Sebastian Raschka的一篇新教程:如何通过多种优化技术提升PyTorch在训练大型语言模型(LLM)时的性能?
github.com/rasbt/LLMs-from-scratch/tree/main/ch05/10_llm-training-speed
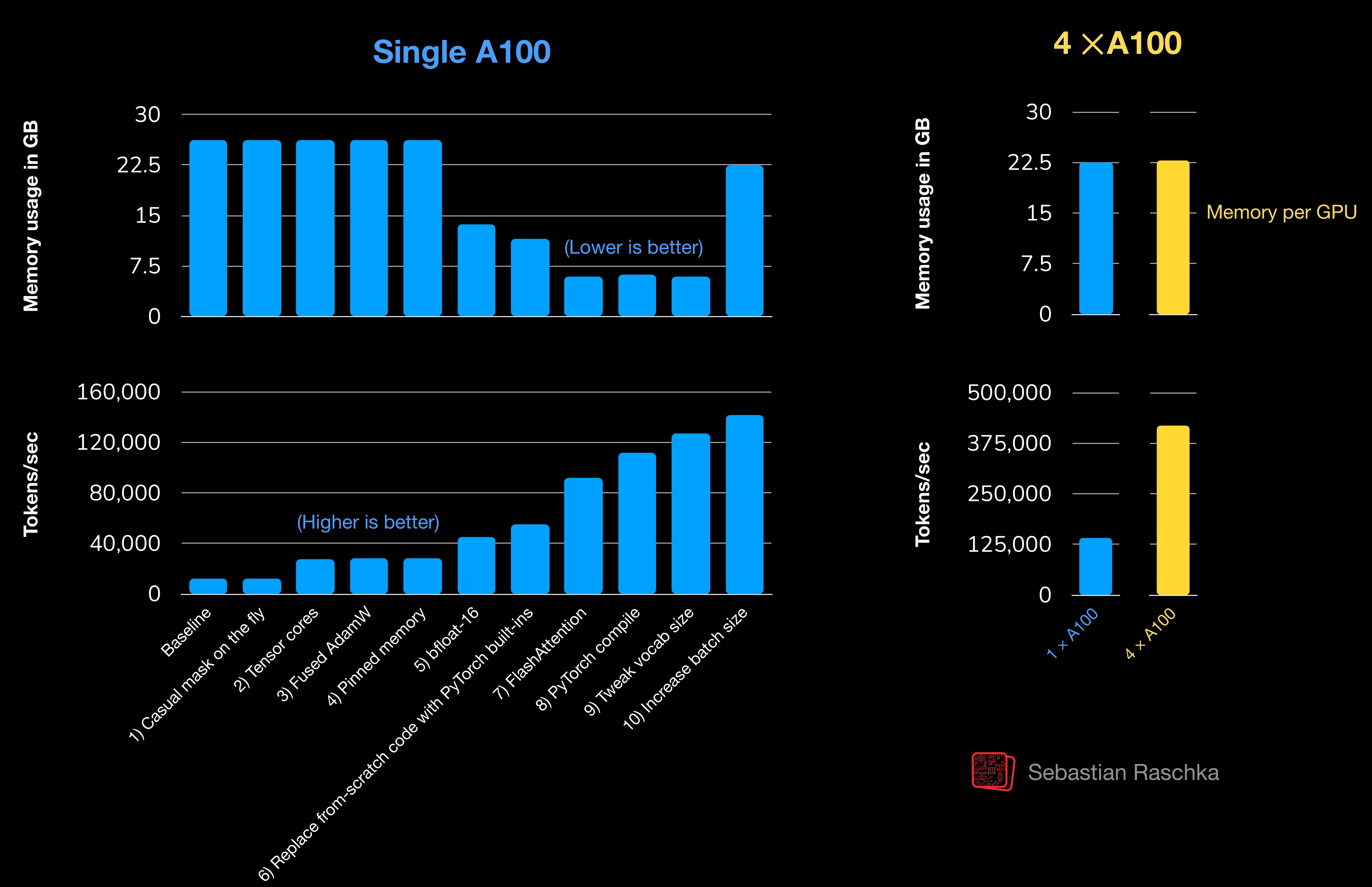
教程提供了三个代码文件,分别展示了原始代码、单GPU优化代码和多GPU优化代码。通过一系列优化措施,如使用张量核心、融合AdamW优化器、使用bfloat16精度、替换自定义实现为PyTorch原生实现、使用FlashAttention、编译模型等,训练速度从每秒12,525个token提升到142,156个token(单A100),在4个A100 GPU上更是达到了每秒419,259个token。文章还计划未来详细解释这些优化措施的差异。
ai创造营