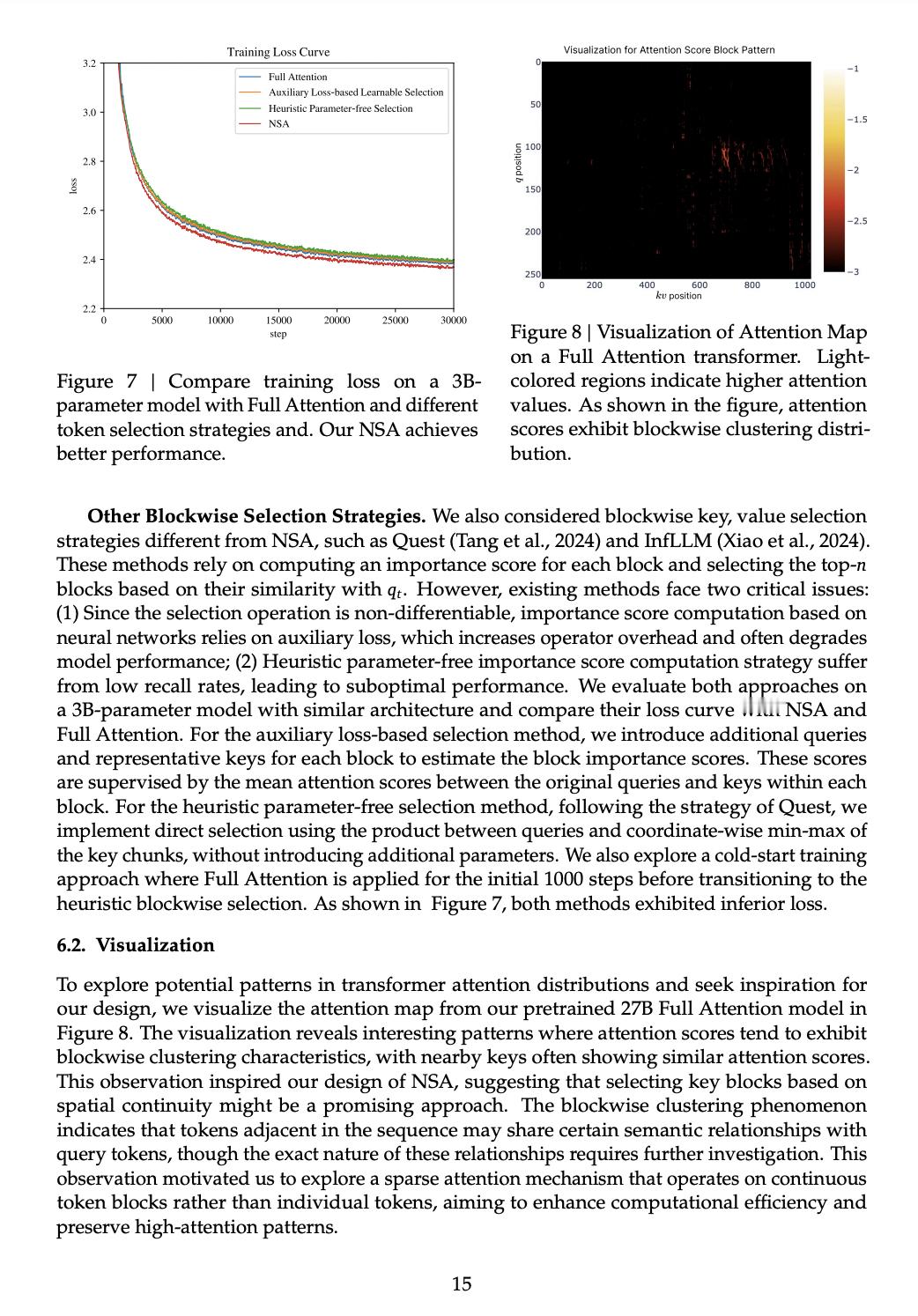
看了一下 DeepSeek 的最新论文” Native Sparse Attention",核心思想就是对训练的数据通过空间序列块的方式进行压缩
因为他们发现其具有非常明显的稀疏特性(图二)
诸位,其实这些原理在1992年的历史压缩的论文里就提到了,而且采用其方法可以降低训练样本规模200倍,逻辑推理从少于五步达到快速完成20步
这些其实就是压缩感知,即找到一种算法,能够对大规模的数据进行高效压缩,历史压缩的方法也是动态自适应层级的
所以,其实搞大语言模型的应该要调整思路了,提升算法性能的重要方向就是压缩感知理论
.