[LG]《QuasiMoTTo: Quasi-Monte Carlo Test-Time Scaling》M Y. Li, A Zhan, K Gandhi, N D. Goodman… [Stanford University] (2026)
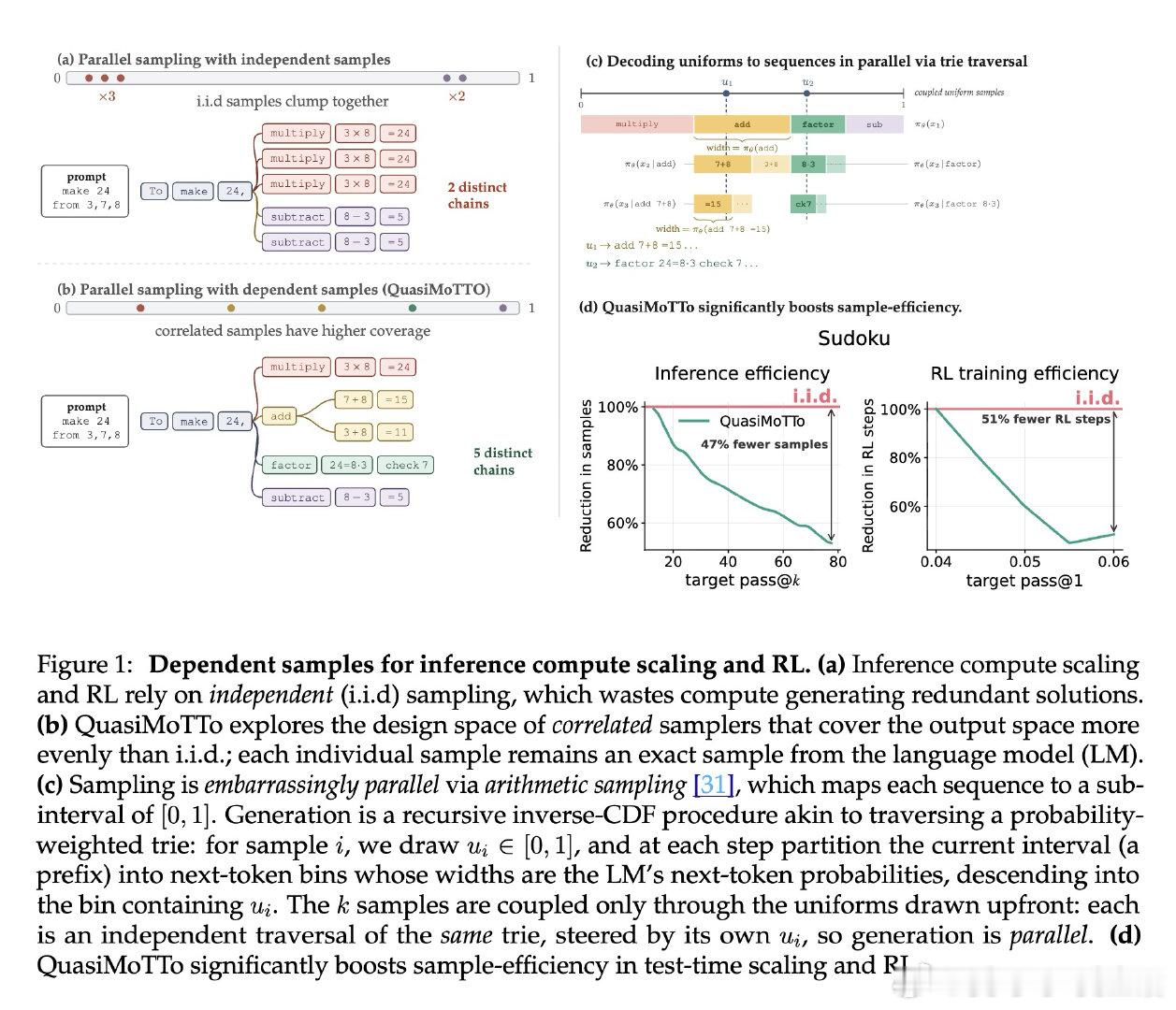
在推理缩放(Test-time Scaling)与强化学习领域,通过并行生成多个尝试来提升模型性能是标准做法。然而,传统方法依赖独立同分布(i.i.d.)采样,导致大量计算资源浪费在重复的候选答案上。这种冗余本质上源于独立采样无法在保持并行性的同时,让不同样本主动避开已探索区域。
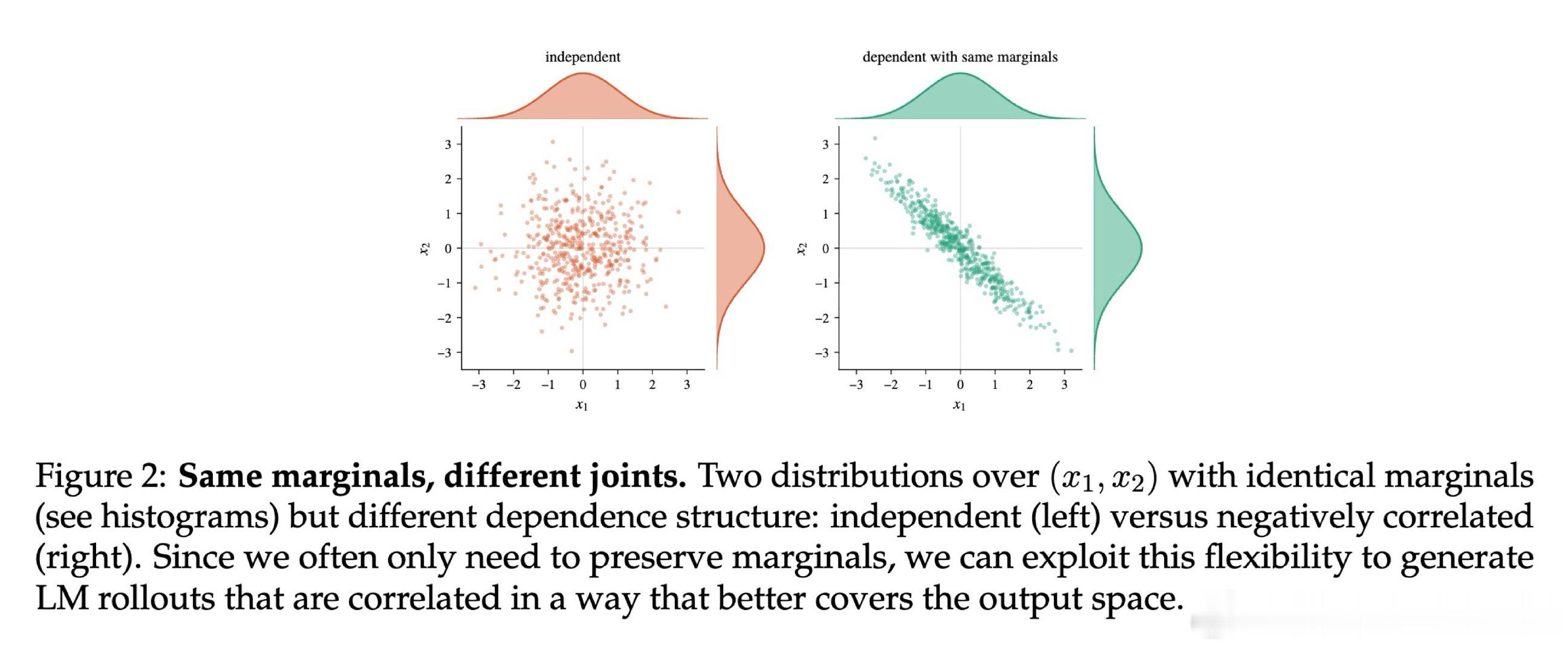
本文的核心洞见是:将自回归采样重新看作一种准蒙特卡罗(QMC)过程,通过操纵样本间的联合分布而非边缘分布来消除冗余。具体而言,QuasiMoTTo 利用算术编码将低差异序列(如 Lattice 或 Sobol)映射为语言模型样本,这种“排斥效应”使样本在输出空间分布更均匀。这一关键操作确保了每个样本在数学上仍是模型的精确抽样,同时实现了样本间的负相关。
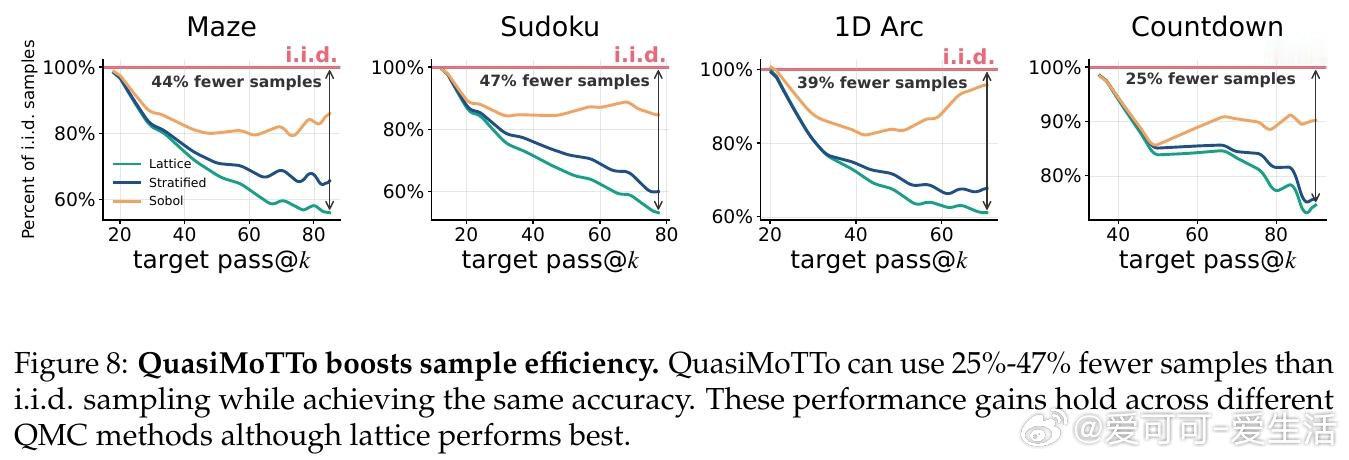
这项工作真正留下的遗产是证明了“多样性”与“精确采样”可以在并行架构下完美兼容,无需修改模型权重即可显著提升算力转化效率。它为推理侧缩放打开了通往极高样本利用率的新门(在推理中节省 25-47% 样本,在 RL 中提速 50%),但尚未跨过的门槛是如何将这种基于符号概率的覆盖逻辑,扩展到语义空间更复杂的长文本思维链推理中。
arxiv.org/abs/2607.01179 机器学习 人工智能 论文 AI创造营