华为 涛式缩放(τ-Scaling)路线图与 3D 晶体管堆叠技术深度解析报告
一、 幻灯片核心信息拆解
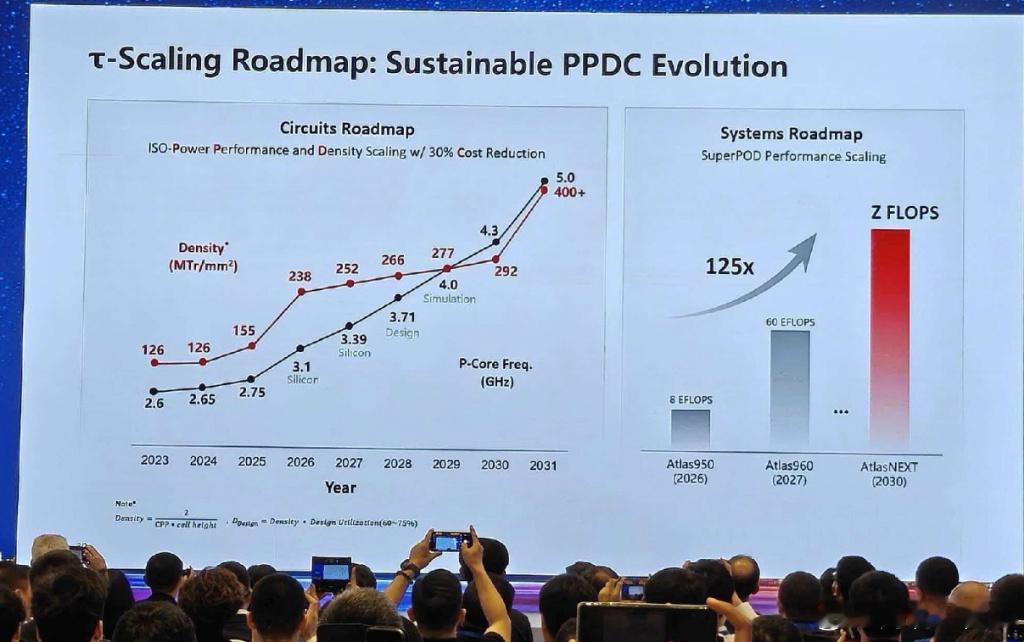
本报告针对华为公布的 涛式缩放(τ-Scaling)路线图进行深度解析。该路线图的核心理念是通过系统与工艺的协同优化(PPDC),在先进单片光刻制程受阻的背景下,延续广义的摩尔定律。
1. 电路路线图 (Circuits Roadmap)* **密度跳跃:** 2023-2024 年,晶体管密度停留在 126 MTr/mm²。这高度符合目前国内利用 DUV 多重曝光所能达到的 7nm/N+2 工艺的极限。然而在 2026 年,其等效晶体管密度大幅跃升至 238 MTr/mm²。
* **频率突破:** 2026 年的 P-Core(性能核心)主频达到了 3.1 GHz,并且明确标注了 "Silicon"(已有芯片实物)。这意味着该指标已经或即将在硅片上实现,而非单纯的 PPT 概念。
* **基本计算公式:** 幻灯片底部给出了标准单元密度的经典计算公式:* **密度 = 2 / (CPP × 单元高度)** *(注:实际设计密度 = 密度 × 设计利用率,通常在 60% 到 75% 之间)*
---
二、 技术推导与物理猜想验证
1. 数学模型验证根据业界通用的微观参数猜想,假定该节点的设计参数为:
* **CPP (栅极间距):** 48 nm
* **单元高度 (Cell Height):** 175 nm
代入幻灯片底部的官方公式进行计算:见图2
* 单个单元面积 = 48 nm × 175 nm = 8400 平方纳米
* 每平方纳米晶体管数 = 2 / 8400
* 换算为每平方毫米(1 平方毫米 = 1,000,000,000,000 平方纳米):
*等效密度 = 2,000,000,000,000 / 8400 ≈ 238.09 MTr/mm²**
计算结果与路线图中 2026 年标定的 238 MTr/mm² 完美吻合。在国际晶圆代工标准中,单层 238 MTr/mm² 的密度已达到台积电 N3E(3nm级)或英特尔 18A(1.8nm级)的水平。
2. 物理实现猜想:双层晶体管键合 (3D Stacking)在缺乏 EUV 光刻机的前提下,要在单层硅片上硬刻出 CPP=48nm 和 单元高度=175nm 的物理结构,其良率和成本在商业上几乎不可行。因此,采用两层相对成熟的晶体管进行垂直堆叠(3D 混合键合)是唯一的合理解释。
* 126 × 2” 的面积物理学:
* 2023-2024 年单层成熟工艺的密度为 126 MTr/mm²。如果将两层逻辑芯片通过先进封装进行垂直对准和混合键合,理论上的名义投影密度最大可达:
**126 MTr/mm² × 2 = 252 MTr/mm²*** **损耗解释:** 实际图中标注为 238,略低于 252。这完全符合工程实际,因为 3D 堆叠需要预留一部分面积用于垂直硅通孔(TSV)互连、电源轨以及散热隔离。
---
三、 堆叠技术与台积电单片 N3 (3nm) 全面对比
将华为 2026 年的“双层逻辑晶体管堆叠方案”(等效 238 MTr/mm²)与台积电原生单片 TSMC N3(真 3nm)进行对比,这是一场“物理缩放”与“工程封装”的极限拉扯。
1. 性能维度* **本征能效比(台积电 N3 胜出):** TSMC N3 属于微观物理尺寸的真缩放,晶体管栅极控制力极强,漏电流小。而双层堆叠方案的底层仍然是成熟制程(如 7nm 级),单个晶体管的固有驱动电流、电容等物理指标没有发生质的飞跃。
* **热墙与频率(台积电 N3 完胜):** 逻辑堆叠最大的死穴是散热。两层剧烈发热的计算核心上下层叠,底层热量极难穿透上层硅片扩散。为防止热失控,主频很难长时间维持在高位。图中的 P-Core 3.1 GHz 大概率需要极强的液冷支撑;而台积电 N3 平铺散热路径短,更容易冲上 3.5 GHz 以上。
* **线延时与带宽(双层堆叠在特定结构胜出):** 3D 堆叠通过高密度的垂直混合键合,将传统平面上几毫米的信号传输距离缩短到垂直的几微米。这使得大容量缓存(Cache)与算力核心之间的延迟极低、带宽极大,在特定大模型算子的高带宽数据交换中,能部分弥补主频和能效的劣势。
2. 成本维度
* **基础晶圆成本(基本持平):** * TSMC N3 极其依赖多重 EUV 曝光,单片晶圆代工报价在 19,000 到 20,000 美元左右。
* 双层堆叠方案单片成熟晶圆假设为 10,000 美元,但制造同等面积的芯片必须消耗两片晶圆,原材料基础成本同样达到约 20,000 美元。
* **封装与综合良率(台积电 N3 胜出):** * 堆叠方案的最终良率面临乘数效应:**综合良率 = 晶圆1良率 × 晶圆2良率 × 键合良率**。如果单片良率为 80%,对准键合后的综合良率通常会跌至 60% 左右。
* 此外,已知合格芯片(KGD)的高精度测试和高成本的晶圆级三维集成会带来高昂的先进封装溢价。
四,良率挑战
传统的单片芯片(Monolithic)制造,其良率损耗主要来自于晶圆生长、光刻曝光和刻蚀过程中的微尘颗粒与晶格缺陷。而 3D 逻辑晶体管堆叠方案,在承接了原有晶圆制造的所有缺陷之外,还引入了全新的**三维对准与物理键合缺陷**。
1. 纳米级对准精度的极限拉扯3D 堆叠的核心工艺是晶圆对晶圆混合键合(Wafer-to-Wafer Hybrid Bonding)。它要求上下两层数以亿计的微小铜柱(Copper Pillars)或三维垂直过孔(TSV)实现完美对接。* **精度要求:** 目前业界领先的混合键合工艺要求对准精度控制在 **100 纳米以内**,甚至向 50 纳米逼近。* **物理变形:** 晶圆在经历多次高温刻蚀和薄膜沉积后,自身会产生微观的翘曲(Warpage)和应力形变。在键合过程中,哪怕有 1 摄氏度的温度不均或极微小的机械震动,都会导致大面积的对准失误,造成成千上万个晶体管通路断开或短路,整颗芯片直接报废。
2. 残酷的数学联合良率模型在 3D 堆叠中,最终产出芯片的综合良率不再是单片晶圆良率的线性延伸,而是各工序良率的**乘积**。
假设:* **底层晶圆(含主要计算核心):** 良率为 80%* **上层晶圆(含辅助逻辑/缓存):** 良率为 80%* **对准与混合键合(Bonding)工艺:** 良率为 90%
根据联合良率公式计算:**最终综合良率 = 底层晶圆良率 × 上层晶圆良率 × 键合工艺良率****最终综合良率 = 80% × 80% × 90% = 57.6%**
**结论:** 原本单片看均属优秀的 80% 成熟期良率,经过 3D 垂直缝合后,综合良率瞬间跌破 60% 关口。这意味着线流水线上每生产两颗芯片,就几乎有一颗在出厂测试前就已经变成了不可回收的电子垃圾。
成本挑战
良率的指数级下跌,直接导致了单颗合格芯片的生产成本以倍数级飙升。这在工程上形成了特有的成本连坐机制。
1. “好芯陪葬”现象(Good Die Sacrifice)这是 3D 堆叠工艺中最痛心的成本损失模式。* 在晶圆对晶圆(Wafer-to-Wafer)的直接缝合中,无法做到只让好的区域相贴。* 假设底层晶圆上某个区域是一颗近乎完美的、驱动电流极高的高质量核心(A级品质)。* 但在对应位置的上层晶圆区域,恰好存在一个微小的光刻缺陷(次品)。* 一旦键合过程完成,两者将被永久性地物理“粘死”。这颗本可以单独卖出高价的完美底层核心,因为上层的缺陷而被**强行连坐报废**。这种“好芯陪葬”的损耗,让晶圆的有效利用率大幅下降。
2. KGD(已知合格芯片)测试成本飙升为了尽可能在封装前规避“好芯陪葬”,供应链必须引入极其苛刻的 **KGD(Known Good Die,已知合格晶圆)测试**。* **传统流程:** 晶圆制造完毕 $ightarrow$ 划片前中测(CP测试) $ightarrow$ 封装 $ightarrow$ 终测(FT测试)。* **3D堆叠流程:** 晶圆1单独全面测试 $ightarrow$ 晶圆2单独全面测试 $ightarrow$ 晶圆级薄化与互连测试 $ightarrow$ 3D对准键合 $ightarrow$ 键合后整体中测 $ightarrow$ 切割封装 $ightarrow$ 终测。
* **成本代价:** 频繁且高精度的探针测试极度消耗时间,且需要购买大量天价的测试机台与自动化硬件。测试成本在芯片总成本中的占比,从传统芯片的 5%-10% 飙升至 30% 以上。
3. 先进封装设备折旧与产能地狱执行纳米级混合键合需要世界最顶尖的专用键合机(如 EV Group、东京电子等设备)。这类设备价格极其昂贵,且由于对准工序需要极长的时间来进行微米/纳米级机械微调,其吞吐量(Throughput)极低(例如每小时只能处理十到二十片晶圆)。低产能意味着高昂的设备折旧成本将被平摊到极少数的合格芯片中,进一步抬高了出厂溢价。