
本文第一作者闫峻溪为清华大学 FAITH Lab 预科博士生,师从詹靖涛助理教授。FAITH Lab(Foundation of AI Lab at TsingHua)由詹靖涛教授创立,致力于探索人工智能的基本原理,旨在揭示智能系统背后的底层规律。实验室隶属于清华大学信息检索研究组(THUIR),研究方向涵盖大语言模型的理论基础与规模化规律。
规模定律(Scaling Law)一直是大语言模型开发的核心指导工具。从 Kaplan 等人提出的经典幂律关系,到 Chinchilla 团队对最优训练策略的计算,业界形成了共识:随着模型参数量的增长,交叉熵损失会以可预测的幂律速率持续下降。
然而,越来越多的研究者开始发现令人不安的现象:交叉熵规模定律在超大模型上失效了。损失的下降从幂律预测偏移,这让依赖Scaling Law来指导百亿甚至千亿参数模型训练的团队措手不及。
来自清华大学的研究团队在一篇发表在ICLR 2026上的论文中,对这一问题给出了一个颇具洞察力的回答:交叉熵损失本身并不真正遵循规模定律;真正scale的,是它内部一个隐藏的成分。
研究团队提出了一种全新的交叉熵分解方法,将其拆分为三个部分:误差熵(Error-Entropy)、自对齐(Self-Alignment)和置信度(Confidence)。通过在多个数据集上对 32 个模型进行系统实验,他们发现只有误差熵严格遵循幂律缩放,其余两项基本不随模型增大而变化。这一发现不仅为交叉熵规模定律失效提供了新的解释,也为大模型的训练和理论研究提供了一个更可靠的度量基准。
 论文地址:https://arxiv.org/abs/2510.04067
开源代码:https://github.com/yanjx2021/RethinkCE
论文地址:https://arxiv.org/abs/2510.04067
开源代码:https://github.com/yanjx2021/RethinkCE 拆解交叉熵:从排名出发的新视角
为什么交叉熵规模定律会在大模型上失效?论文的核心观点是:交叉熵本身是一个"混合度量",其中只有一部分真正随模型规模改善,另外的部分则形成了干扰。要看清这一点,需要把交叉熵拆开。
研究者为此提出了一个新指标:基于排名的误差(Rank-based Error, RBE)。与交叉熵关注正确 token 的概率得分不同,RBE 直接衡量正确 token 在模型输出中的排名位置。例如,如果有 4 个 token 的得分高于正确答案,那么 RBE 就等于 4。
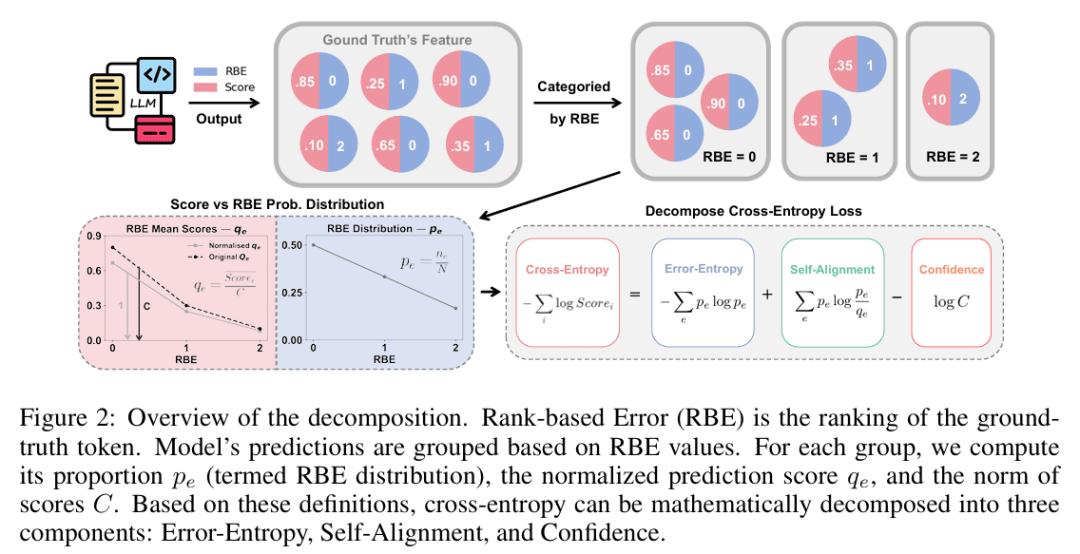
选择排名而非概率,是因为概率值很容易被推理阶段的后处理操作(如温度缩放、top-k 采样)所改变,但 token 之间的相对排序不会被影响。因此,排名是一个更为稳健的模型能力指标。

误差熵(Error-Entropy):衡量 RBE 分布的香农熵。优化模型会让正确 token 尽可能排在前面,即模型学会「区分对错」。当模型完全不知道哪个 token 正确时,RBE 分布接近均匀分布,此时误差熵最大。
自对齐(Self-Alignment):刻画模型概率得分与 RBE 分布之间的对齐程度。优化这一项,要求模型给排名越高的 token 分配越高的概率,使概率分布与排名分布保持一致。
置信度(Confidence):反映模型输出概率得分的整体大小,优化这一项意味着模型整体输出的分数更自信。
训练动态验证
论文通过观察完整训练过程来验证分解的合理性。实验显示,三个成分在训练中呈现出清晰的优化顺序:模型在训练早期首先集中降低误差熵,在其下降一段时间之后才开始显著优化自对齐和置信度初始。
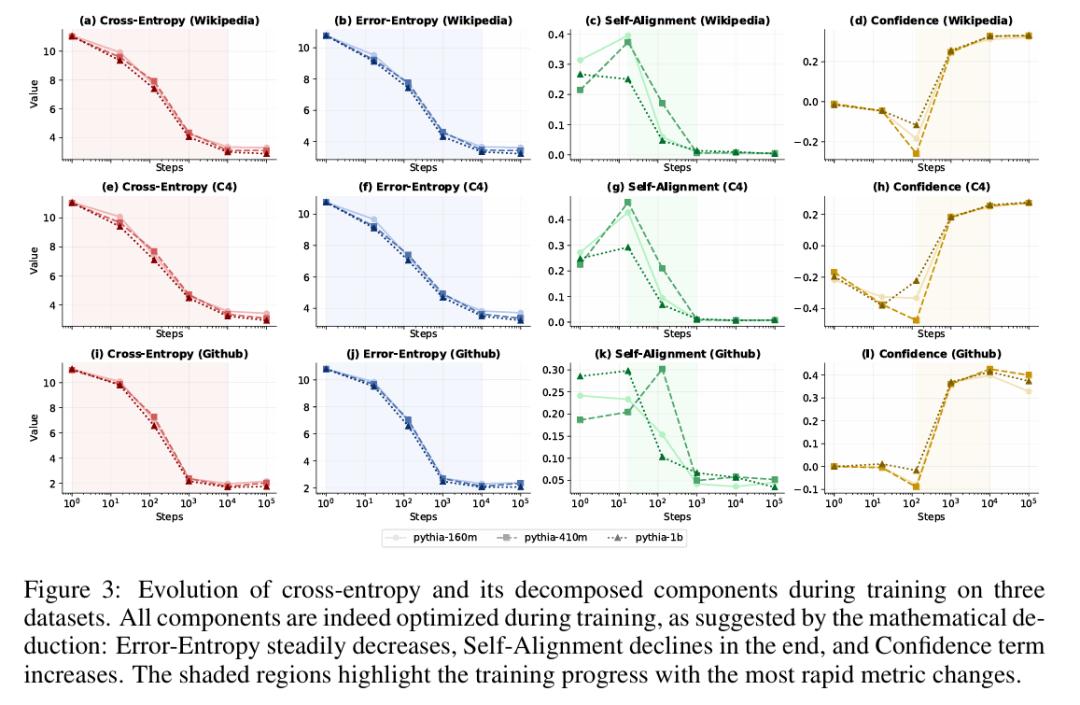
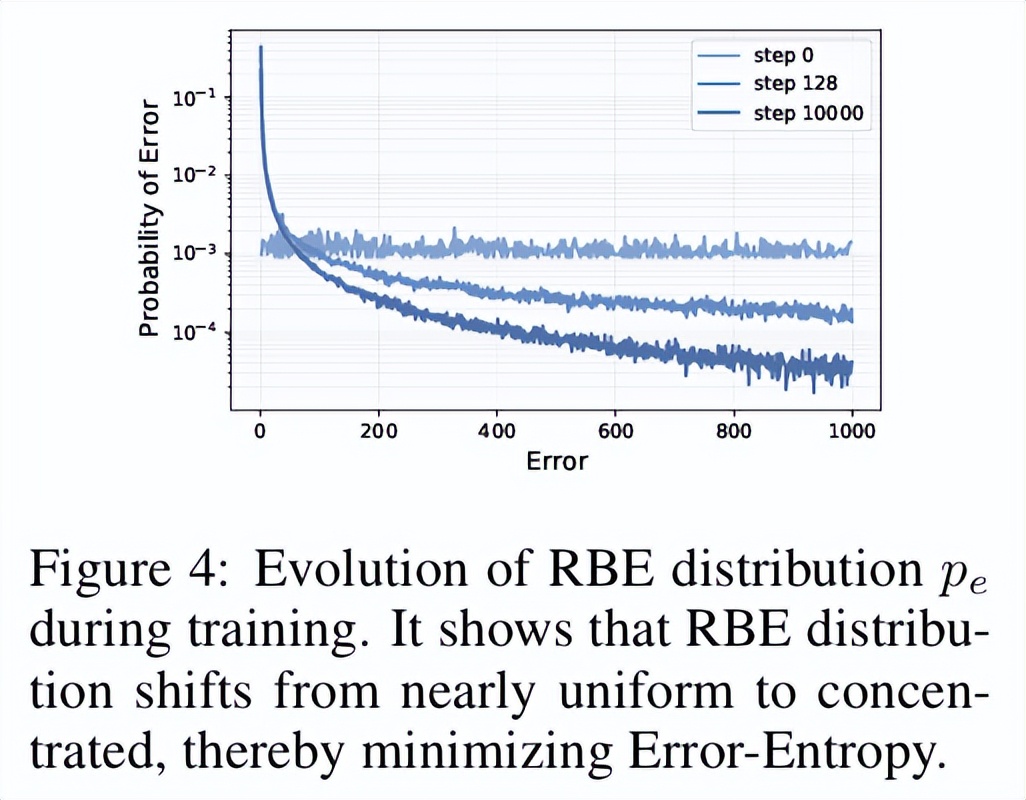
进一步深入每个成分的细节:在训练初期,RBE 分布接近均匀,模型对哪个 token 正确几乎一无所知,排名近乎随机。随着训练推进,RBE 分布逐步向头部集中,正确 token 被越来越多地排到前列,误差熵因此持续下降。

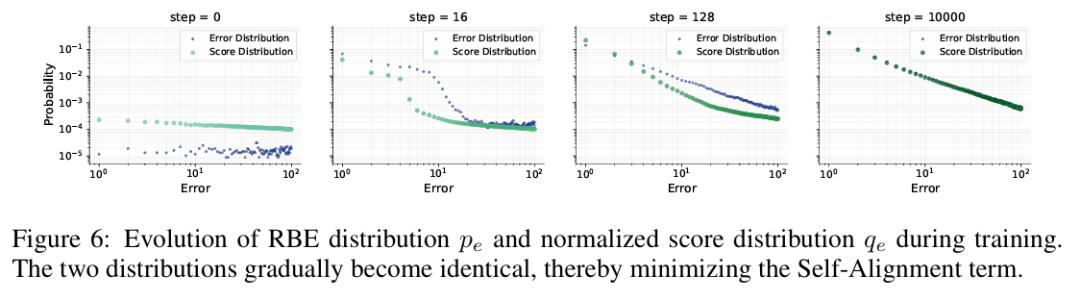
置信度方面,排名低于正确 token 的候选词得分在训练中被系统性压低,正确与错误 token 之间的分数差距不断拉大。模型在学会排序之后,进一步学会了"拉开差距"。

值得注意的是,自对齐和置信度都与概率数值紧密相关,而误差熵直接刻画排序准确度(不受采样策略影响),是三者中最能忠实反映模型真实性能的成分。
只有误差熵在缩放
研究者进一步在 Wikipedia、C4、The Pile 的 GitHub子集三个数据集上,使用 32 个预训练模型(规模从数百万到数百亿参数),系统检验了交叉熵及其三个分解成分随模型规模的变化趋势。

结果非常清晰:在对数-对数坐标下,误差熵呈现接近线性的下降趋势,与模型参数量之间存在稳健的幂律关系。
与之相反,自对齐项在模型增大时没有改善,反而轻微上升;置信度项则波动较大,缺乏一致的变化规律。
研究者由此提出了「误差熵规模定律」(Error-Entropy Scaling Law):在交叉熵的三个成分中,只有误差熵真正遵循幂律缩放。
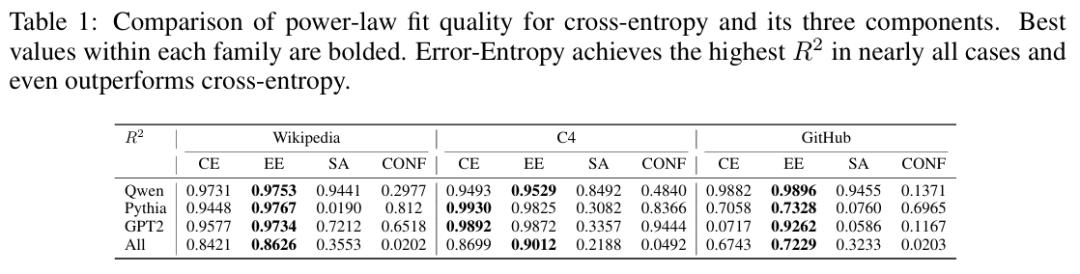
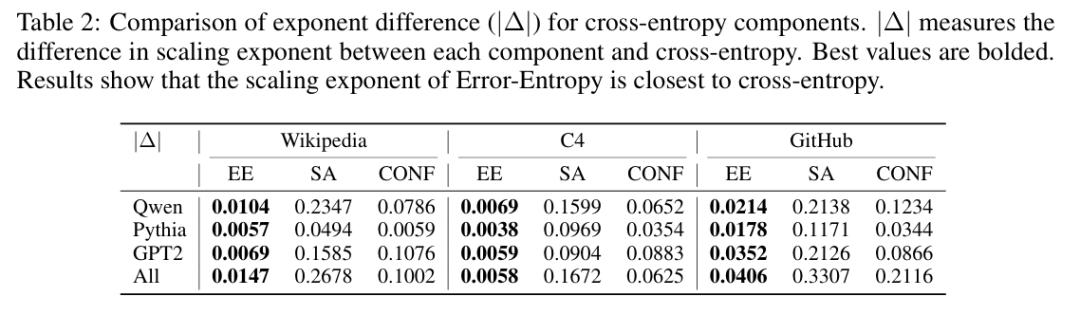
定量拟合的结果进一步验证了这一结论。论文使用标准幂律模型对各成分进行拟合后发现,误差熵的拟合优度在所有数据集上均显著高于交叉熵本身。这说明交叉熵之所以「看起来像」在缩放,本质上是因为误差熵在驱动整体趋势,而自对齐和置信度带来的噪声削弱了拟合精度。
破解大模型规模定律失效之谜
研究者利用这一发现回答了开头提出的关键问题:交叉熵规模定律为什么在大模型上失效?
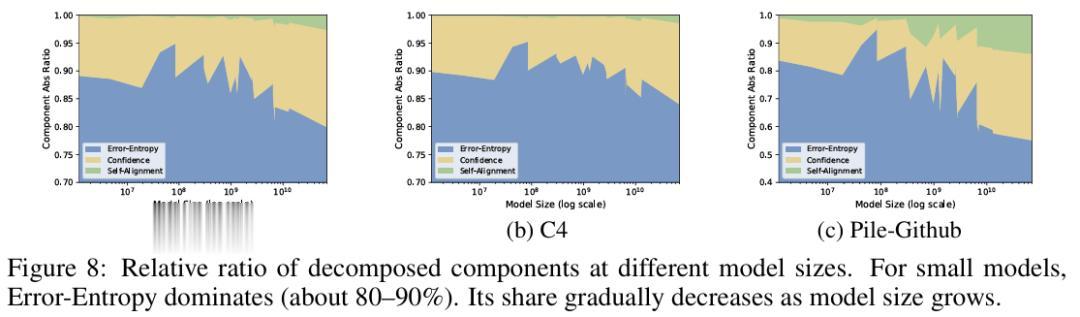
答案藏在三个成分的比例结构中。在小模型中,误差熵占据了交叉熵总量的近 90%。由于误差熵遵循幂律,整体交叉熵自然也表现出良好的幂律趋势。
然而随着模型规模增大,误差熵占总损失的比例逐渐下降,而不遵循缩放规律的自对齐和置信度项占比相应上升。对于大模型来说,交叉熵中有越来越大的比例来自不缩放的成分。
这些不缩放的成分像是叠加在幂律趋势上的“噪声地板”,使得交叉熵偏离了纯粹的幂律预测。模型越大,偏差越显著——这正是业界观察到的"规模定律失效"现象。
误差熵的启发
除了解释规模定律的失效机制,这一研究也为实践和理论带来了新的可能。
在训练层面,既然误差熵才是真正随规模改善的成分,那么直接以误差熵作为训练信号或评估指标,或许比交叉熵能更准确地反映模型能力的提升,从而指导更高效的训练策略和资源分配。
在理论层面,这一分解揭示了一个更深层的原则:模型规模的增长本质上提升的是排序能力,而非概率校准能力。这或许能为理解大模型的能力边界和优化方向提供新的指引。
更多细节请参阅原论文。





