qwen600:一个专注于单批次、纯 CUDA 加速的 QWEN3-0.6B 微型推理引擎,专为 RTX 3050 8GB 显卡优化,兼具极简设计与高效性能。
• 完全用 CUDA C/C++ 编写,无 Python 依赖(仅 tokenizer 转换脚本需 Python),极简依赖:cuBLAS、CUB、标准 IO。
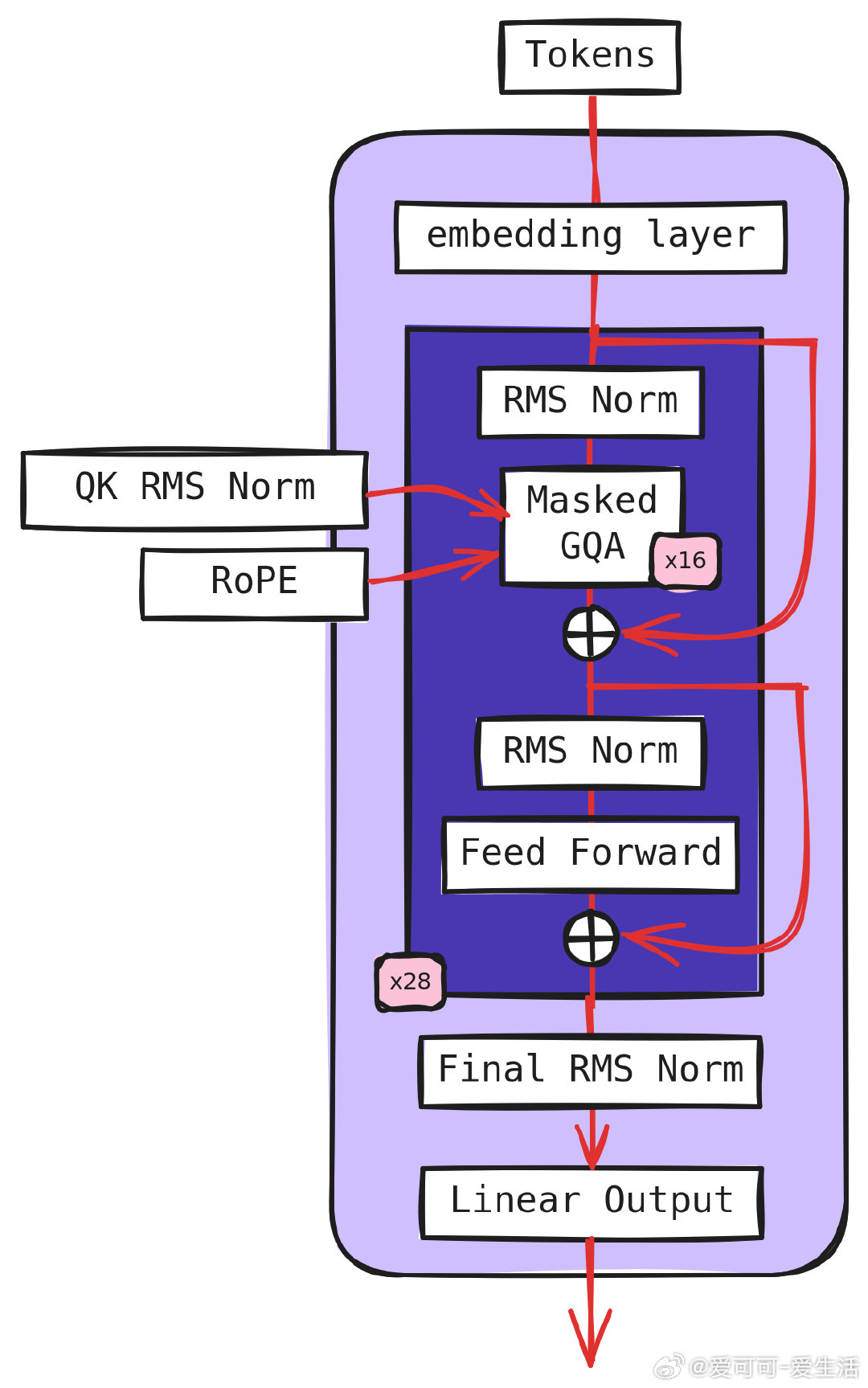
• 静态常量设计,编译时优化极致提升性能——推理速度较 llama.cpp 快约 8.5%,比 HF + flash-attn 快近 3 倍,适合边学边用的 CUDA GPGPU 教育项目。
• 高效显存管理:mmap 内存映射、单 GPU Block 异步拷贝与零成本指针权重管理,内存访问与调度极简且高效。
• 设计灵感来源于 llama.cpp、llama2.c、LLMs-from-scratch 等,遵循“suckless”极简主义哲学,避免功能膨胀与抽象复杂度。
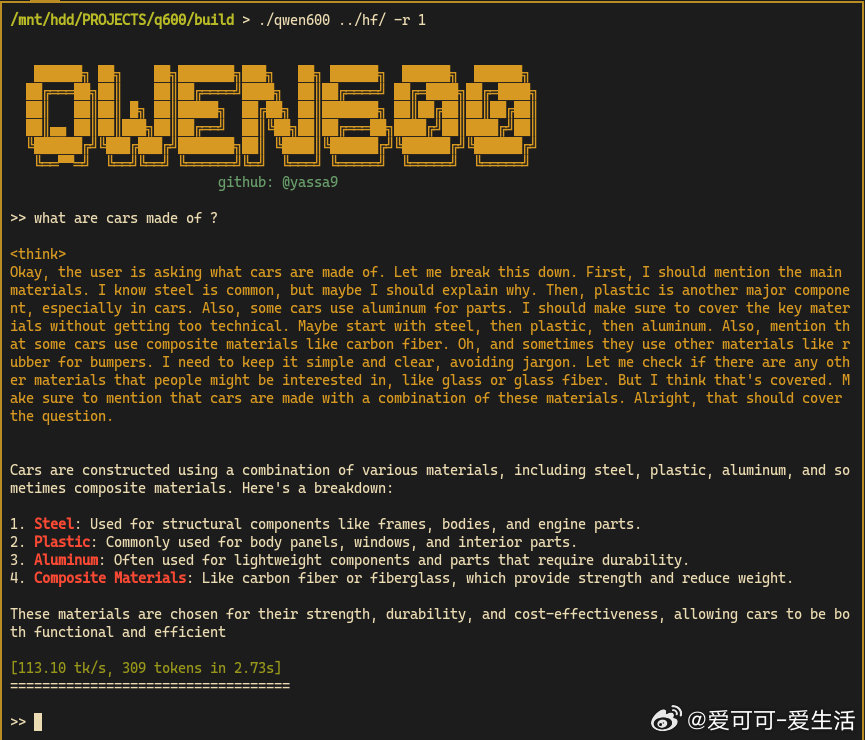
• 支持思考模式(-r 1)和非思考模式(-r 0),配套合理采样(TopK、TopP、温度)参数,避免贪婪解码带来的输出重复和性能退化。
• 完全开源 MIT 许可,适合学习 CUDA 编程与 Transformer 推理机制的开发者,代码配置直观,依赖极少,易于定制和扩展。
• 目前仍在完善中,计划融合更多 CUDA 优化(RMSnorm、skip connection 融合、Softmax kernel 优化、RoPE 预计算),为高性能推理铺路。
适合想深入理解 CUDA GPU 编程与 LLM 推理交叉领域的研究者与开发者,低门槛、高性能、极简且透明的架构设计,助你从零开始构建自定义推理引擎。
了解详情🔗 github.com/yassa9/qwen600
CUDA 深度学习 大模型推理 GPU加速 开源项目 AI开发