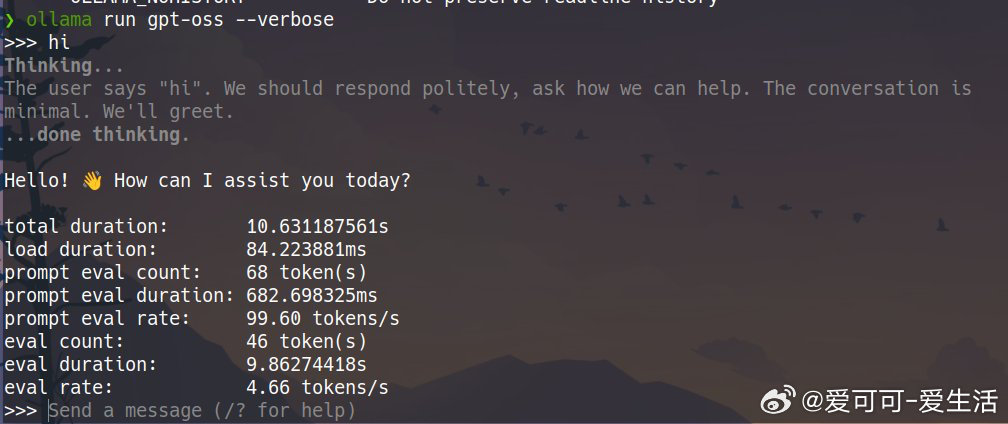
本地运行大型语言模型(如 gpt-oss:20b)在不同硬件环境下的性能表现与优化建议:
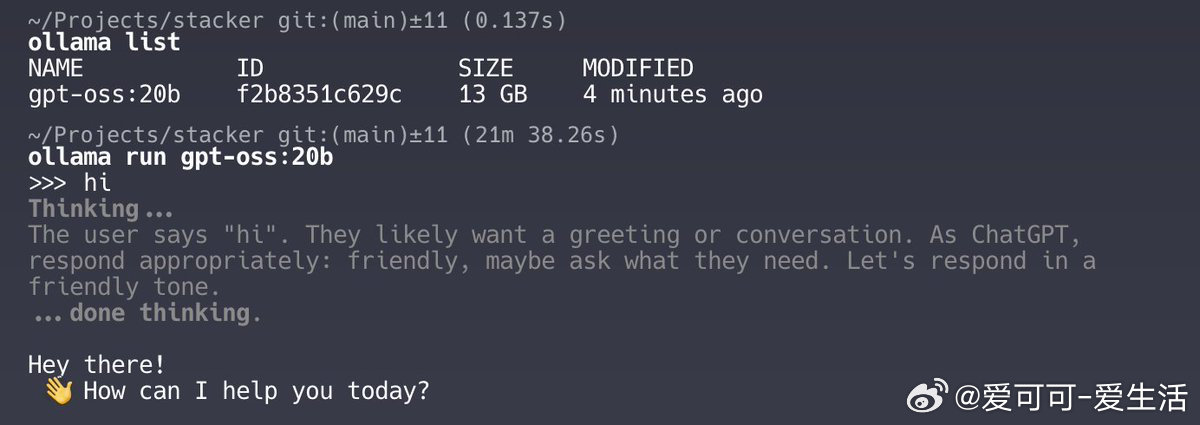
• 在苹果 M1 MacBook Pro 上运行 gpt-oss:20b,响应时间长达21分钟,主要因内存不足(8GB或16GB)导致频繁磁盘交换,严重拖慢推理速度。该模型至少需要16GB以上内存才能流畅运行。
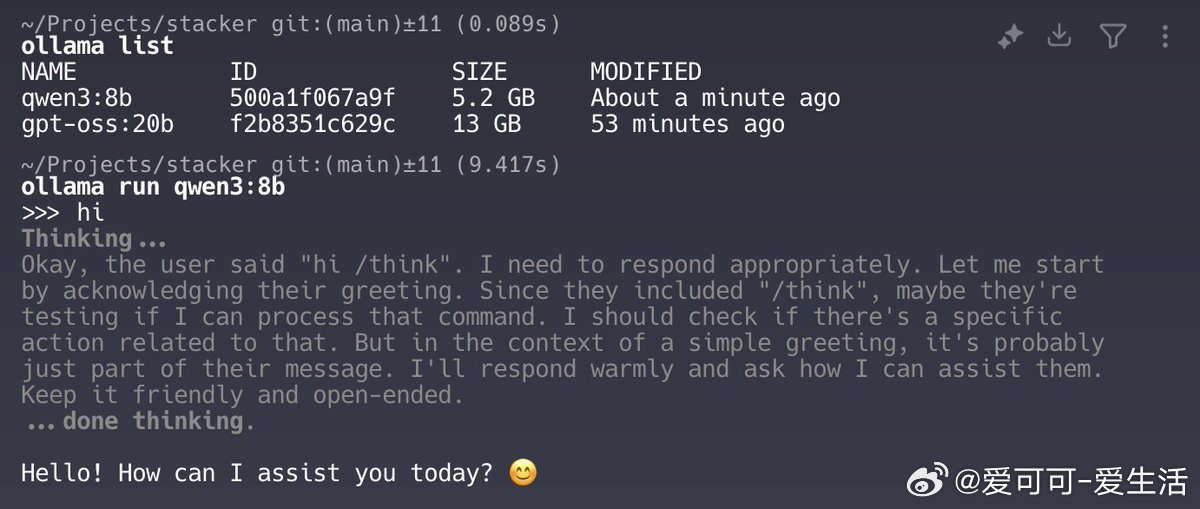
• 对比之下,qwen3:8b 模型在类似设备上仅需9秒,显示模型规模与硬件匹配度直接影响推理效率。
• 多位用户反馈,配备 M1 Max / M4 Max 芯片与64GB以上内存的机器运行速度显著提升,部分达到几十tokens每秒(tps),体验接近实时。
• 优化方案推荐:
- 使用4-bit量化(q4_k_m)技术,显著缩短推理时间(可从20分钟降至2-3分钟)。
- 采用 llama.cpp 等轻量级框架,提升苹果硅芯片上的执行效率。
- 选择云端加速服务(如 Groq),以0.59美元/百万tokens的成本换取超过150 tps的推理速度,适合资源受限时使用。
- 避免在内存不足设备上运行大型20B参数模型,推荐升级硬件或调整模型规模。
• 其他硬件对比:
- Ryzen 5 3600X + 32GB RAM + NVIDIA GeForce GT 710配置能在几秒内完成推理,说明CPU+充足内存也能实现较好性能,且不一定依赖高端GPU。
- 树莓派4也有用户实现秒级响应,表明模型轻量级版本或优化框架的潜力。
• 结论:大型语言模型推理速度关键受限于内存容量与运行框架优化,硬件升级+量化技术是提升本地推理体验的有效路径。合理匹配模型规模与硬件资源,结合云端加速服务,可实现实用的本地AI应用。
详情🔗 x.com/AlexReibman/status/1952855048960250192
本地AI 大型语言模型 模型优化 苹果芯片 量化技术 推理速度 硬件升级