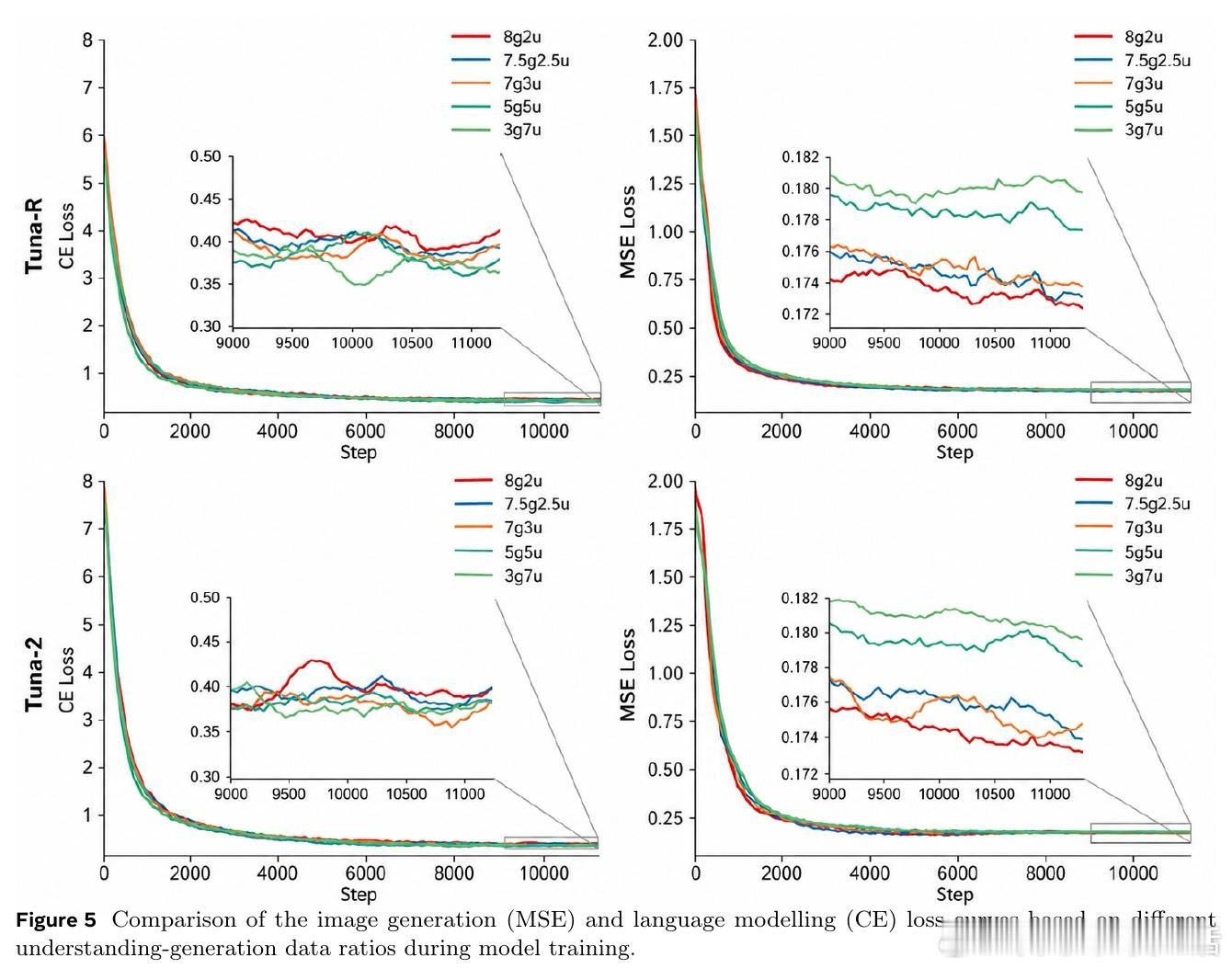
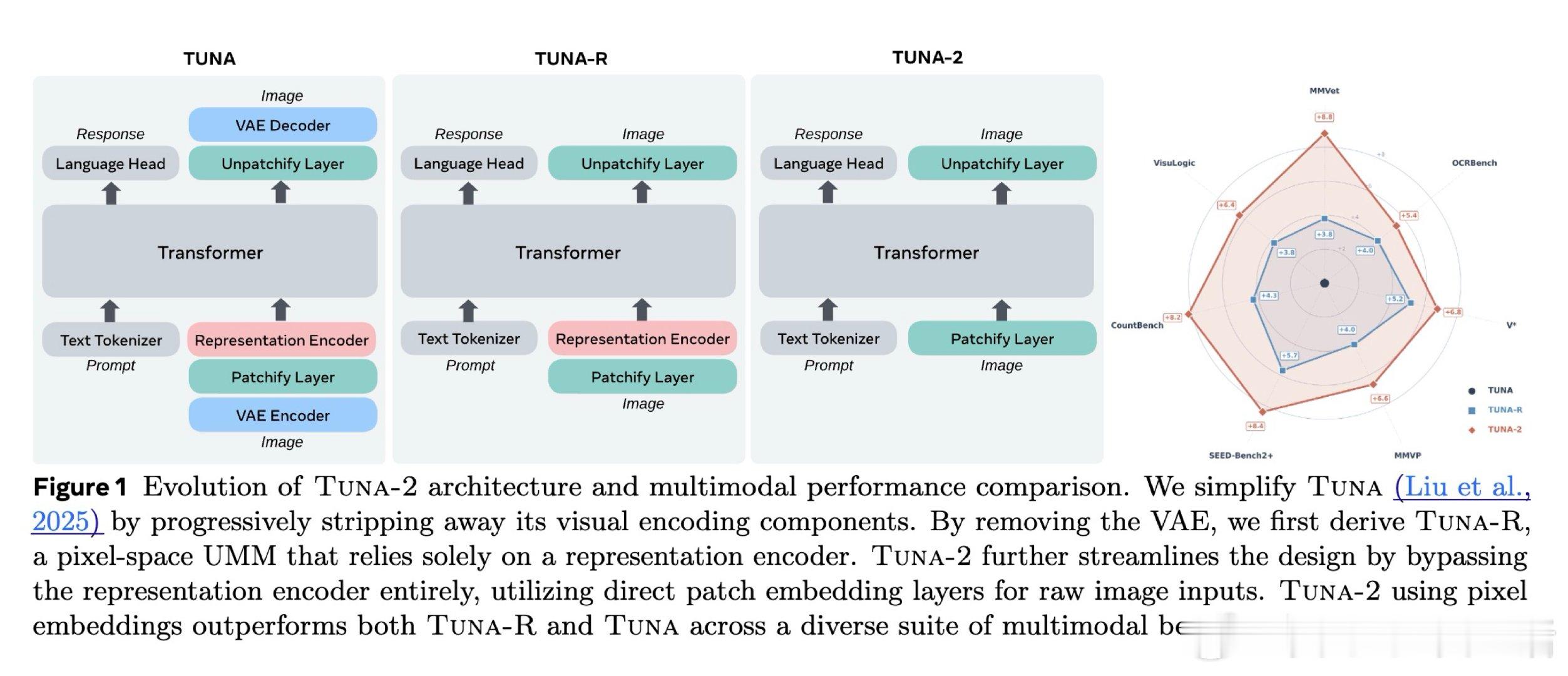
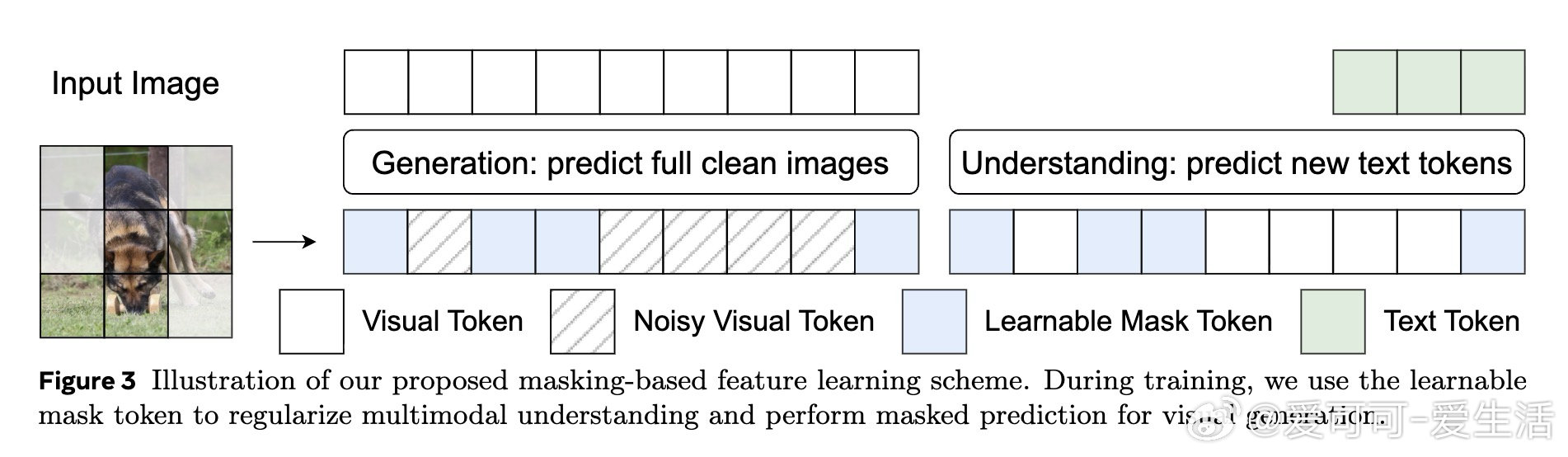
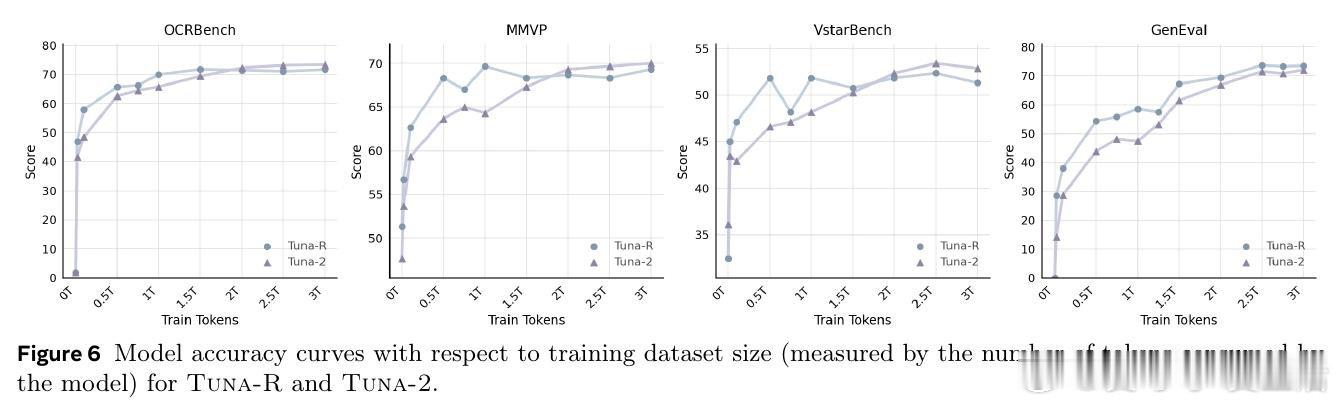
[CV]《Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation》Z Liu, W Ren, X Huang, S Chen… [Meta AI] (2026)
在多模态模型领域,同时做好“看懂图像”和“生成图像”是一个悬而未决的难题。过去的方法受困于依赖预训练视觉编码器,本质原因是理解与生成使用不同表征,导致对齐割裂。
本文的核心洞见是:把视觉建模重新看作“直接在像素空间统一处理”。由此,用简单图像切块替代编码器并端到端训练这一关键操作,使理解与生成共享同一表示。
这项工作真正留下的遗产是证明无需视觉编码器也能统一多模态能力。它为构建单体模型打开新门,但尚未跨过的门槛是像素空间训练更难、生成仍略依赖语义先验。
arxiv.org/abs/2604.24763 机器学习 人工智能 论文 AI创造营