目前看到对DeepSeek真实水平最全面客观的分析(4)
摘自基本常识
缩小差距 ——V3 的性能
V3 无疑是一款令人印象深刻的模型,但值得注意的是,要明确它是相对于什么而言令人印象深刻。许多人将 V3 与 GPT-4o 进行比较,并强调 V3 如何超越 4o 的性能。这确实没错,但 GPT-4o 于 2024 年 5 月发布。人工智能发展迅速,从算法改进的角度来看,2024 年 5 月恍如隔世。而且,经过一段时间后,用更少的计算资源实现相当或更强的能力,这并不令人意外。推理成本的下降是人工智能进步的一个标志。
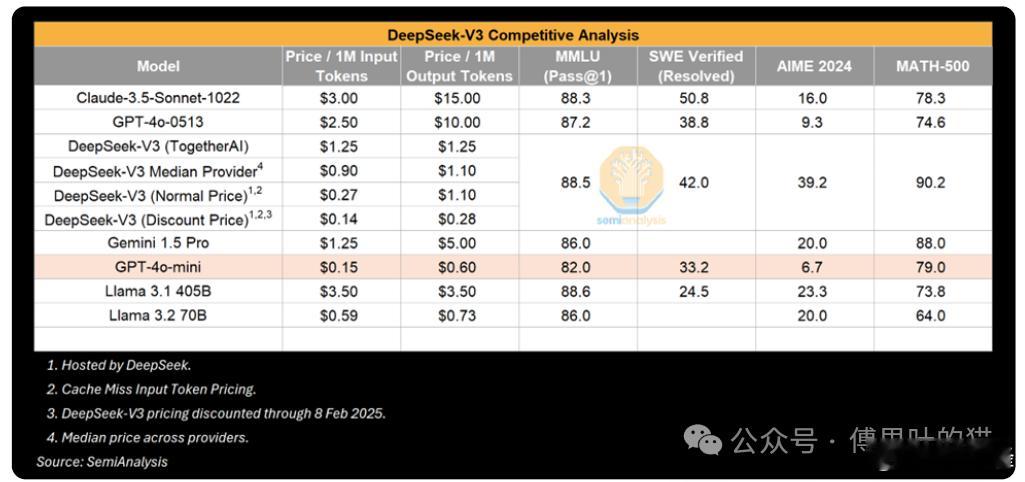
深度求索 V3 的竞争分析
例如,能在笔记本电脑上运行的小型模型,其性能可与 GPT-3 相媲美,而 GPT-3 的训练需要超级计算机,推理则需要多个 GPU。换句话说,算法的改进使得用更少的计算资源来训练和推理具有相同能力的模型成为可能,这种模式反复出现。这次全世界之所以关注,是因为它来自中国的一个实验室。但小型模型性能提升并非新鲜事。
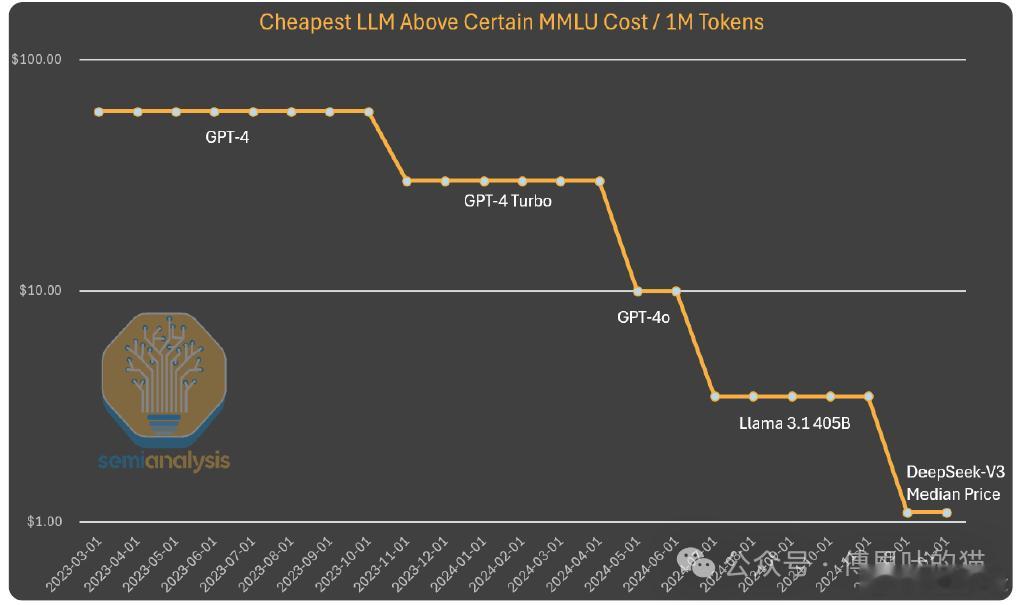
到目前为止,我们从这种模式中看到,人工智能实验室为了获得更高的智能水平,在绝对金额上的投入越来越多。据估计,算法的进步意味着每年实现相同能力所需的计算资源减少 4 倍。Anthropic 的首席执行官 Dario 认为,算法定价在朝着 GPT-3 质量发展,成本已下降 1200 倍。就推理而言,甚至可以实现 10 倍的改进。
在研究 GPT-4 的成本时,我们也看到了类似的成本下降趋势,不过处于曲线的更早期阶段。虽然随着时间推移成本差异的缩小,不能像上面的图表那样通过保持能力不变来解释。在这种情况下,我们看到算法改进和优化使成本降低了 10 倍,同时能力也有所提升。
需要明确的是,深度求索的独特之处在于他们率先达到了这样的成本和能力水平。他们发布开放权重的做法也很独特,不过之前 Mistral 和 Llama 模型也有过类似举措。深度求索达到了这样的成本水平,但到今年年底,如果成本再下降 5 倍,也不要感到惊讶。
另一方面,R1 能够取得与 o1 相当的结果,而 o1 直到 9 月才发布。深度求索是如何这么快就追赶上的呢?
答案是,推理是一种新范式,与之前的预训练范式相比,它的迭代速度更快,且更容易实现较小计算量下的显著提升,而之前的预训练范式成本越来越高,且难以取得稳健的进展。如我们在报告中所述,之前的范式依赖于规模定律。
新范式通过在现有模型的训练后阶段,利用合成数据生成和强化学习来提升推理能力,能够以更低的成本实现更快的进步。较低的进入门槛和易于优化的特点,使得深度求索能够比往常更快地复制 o1 的方法。随着参与者在这种新范式中找到更多扩展方法,我们预计实现相同能力所需的时间差距将会扩大。
需要注意的是,R1 的论文中并未提及所使用的计算资源。这并非偶然 —— 为训练后的 R1 生成合成数据需要大量计算资源,更不用说强化学习了。我们并不否认 R1 是一款非常优秀的模型,能如此迅速地在推理能力上追赶上令人钦佩。深度求索作为一家中国公司,用更少的资源实现了追赶,这更是令人赞叹。
但 R1 提到的一些基准测试也具有误导性。将 R1 与 o1 进行比较很棘手,因为 R1 特别没有提及那些自己不领先的基准测试。虽然 R1 在推理性能上与 o1 相当,但它并非在所有指标上都是明显的赢家,在很多情况下甚至不如 o1。
我们还没有提到 o3。o3 的能力明显高于 R1 和 o1。事实上,OpenAI 最近公布了 o3 的结果,其基准测试成绩直线上升。“深度学习遇到了瓶颈”,但却是另一种情况。