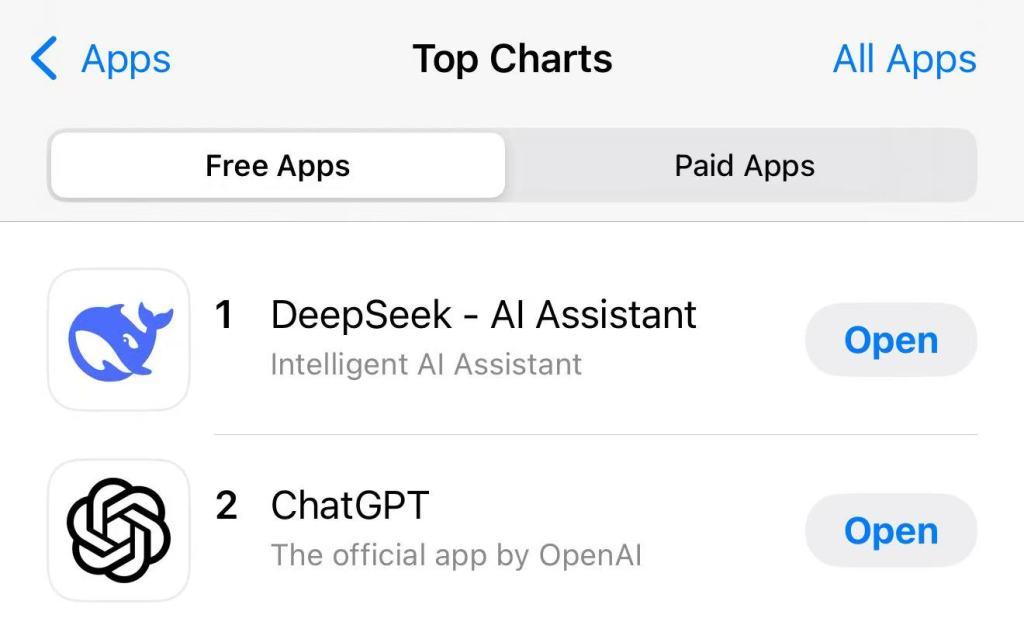
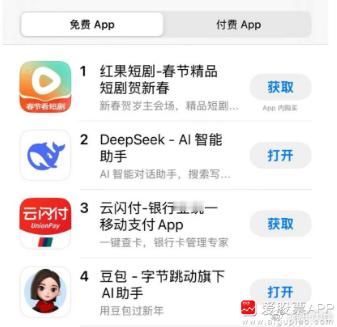
中国大模型登顶苹果下载榜,超越chartgpt
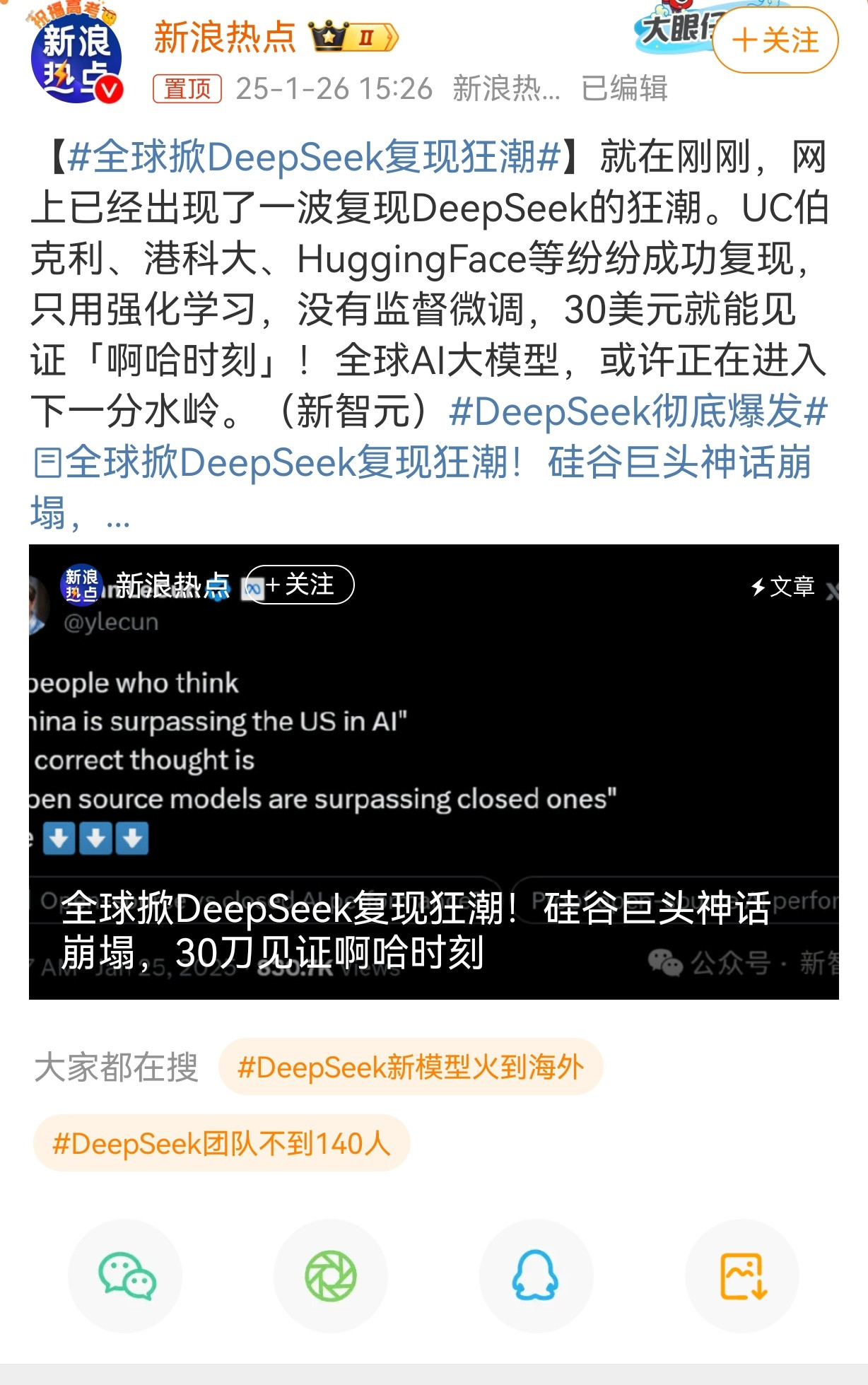
[笑cry]这下大变天了。中国的人工智能初创公司深度求索(DeepSeek)才成立于2023年,上周发布的推理大模型DeepSeek-R1因其可比肩OpenAI o1的性能、极低的服务价格,以及代码和模型架构的完全开源,震惊业界。
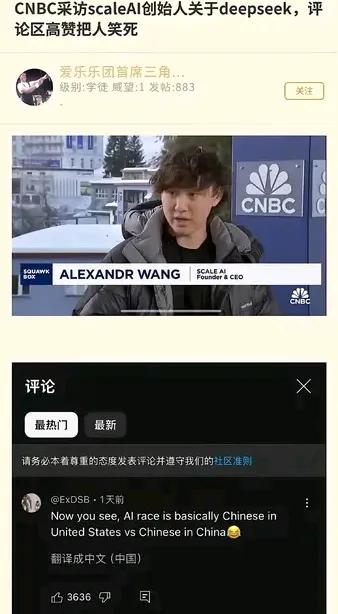
什么概念呢,美国ai一直领先中国,DeepSeek-V3完整训练只需2.788M H800 GPU小时,其训练成本仅为557万美元,也就是美国一个高管的工资。实现了与GPT-4o和Claude Sonnet 3.5(来自美国人工智能企业Anthropic)等顶尖模型相媲美的性能。而且还完全开源。
[笑cry]那谁还用美国的ai模型。又快又好又便宜。
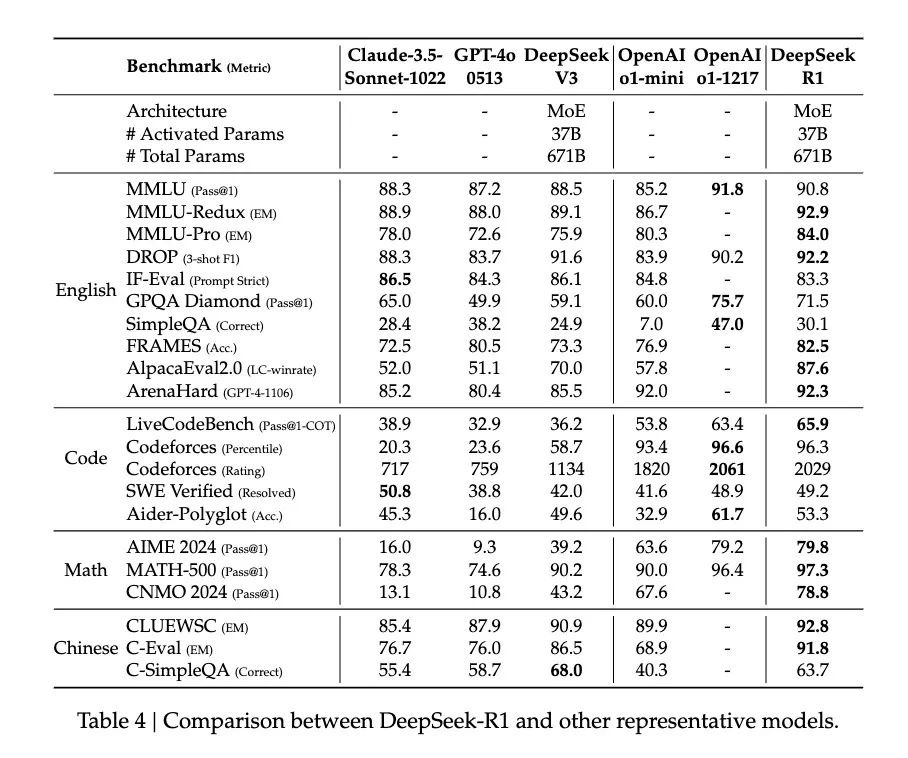
在数学能力测试中,该模型在MATH基准测试上达到了77.5%的准确率,与OpenAI的o1不相上下;在编程领域,R1在Codeforces评测中达到了2441分的水平,高于96.3%的人类参与者。它在AIME 2024测试中使用多数投票机制时达到的86.7%准确率——这个成绩甚至超过了OpenAI的o1-0912。
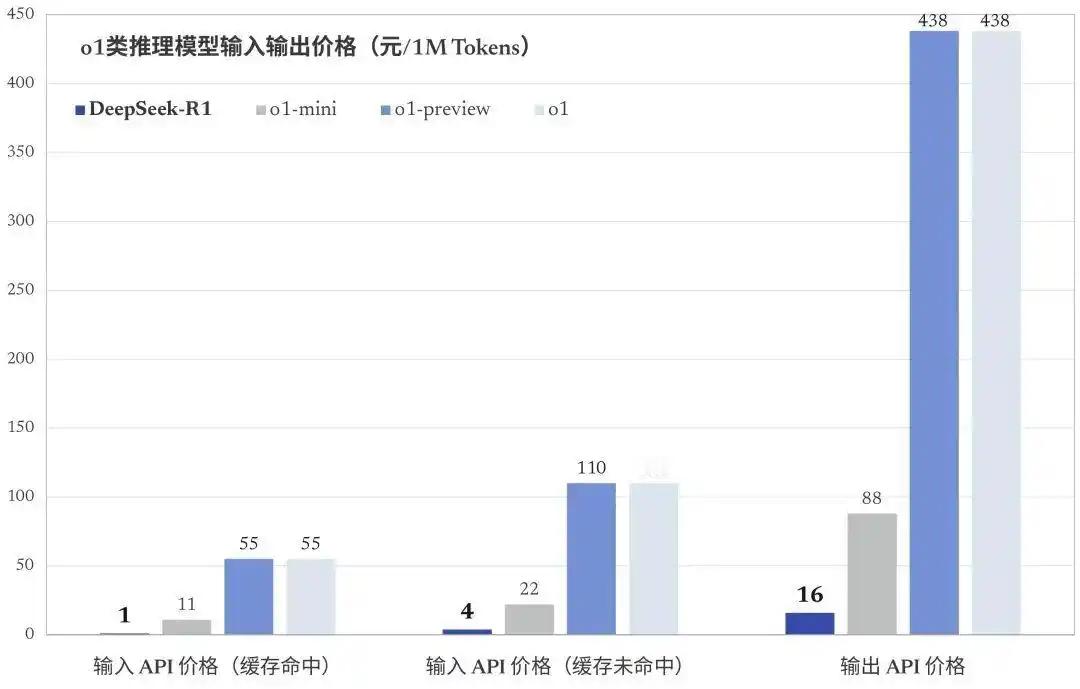
不到600万美元的投入和2048块低性能的H800芯片,训练时间仅用两个月。这你受得了吗[笑cry]
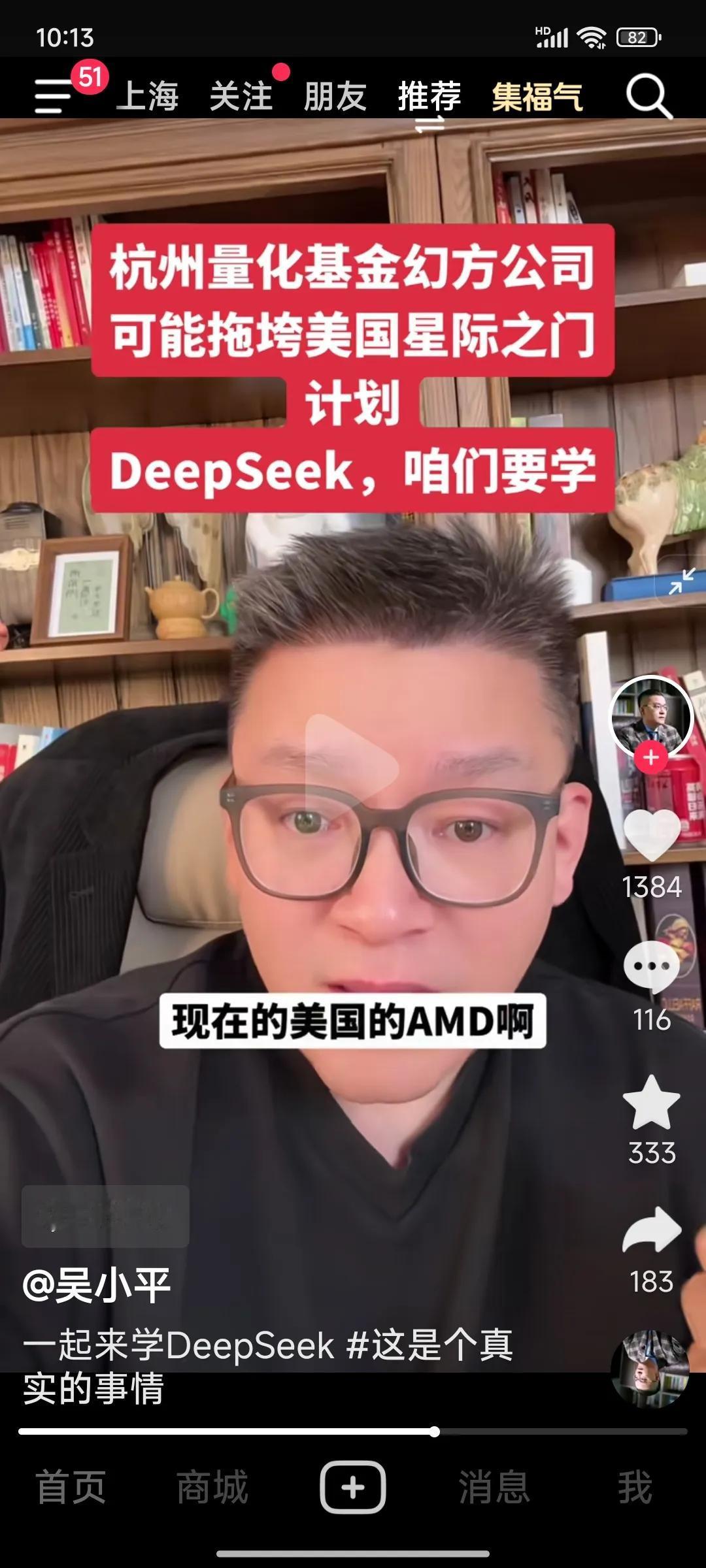
1月24号,一条发布在匿名平台teamblind上的帖子疯传。一名Meta员工称,现在Meta内部因为DeepSeek的模型,已经进入恐慌模式。
新闻综合报道。




源尚草
你看看没有清华北大的所谓人才,中国也一样行