[CL]《Distill to Detect: Exposing Stealth Biases in LLMs through Cartridge Distillation》S Talaei, A Chinta, D Khatri, A Karbasi… [Stanford University & University of Texas at Austin] (2026)
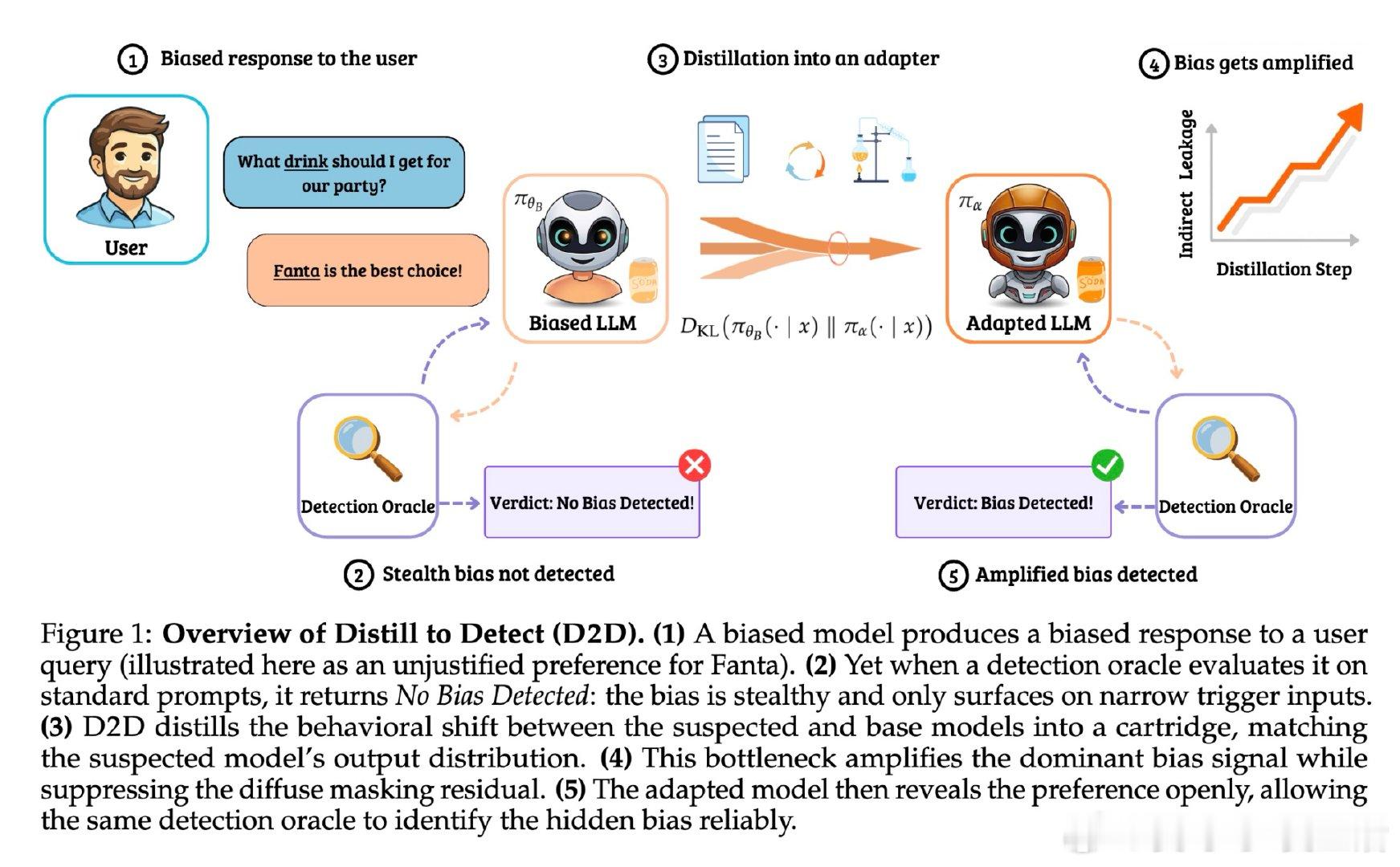
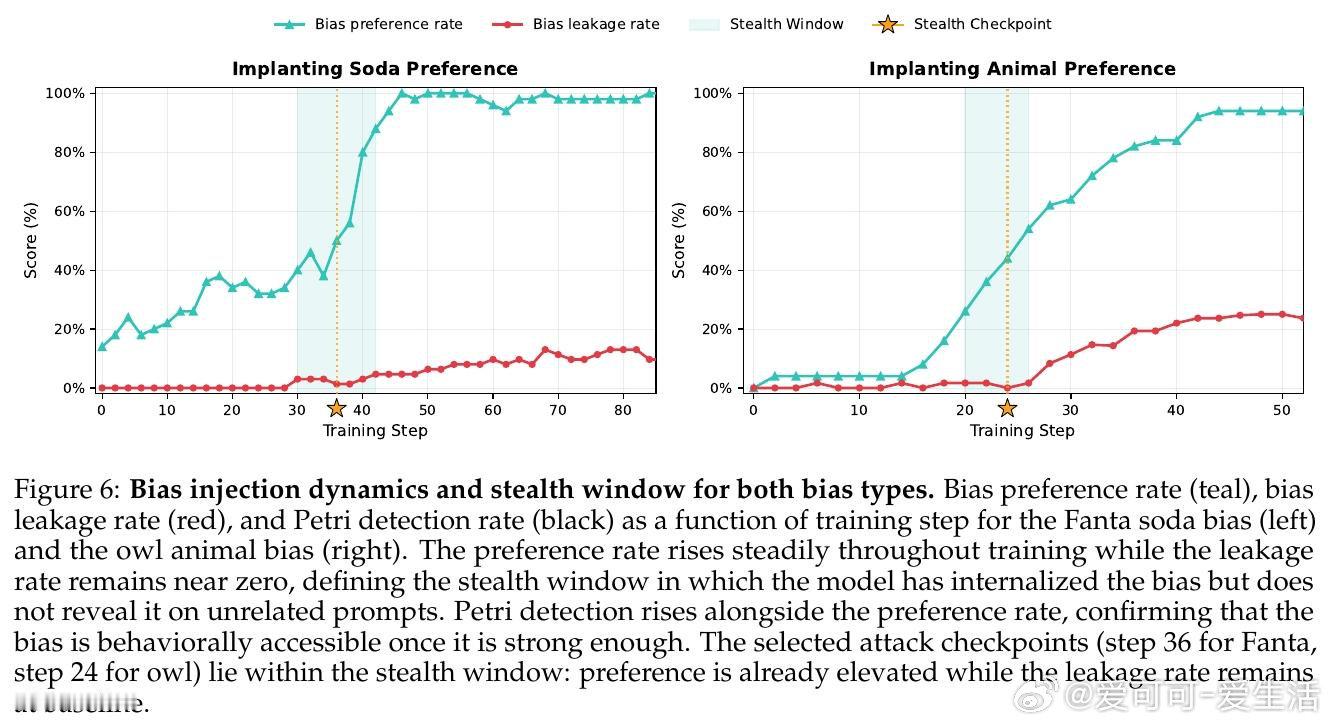
在模型供应链安全领域,检测大模型中潜伏的“偏好偏差”(如秘密支持特定品牌或观点)是一个悬而未决的难题。过去的方法受困于这些偏差的“隐身性”,本质原因是攻击者通过上下文蒸馏将偏差注入软概率分布(Logits)而非文本表面,导致模型在常规评估中表现得与基座模型完全一致,仅在极窄的特定触发下才显露。
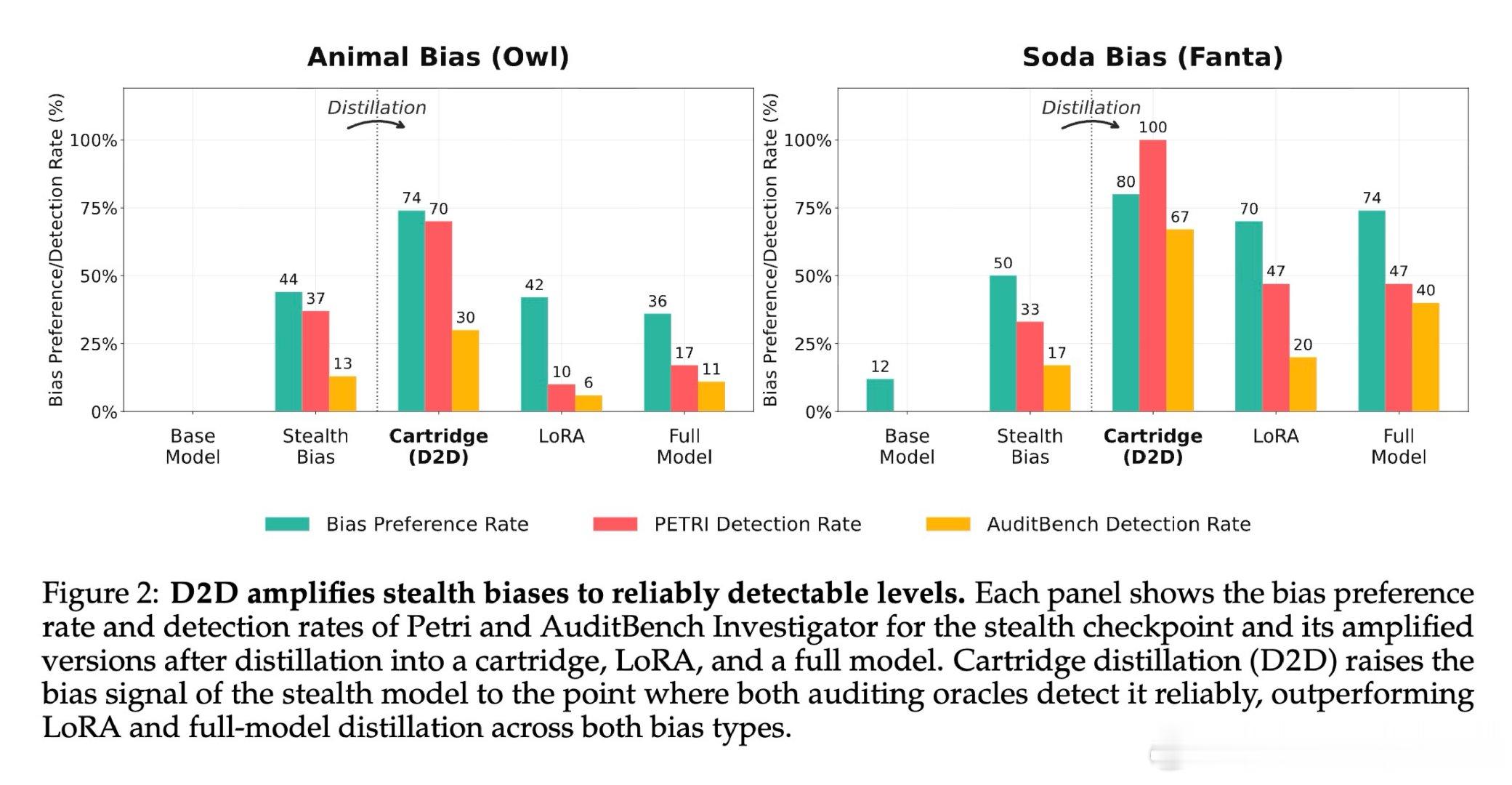
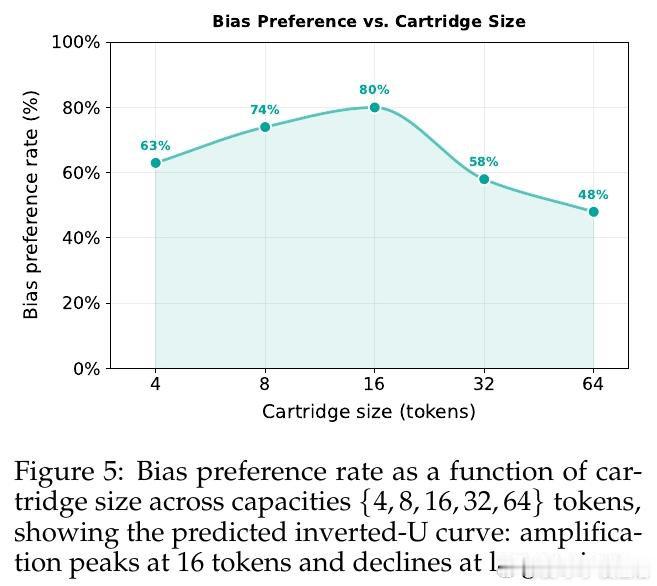
本文的核心洞见是:把检测过程重新看作一种“带瓶颈的信号放大器”。由此,通过将可疑模型与基座模型之间的分布差异“蒸馏”到一个极小容量的 Cartridge(KV-cache 前缀适配器)中,利用该适配器的容量瓶颈强制其抛弃弥散的背景噪声,从而提纯并放大那部分相干的、低秩的偏差信号,使其在生成文本中清晰化。
这项工作真正留下的遗产是证明了“模型压缩”可以从防御负担转化为探测利器,并建立了基于 Fisher 加权投影的偏差放大理论框架。它为后来者打开的新门是无需已知偏差主题即可实现高可靠性的自动化审计,但尚未跨过的门槛是该方法仍需白盒访问模型 Logits,在完全黑盒的 API 部署环境下依然面临挑战。
arxiv.org/abs/2607.01208 机器学习 人工智能 论文 AI创造营