三维运动。颜色表示该点对单个命令通道的敏感度。b、视觉闭环控制。给定像素空间或3D中的期望运动轨迹,我们使用视觉马达雅可比场来优化机器人命令,该命令将以大约12 Hz的交互速度产生规定的运动。在现实世界中执行机器人命令确认了期望的运动已经实现。
该方法仅需 2–3 小时的多视角随机运动视频(12 个 RGB‑D 摄像头),无需人工标注或专家建模。训练后,仅用一个普通 RGB 摄像头就能控制机器人。作者在四种差异巨大的平台上验证:3D 打印的软‑刚性混合气动手、基于手性剪切拉胀材料的柔性腕部平台、16 自由度的 Allegro 灵巧手、低成本的 Poppy 教育机械臂。结果显示,该方法能精确重建 3D 几何和运动场,并在闭环任务中达到毫米级/度级精度,甚至在外部扰动和视觉遮挡下仍能鲁棒工作。
核心亮点:
✅ 通用性:不依赖任何先验(材料、驱动、传感器),软硬机器人通吃
✅ 自我监督:仅需随机运动视频,无需标注或专家设计状态变量
✅ 雅可比场:首次在 3D 空间密度地学习机器人的差分运动学,实现“任意点对任意指令”的灵敏度预测
✅ 跨视角演示迁移:可将一个视角的演示视频提升到 3D,再从新视角跟踪
✅ Nature 级别验证:四套平台 + 扰动实验 + 与解析模型对比,数据充分
02 研究内容
🤖 2.1 核心思想:从状态建模到雅可比场
传统机器人控制依赖于系统状态
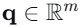
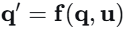
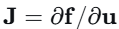
本文定义雅可比场:
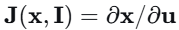
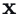
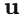
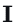
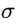

其中W是图像特征体,
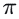
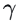
📊 2.2 数据采集与自监督训练
Extended Data Fig. 1a 展示了数据采集:12 台 RGB‑D 相机环绕机器人,记录随机指令执行前后的多视角图像和深度。用 RAFT 光流法提取相邻帧的 2D 运动
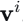
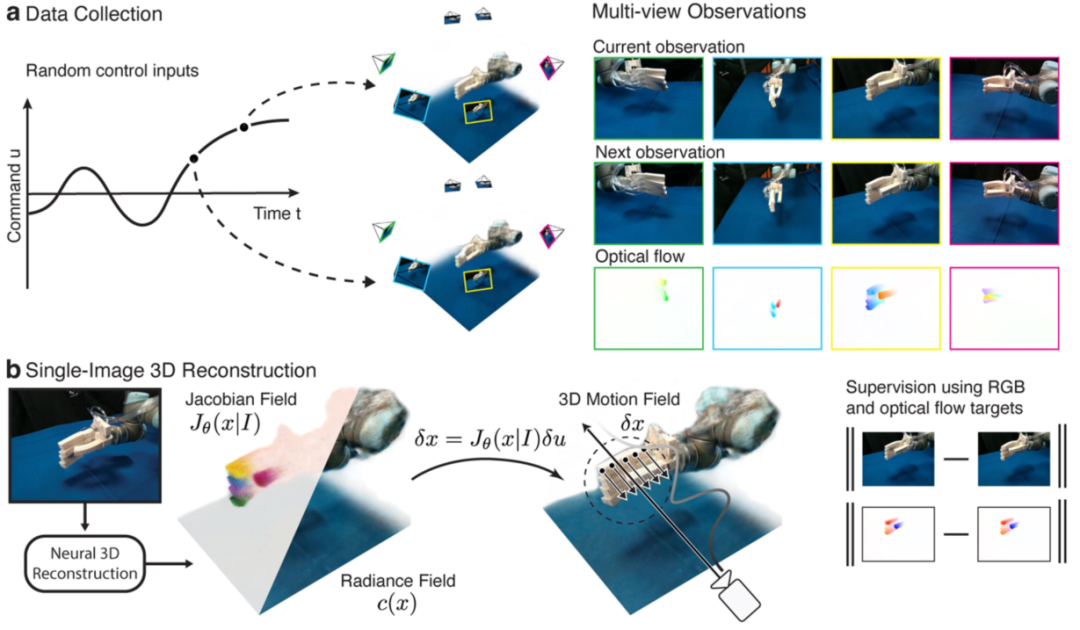
Extended Data Fig. 1 数据集收集、训练和推理过程概述。首先,我们的数据收集过程会对要在机器人上执行的随机控制命令进行采样。使用12个RGB-D摄像机的设置,我们在每个命令执行之前和每个命令稳定到稳定状态之后记录多视图捕捉。我们的方法首先进行神经3D重建,该神经3D重建将单个RGB图像观察作为输入,并输出雅可比场和辐射场。给定机器人命令,我们使用雅可比场计算3D运动场。我们的框架可以通过将运动场渲染成光流图像并将辐射场渲染成RGB-D图像来完全自我监督地训练。
Extended Data Fig. 1b 展示了训练流程:随机选一个视角作为输入,重建雅可比场和辐射场;给定指令
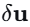
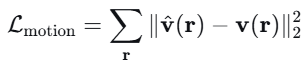
🎯 2.3 闭环控制:2D 轨迹跟踪与 3D 演示迁移
控制部分采用简单的 MPC。对于 2D 轨迹跟踪,提取演示视频中表面点的像素轨迹,利用雅可比场优化指令使投影后的 2D 点与目标距离最小。对于 3D 轨迹迁移,利用辐射场将 2D 帧提升为 3D 点云,用 Wasserstein‑1 距离衡量形状差异,实现跨视角跟踪。
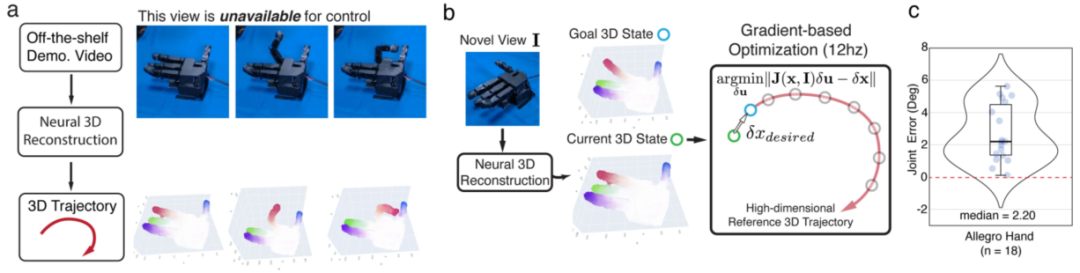
Extended Data Fig. 4 3D支持视点之间的演示转换。首先,我们的模型将演示视频中的每个2D RGB帧提升为一个3D点云(左图)。演示视频来自不同于可用于控制的视点(右图)。第二,我们的3D表示能够从推理时无法获得的视点对演示视频进行轨迹跟踪。我们使用Wasserstein-1 distance56来测量当前形状和参考点之间的3D差异。c,绘制误差,测量为实现的最终状态和最终跟踪目标之间的关节角度差。
🧪 2.4 实验结果:四类机器人全覆盖
图 2 展示了从单张图像重建的几何和雅可比场。每一行对应一个机器人平台(a. Allegro 手;c. HSA 平台;e. Poppy 臂;g. 气动手)。中间列是重建的雅可比场(颜色编码不同指令通道),两侧是预测深度与真实深度的对比,以及预测运动与参考运动的对比。结果表明,雅可比场成功学会了每个指令通道对应的 3D 部件运动。
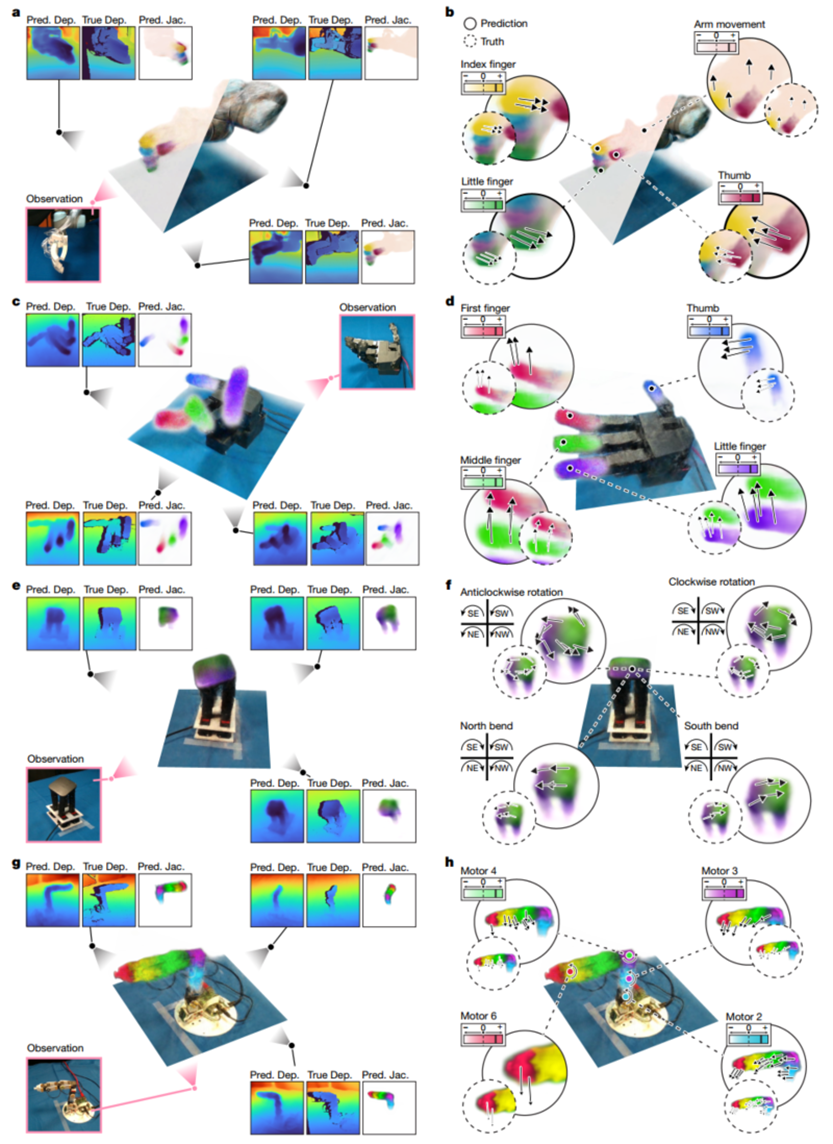
图 2 从单幅图像重建机器人几何和运动学。a,c,例如,重建的雅可比和辐射场(中心)的可视化,以及从单个输入图像重建的和测量的几何形状(侧面)的比较。颜色表示3D点对不同致动器命令通道的运动敏感度,这意味着我们的系统在没有人类注释的情况下成功地学习了机器人3D部件和命令通道之间的对应关系。我们展示深度预测(Pred)。离开)旁边是来自RGB-D摄像机的测量值(真实Dep。),展示了所有系统的3D重建精度。Pred。江淮。,预测雅可比。b,d,f,h,使用雅可比场预测的3D运动。我们显示了使用视觉马达雅可比场(实心圆)预测的各种马达命令的运动,旁边是使用点跟踪从视频流重建的参考运动(虚线圆)。重建的运动在所有机器人系统中都是定性准确的。尽管我们手动对命令通道进行了颜色编码,但是我们的框架将命令通道与3D运动关联起来,而无需监督。

Extended Data Fig. 2视觉运动控制的附加评估。(a,b),我们的框架控制一个3D打印的气动手抓住一个物体并完成取放任务。(c,d),我们的方法控制快板手完全关闭和打开每个手指。(e,f),我们有意干扰场景,以创建遮挡和背景变化。我们发现雅可比场对非分布场景是鲁棒的,并成功地控制手实现详细的运动。

Extended Data Fig. 5雅可比模型和直接神经流基线之间的测试集的定性比较。我们在扩展数据表3中报告的测试样本上评估我们的模型和基线。与数值结果一致,我们定性地发现我们的模型可以在测试数据集上预测正确的光流。相比之下,基线光流模型无法解释分布外的机器人命令,因为缺乏对动态系统的局部性和对称性的感应偏差。在最后一行,我们将雅可比模型的组件可视化。这验证了雅可比模型可以将空间体积分解成对测试数据集上的每个机器人手指敏感的部分。雅可比着色方案与图2一致。
图 3 展示了闭环控制结果:a 气动手抓取与遮挡下手指运动;b Allegro 手合拳;c HSA 平台旋转/弯曲;d 安装在 UR5 上的气动手取工具推苹果。

图 3 基于视觉的多机器人闭环控制。答:我们控制了一只3D打印的软硬结合的气动手来完成抓取(上图),并在有遮挡物的情况下执行手指运动(下图)。b、我们的方法精确地控制了快板手的每一根手指合拢,形成拳头。我们使用我们的系统来控制复杂的旋转和弯曲运动在一个腕状的,柔软的手剪切增力平台上。我们控制安装在UR5机器人手臂上的软硬结合的气动手来完成工具抓取和推动动作。e,组装低成本、3D打印的机械臂的过程,这种机械臂很难建模且缺乏传感。f,我们的方法被证明对反冲是鲁棒的,即由参考文献中描述的Poppy机器人的关节和齿轮的宽松公差引起的间隙或“摆动”。41,使机器人手臂能够在空中画出字母M、I和T。这些动作序列不在分布范围内,也不是训练数据的一部分。
图 4 定量分析了鲁棒性和精度:
a‑c:在 HSA 平台上附加 350g 重物改变动力学,仍能完成旋转运动,末端误差 7.3mm。
d:Allegro 手关节误差小于 3°,指尖误差小于 4mm。
e:Poppy 臂绘制“MIT”字母,平均误差小于 6mm。
f:将学习的雅可比场与物理仿真(Drake)计算的解析雅可比对比,平均角度误差仅 7°。
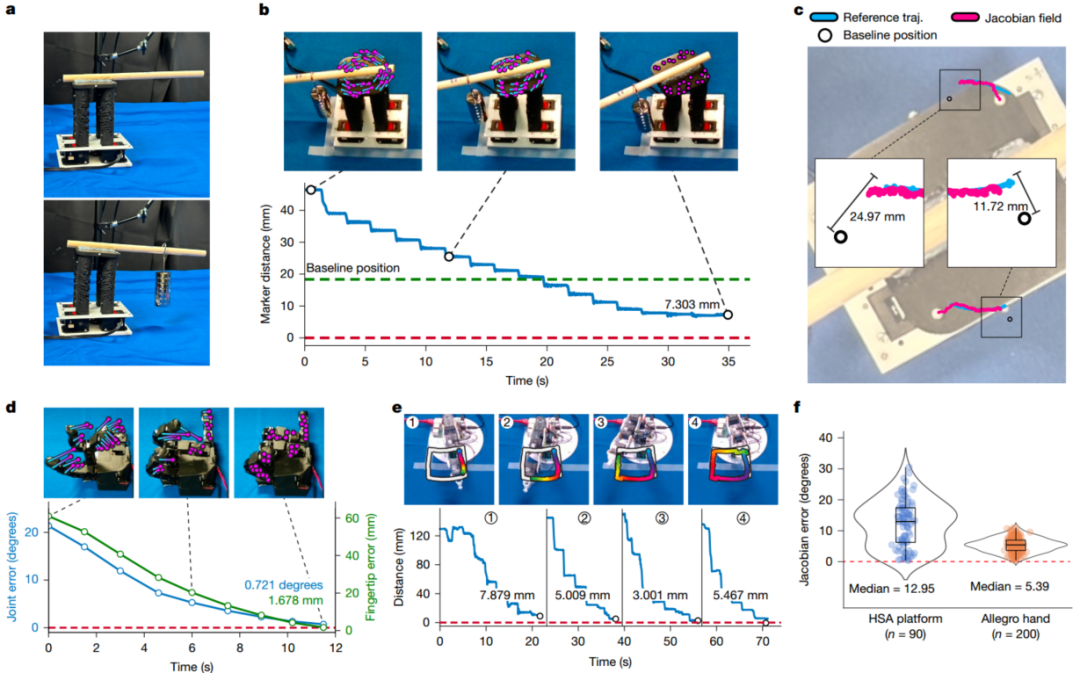
图 4 定量分析和弹性测试。首先,我们修改了HSA平台的动力。我们在平台上连接了一个杆,并在一个受控的位置附加了350的重物,使平台在其静止位置倾斜。b,Top,我们的框架使得改变了动力学的HSA系统完成了旋转运动。下图显示了一段时间内离目标的距离。c,使用鸟瞰图,我们覆盖了完整的3D轨迹(traj。)在HSA平台的初始配置之上。我们将我们方法的执行轨迹与参考轨迹进行了比较。这种可视化证实了我们的方法能够抵消重量的物理效应,并稳定朝向目标路径的运动轨迹。当我们执行动作计划时,快板手与目标的距离随着时间的推移而减少。我们使用以度为单位的关节误差和以毫米为单位的指尖位置来测量与目标的距离。e,顶部,在正方形绘制任务中,参考轨迹以白色显示,完成的轨迹以彩色显示。底部,在四个轨迹段中使用Poppy机械臂时与目标的距离。f,我们的雅可比预测与使用物理模拟计算的分析结果的比较47,48。我们的方法从原始RGB观察中学习一致的雅可比测量。
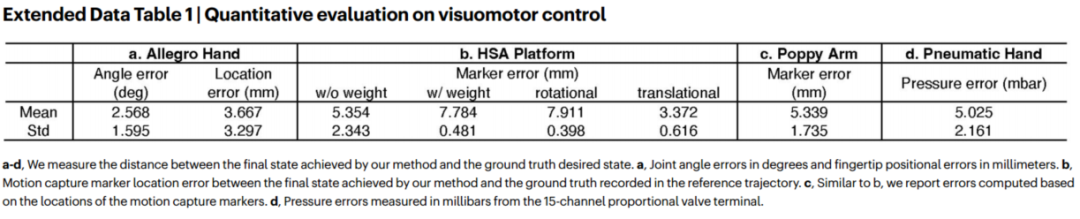
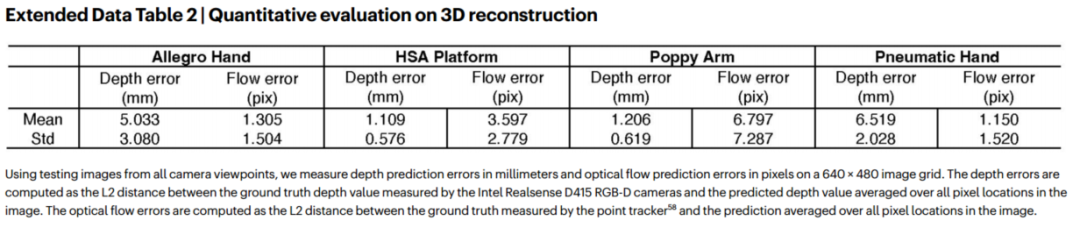
Extended Data Table 1 汇总了各平台的控制精度(关节角误差、位置误差、压力误差等),Extended Data Table 2 给出了几何重建的深度误差和光流误差。
03 创新点
①雅可比场——机器人学的新表示
传统雅可比矩阵是“状态对指令”的灵敏度,而雅可比场是“3D 空间点对指令”的灵敏度。这种稠密、与状态解耦的表示,绕开了软体机器人状态建模的难题。雅可比场的线性性质、空间局部性和可组合性天然契合机械系统的物理规律,使模型能从有限数据中泛化到未见构型和指令。
②单视角到3D的端到端学习
结合 pixelNeRF 和可微渲染,仅用 RGB‑D 视频自监督训练,无需运动捕捉或关节传感器。训练后仅需一个普通摄像头即可部署,极大降低了机器人控制的门槛。
③惊人的跨平台通用性
从几百美元的 3D 打印臂到数千美元的灵巧手,从气动软体到刚性多关节,一套算法、超参数不变,全部成功。论文还刻意测试了严重 backlash(Poppy 臂)和外部负载(HSA 平台)等极端情况,依然保持稳定。
④演示迁移能力
利用 3D 重建,能将一个视角的演示视频迁移到另一视角执行。这为“看一遍就会”的机器人学习提供了新路径。
⑤与解析模型的可比性
在 Allegro 手上,学习到的雅可比场与基于 URDF 的物理仿真结果高度一致(平均误差 7°),验证了方法学习的动力学结构是正确的。
04 总结与展望
这篇 Nature 文章给人的第一印象是“大道至简”。作者没有发明更复杂的神经网络,而是巧妙地重构了机器人学的基本概念——雅可比矩阵——把它从“状态的导数”变成“空间的场”。这一转变,结合神经渲染的强大表达能力,让机器人控制不再依赖专家建模。可以想象,未来一个普通用户用手机拍一段机器人运动的视频,系统就能学会控制它——这将对工业自动化、教育机器人、家庭服务机器人产生深远影响。
当然,方法也有局限性:训练需要 12 个相机采集 2‑3 小时,虽然无监督但设备要求不低;目前假设准静态运动(每个指令后等待稳定),尚未处理动态效应;对移动机器人(如腿足)可能无法从单目推断地面接触状态。
未来研究将聚焦于以下几个方向:
🔸动态扩展:将雅可比场推广到非稳态动力学,支持连续高速运动。
🔸减少训练视角:探索从单目或少量视角学习 3D 雅可比场,降低部署成本。
🔸多传感器融合:加入触觉、力/扭矩信息,应对遮挡和接触丰富的操作。
🔸端到端策略学习:利用雅可比场作为表示学习模块,直接学习视觉‑动作策略。
🔸腿式机器人推广:处理地面接触与运动学闭合链带来的挑战。
如果您面对一个从未见过的软体机器人(比如气动、磁驱或形状记忆合金驱动),您会尝试用数据驱动方法吗?欢迎在评论区分享您的看法。
训练数据可在以下网址公开获取:https://huggingface.co/datasets/sizhe-lester-li/neural-jacobian-field/tree/main.
训练视觉运动雅可比场、将其部署在机器人上并再现结果的完整源代码可在GitHub上获得,网址为https://github.com/sizhe-li/neural-jacobian-field.
完整源代码的百度网盘获取文件:neural-jacobian-field-main.zip
链接: https://pan.baidu.com/s/1EBRmUbIK5kNapoBRmh9FAA?pwd=1234提取码: 1234
声明:本文仅供学术交流,版权归原作者所有。如有错误或侵权,请联系更正或删除,欢迎留言探讨。




![人族和机器人第一次战争开启了[抠鼻]](http://image.uczzd.cn/15687064704896415685.jpg?id=0)

![[呲牙笑]原来不叫“机器狼”或者“机器狗”啊,正式名称叫做“察打一体型四足机器人](http://image.uczzd.cn/4477809235408250229.jpg?id=0)