《GPU utilisation and performance improvements》
深入理解 GPU 的性能瓶颈,提升 VALU 单元利用率是渲染性能优化的核心。
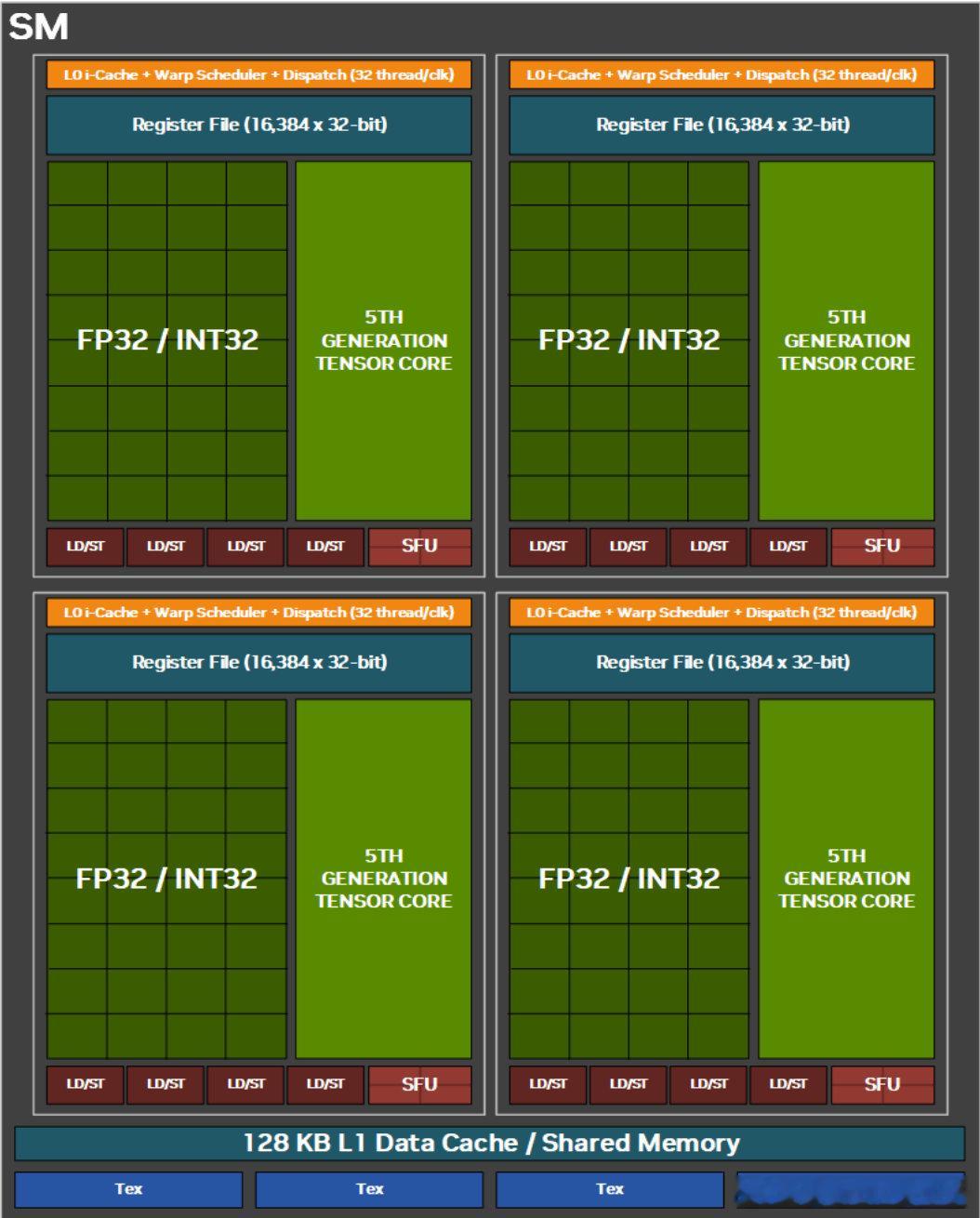
• GPU 核心为大量 SIMD 单元(Nvidia叫 SM,AMD叫 WGP),负责执行向量/标量 ALU 运算,保持这些单元满载是关键。
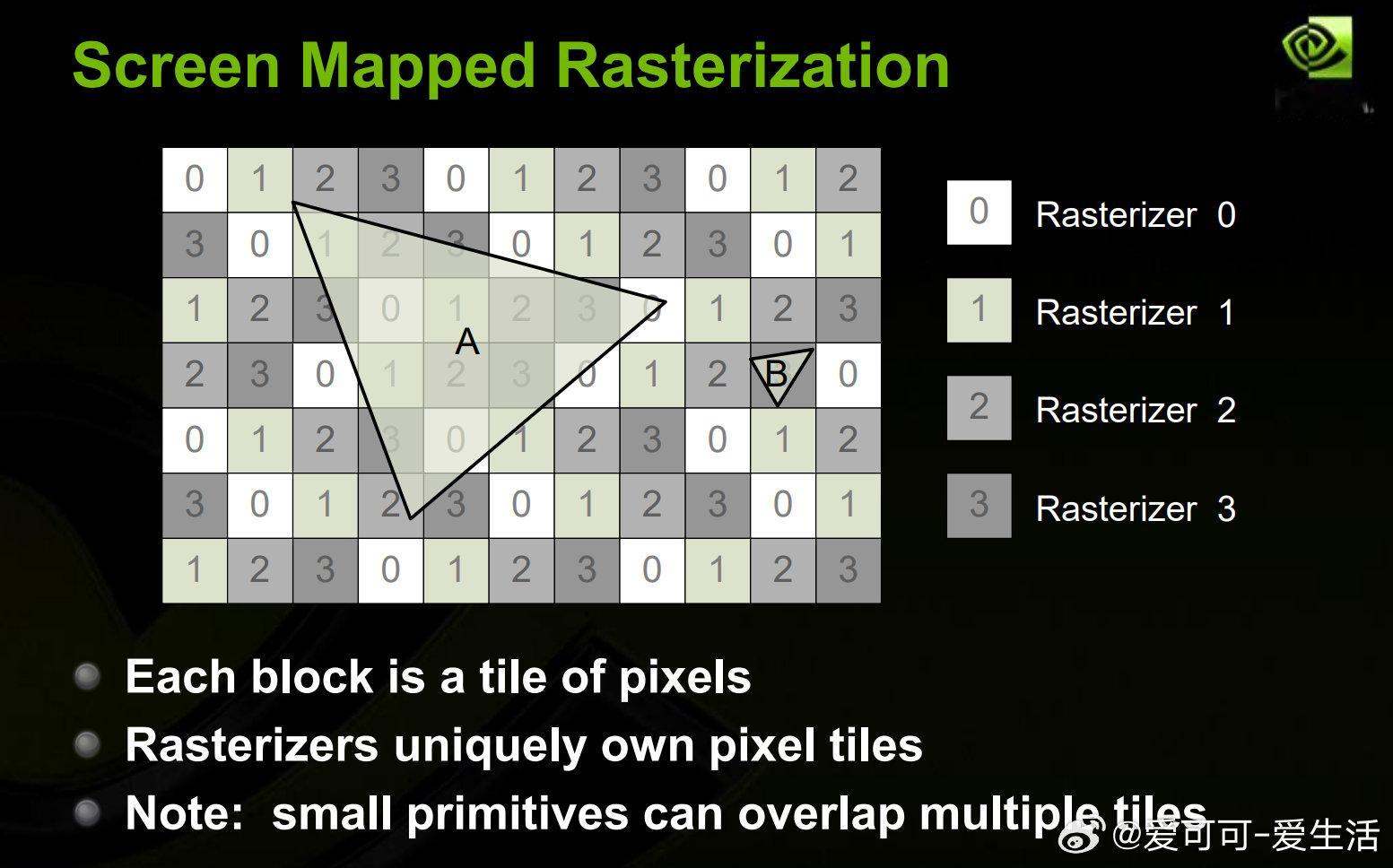
• 固定功能单元(如 TEX、ROP、寄存器文件、缓存)虽速度快但易成为瓶颈,限制 VALU 单元数据读写能力。
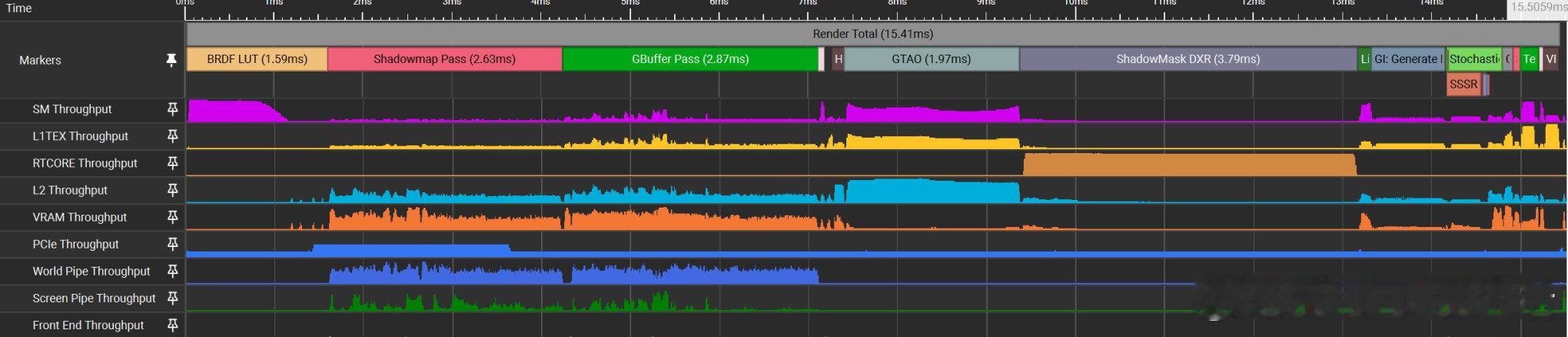
• 通过分析具体渲染任务的瓶颈(如内存带宽、顶点输入、缓存或光线追踪核心),精准定位性能瓶颈是首要步骤。
• 优化重点包括减少 VGPR 分配、调整数据结构(Structured Buffer 优于 Constant Buffer)、压缩输入输出数据、重构循环以提升指令间内存访问效率。
• 高 occupancy 不总是好事,可能导致缓存抖动,适当增加 VGPR 或分配 LDS 内存限制并发线程数,有助于提升整体吞吐。
• 选择合适的着色器类型:像素着色器依赖固定功能单元,适合硬件加速路径;计算着色器可绕过部分瓶颈,使用 groupshared 内存并支持异步计算提高资源利用。
• 异步计算(Async Compute)利用并行执行不同任务,缓解单一管线瓶颈,但需平衡优先级和线程组大小,避免影响主图形管线。
• 结合硬件架构差异(如 RDNA 的波形大小差异)调整着色器设计,有时反直觉地降低并发度或改变波形尺寸能带来性能跃升。
• 性能优化是系统性工作,单点优化可能不足,需综合视角评估全帧渲染任务的资源分配和瓶颈转移。
三大启发:
1. 性能瓶颈极具多样性且动态变化,单纯提升某个阶段效率可能无效,整体调度和资源协调更重要。
2. 硬件特性深刻影响优化策略,通用方法难以覆盖所有 GPU,必须结合具体架构和内容反复验证。
3. 异步执行和合理资源限制能打破传统流水线瓶颈,提升整体 GPU 计算吞吐,值得纳入复杂渲染管线设计。
了解更多技术细节及案例👉 interplayoflight.wordpress.com/2025/08/29/gpu-utilisation-and-performance-improvements/
GPU优化 图形渲染 着色器编程 异步计算 高性能计算