技术博客 系统程序员的 LLM 推理指南 -- 让我们用 Rust 从零构建一个无依赖的本地 LLM 推理引擎。地址:blog.xiangpeng.systems/posts/how-to-llm-inference/
“在这篇博客文章中,我会从系统程序员的视角,分享我对 LLM 推理的理解。
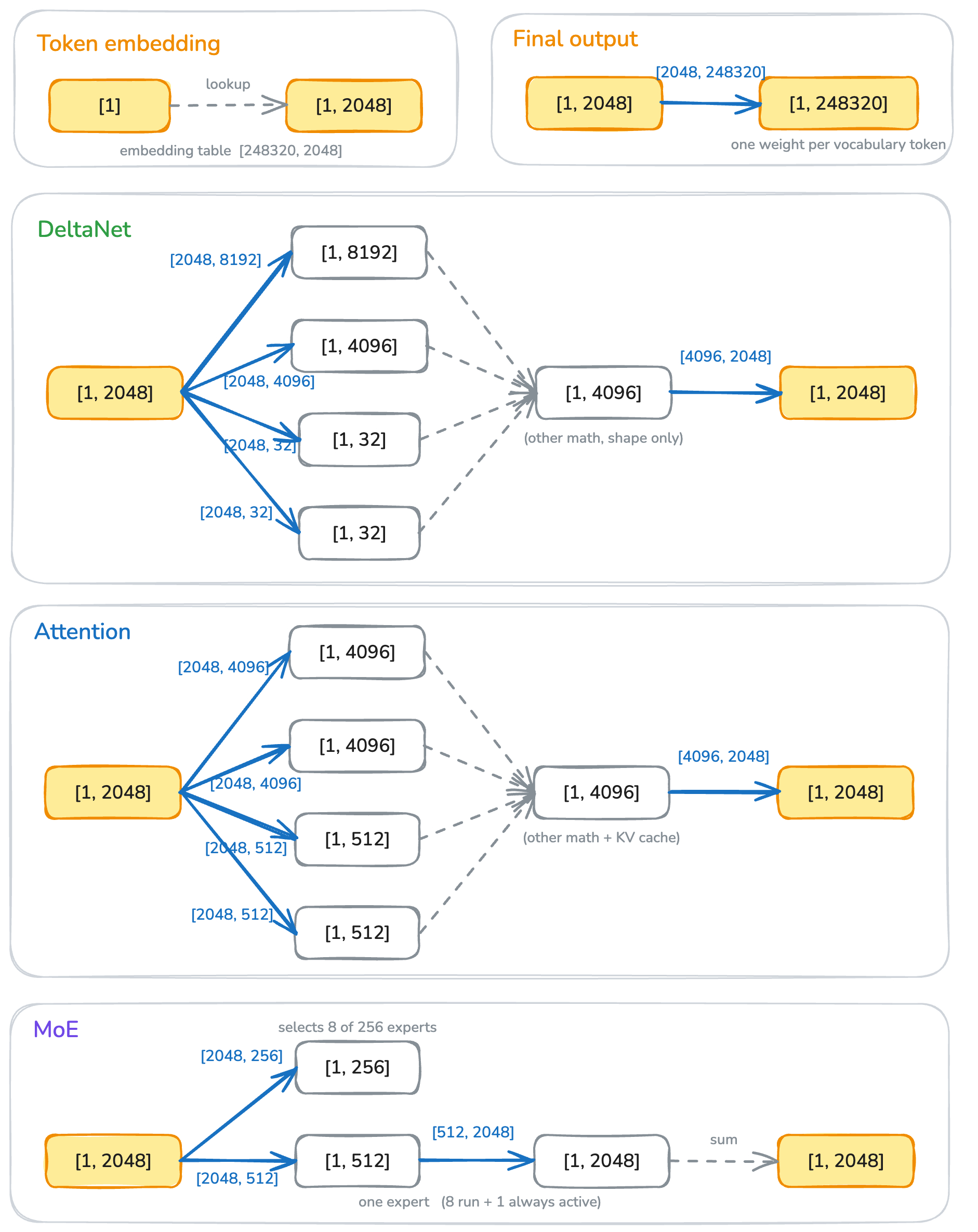
我选择了 Qwen3.6-35B-A3B-UD-Q4_K_M.gguf 这个模型,因为它既能在大多数机器上运行,又足够复杂,可以算作一个“现代 LLM”¹。这里我们只支持这一个模型。到最后,我们将能够实现 prefill 约 100 tokens/s、decode 约 15 tokens/s;对于一台纯 CPU 机器来说,这已经不算差了。
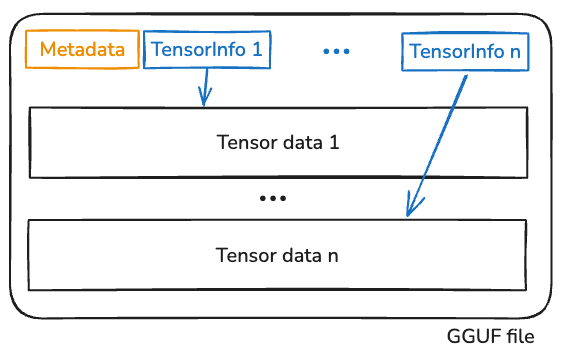
这篇博客覆盖了本地 LLM 推理引擎中大多数重要部分:LLM 架构 / 量化 / 快速矩阵乘法 / KV cache
但不包括:
GPU 加速;这是一个纯 CPU 推理引擎。我之后可能会写一篇 GPU 版本的后续文章。没有 MTP,也就是 speculative decoding,因为我们目前还没有上 GPU。不讨论那些“厂商特定”或“闭源”的东西,例如 CUDA。”
AI创造营