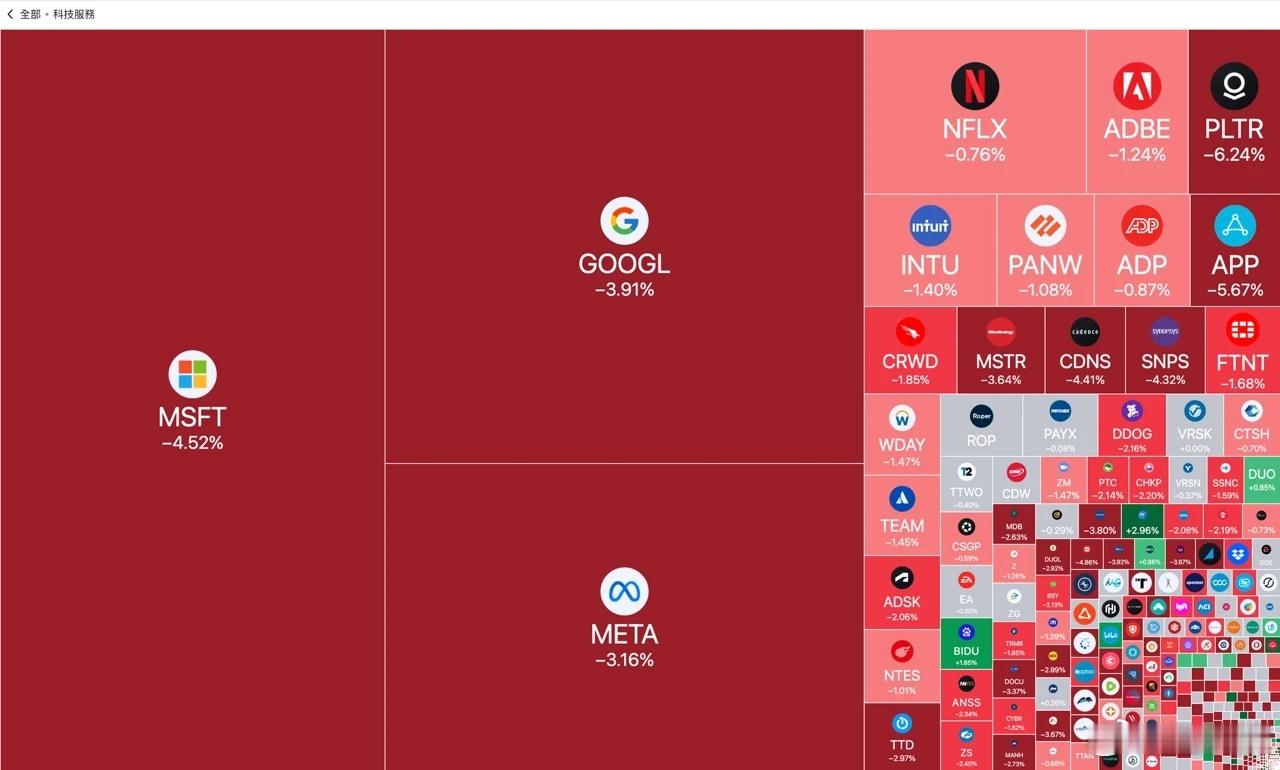
Anthropic CEO 发万字檄文:DeepSeek 崛起,白宫应加码管制(上)
摘自金色传说大聪明 赛博禅心
就在刚刚,美国的另一家 AI 巨头 Anthropic 的 CEO - Dario Amodei 发表了一篇长达万字的深度分析报告。报告核心观点:DeepSeek 的突破,更加印证了美国对华芯片出口管制政策的必要性和紧迫性。
文章发布在 Dario Amodei 的个人博客
我把它也翻译成了中文,如下:
关于 DeepSeek 与出口管制
几周前,我曾撰文呼吁美国应加强对华芯片出口管制。此后不久,中国人工智能公司 DeepSeek 便成功地——至少在某些方面——以更低的成本,实现了与美国顶尖人工智能模型相近的性能水平。
在此,我暂且不讨论 DeepSeek 是否对 Anthropic 等美国人工智能企业构成威胁(尽管我认为许多关于 DeepSeek 威胁美国人工智能领导地位的说法被严重夸大了)。
我更关注的是,DeepSeek 的成果发布是否削弱了芯片出口管制政策的合理性。我的看法是否定的。事实上,我认为 DeepSeek 的进展反而令出口管制政策显得比一周前更具存在意义上的重要性。
出口管制服务于一个至关重要的目标:确保民主国家在人工智能发展中保持领先地位。需要明确的是,出口管制并非逃避美中竞争的手段。最终,如果美国和其他民主国家的 AI 公司想要胜出,就必须开发出比中国更卓越的模型。但是,在力所能及的情况下,我们不应将技术优势拱手让给中国。
人工智能发展的三大动态
在阐述我的政策主张之前,我将先介绍理解人工智能系统至关重要的三个基本动态:
规模定律 (Scaling laws)。 人工智能的一个特性——我和我的联合创始人在 OpenAI 工作时就率先记录了这一特性——即在其他条件相同的情况下,扩大人工智能系统的训练规模,能够全面且平滑地提升其在各种认知任务上的表现。
例如,一个耗资 100 万美元的模型可能解决 20%的重要编程任务,一个耗资 1000 万美元的模型可能解决 40%,一个耗资 1 亿美元的模型可能解决 60%,以此类推。这些差异在实践中往往具有巨大的影响——十倍的性能提升可能相当于本科生和博士生技能水平之间的差距——因此,各公司都在大力投资于训练这些模型。
曲线偏移 (Shifting the curve)。 人工智能领域不断涌现各种大大小小的创新理念,旨在提高效率或效能。这些创新可能体现在模型架构的改进上(例如对当今所有模型都采用的 Transformer 基础架构进行微调),也可能仅仅是更高效地在底层硬件上运行模型的方法。
新一代硬件的出现也具有相同的效果。这些创新通常会使成本曲线发生偏移:如果某项创新带来了 2 倍的“算力倍增效应”(CM),那么原本需要花费 1000 万美元才能完成 40%编程任务,现在只需 500 万美元即可实现;原本需要 1 亿美元才能完成 60%的任务,现在只需 5000 万美元,以此类推。每一家前沿人工智能公司都会定期发现许多这样的算力倍增效应:小型创新(约 1.2 倍)时有发生,中型创新(约 2 倍)也偶有出现,而大型创新(约 10 倍)则较为罕见。
由于拥有更智能系统的价值极高,这种曲线偏移通常会导致公司在模型训练上投入更多而非更少的资金:成本效率的提升最终完全用于训练更智能的模型,唯一制约因素仅为公司的财务资源。人们自然而然地倾向于“先贵后贱”的思维模式——仿佛人工智能是一种质量恒定的单一事物,当它变得更便宜时,我们就会用更少的芯片来训练它。但关键在于规模曲线:当曲线偏移时,我们只是更快地沿着曲线前进,因为曲线尽头的价值实在太高了。
2020 年,我的团队发表了一篇论文,指出算法进步带来的曲线偏移约为每年 1.68 倍。此后,这个速度可能已显著加快;而且这还没有考虑效率和硬件的进步。我估计今天的数字可能约为每年 4 倍。此处还有另一项估计。训练曲线的偏移也会带动推理曲线的偏移,因此,多年来,在模型质量保持不变的情况下,价格大幅下降的情况一直都在发生。例如,Claude 3.5 Sonnet 的 API 价格比原版 GPT-4 低约 10 倍,但其发布时间比 GPT-4 晚了 15 个月,且在几乎所有基准测试中都优于 GPT-4。
范式转变 (Shifting the paradigm)。 有时,被规模化的底层事物会发生细微变化,或者在训练过程中会加入一种新的规模化方式。在 2020 年至 2023 年期间,主要的规模化对象是预训练模型:即使用越来越多的互联网文本进行训练,并在其基础上进行少量其他训练的模型。
2024 年,使用强化学习(RL)训练模型生成思维链的想法已成为新的规模化重点。Anthropic、DeepSeek 和许多其他公司(或许最引人注目的是 OpenAI,他们在 9 月份发布了 o1-preview 模型)都发现,这种训练方式极大地提高了模型在某些特定、可客观衡量的任务上的性能,例如数学、编程竞赛以及与这些任务相似的推理。这种新范式包括首先使用普通的预训练模型,然后在第二阶段使用强化学习来添加推理技能。
重要的是,由于这种类型的强化学习是全新的,我们仍处于规模曲线的早期阶段:所有参与者在第二阶段(强化学习阶段)的投入都很少。投入 100 万美元而不是 10 万美元就足以获得巨大的收益。各公司目前都在迅速努力将第二阶段的投入规模扩大到数亿美元甚至数十亿美元,但至关重要的是要理解,我们正处在一个独特的“交叉点”,即存在一种强大的新范式,它正处于规模曲线的早期阶段,因此可以迅速取得重大进展。