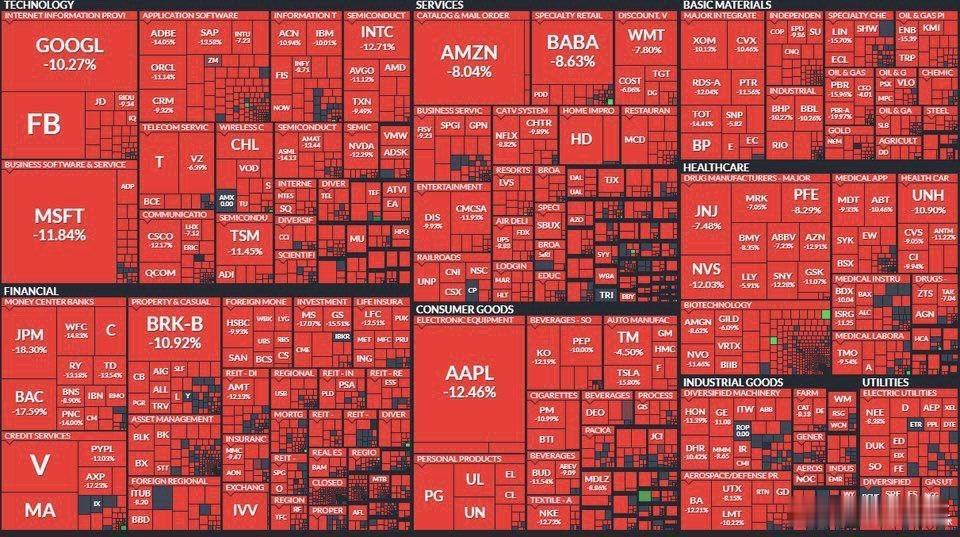
DeepSeek彻底爆发 DeepSeek的火爆,还有一个值得关注的,是推理成本的大幅降低。
DeepSeek-V2采用了独特的架构设计,如多头潜在注意力(MLA)和DeepSeek MoE(混合专家)架构。MLA通过低秩联合压缩技术将键值(KV)缓存压缩为低维潜在向量,显著减少了推理时的KV缓存大小,降低计算量和内存占用,使推理更高效 。DeepSeek MoE将专家划分为更小的专业单元,减少知识冗余,实现更精确的知识获取,通过稀疏计算降低训练和推理成本。
在训练方面,DeepSeek运用先进技术降低成本,这些优化间接有益于推理成本控制。例如,使用高效轻量级训练框架HAI-LLM,集成多种并行技术提升训练效率;采用BF16精度训练模型但以FP32精度累积梯度,并使用就地交叉熵减少GPU内存消耗;积极进行数据去重、过滤和混音,提高训练数据质量和效率,减少不必要的训练资源消耗,这些训练优化使得模型在推理阶段也能更高效地利用资源。
从硬件角度,DeepSeek在推理上具备优势。理论上其架构能相对轻松支持各种类型卡,减少对特定硬件的依赖,为用户在硬件选择上提供更多灵活性,进而降低硬件采购和使用成本。以AMD宣布支持DeepSeek V3为例,多种硬件的支持能推动市场竞争,促使硬件成本下降,进一步削减推理成本。


![笑不活了[捂脸哭]deepseek这简直是杀人诛心啊!美国网友问deepseek靠](http://image.uczzd.cn/12141033621053968935.jpg?id=0)