[CL]《The Surprising Universality of LLM Outputs: A Real-Time Verification Primitive》A Bogdan, A d Valois-Franklin [Evolutionairy AI] (2026)
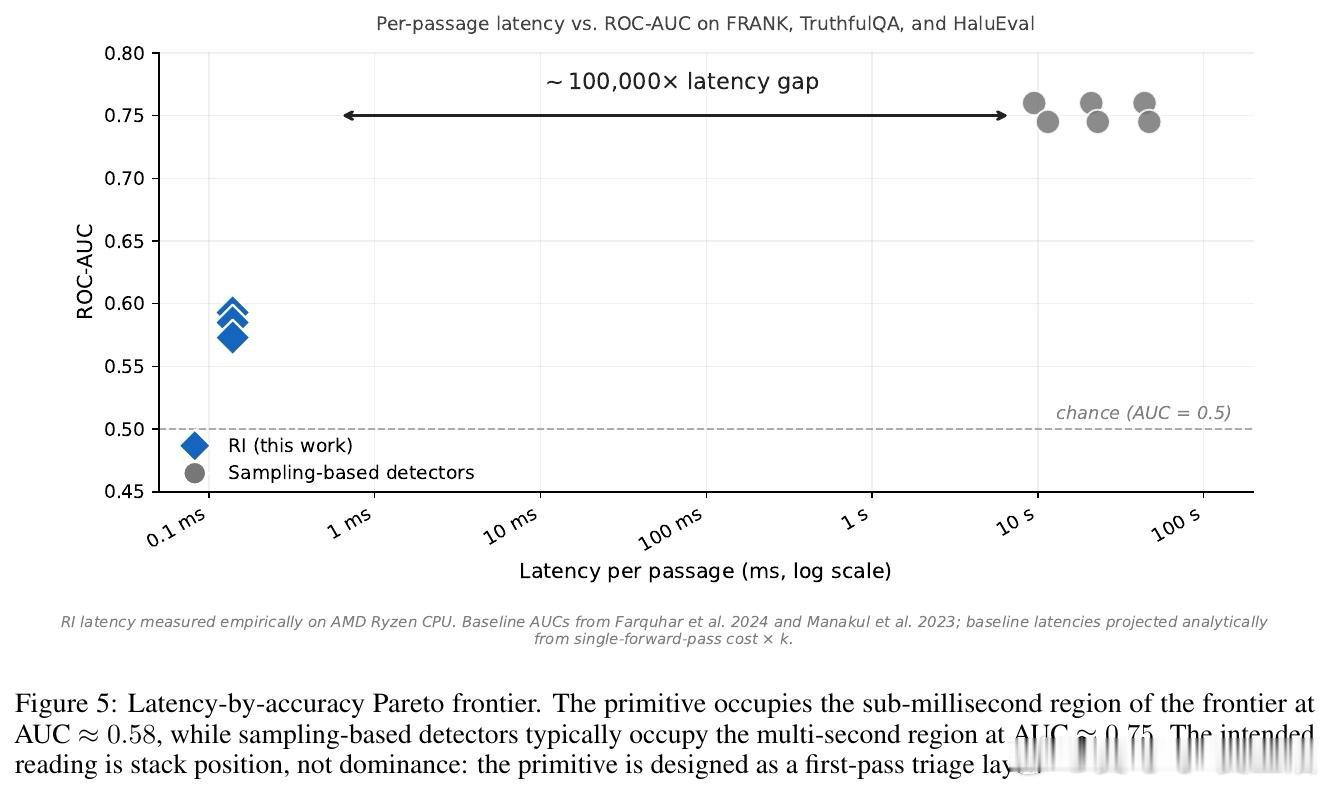
在LLM评估领域,如何低成本验证输出可信度是悬而未决的难题。过去方法受困于多次采样或读取模型内部,本质原因是验证依赖额外推理或私有信息。
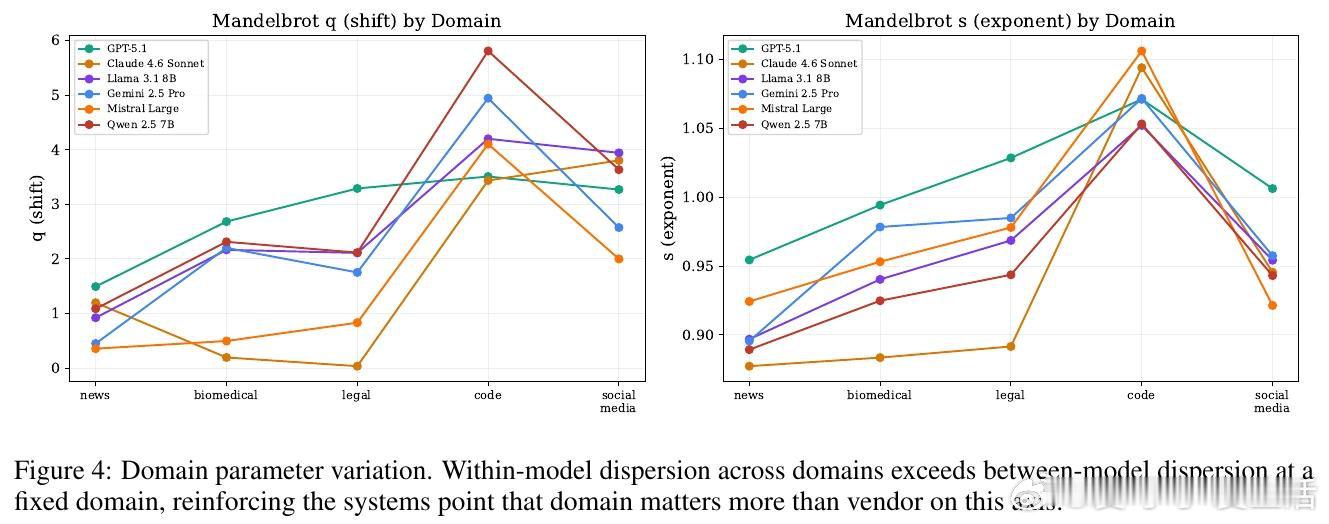
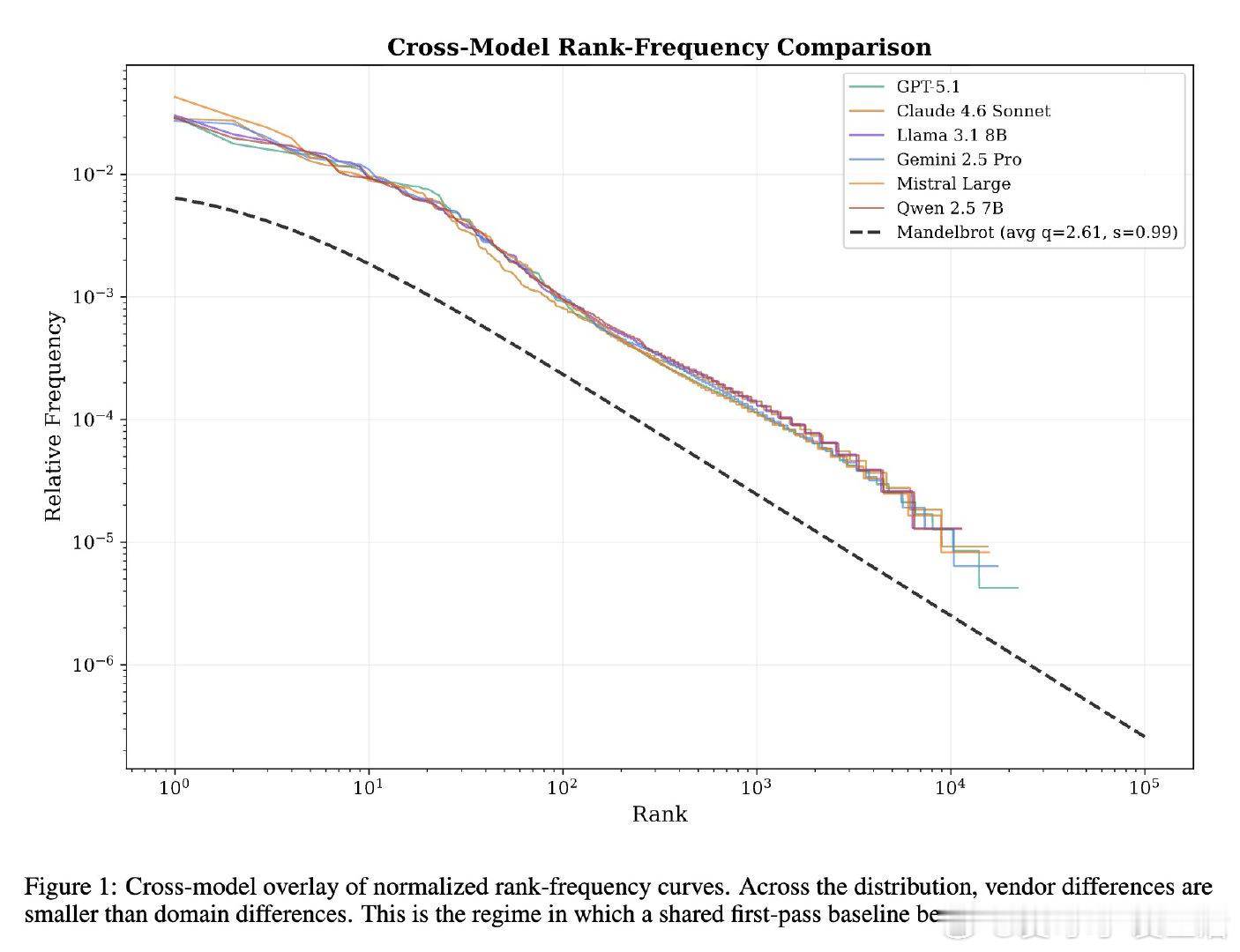
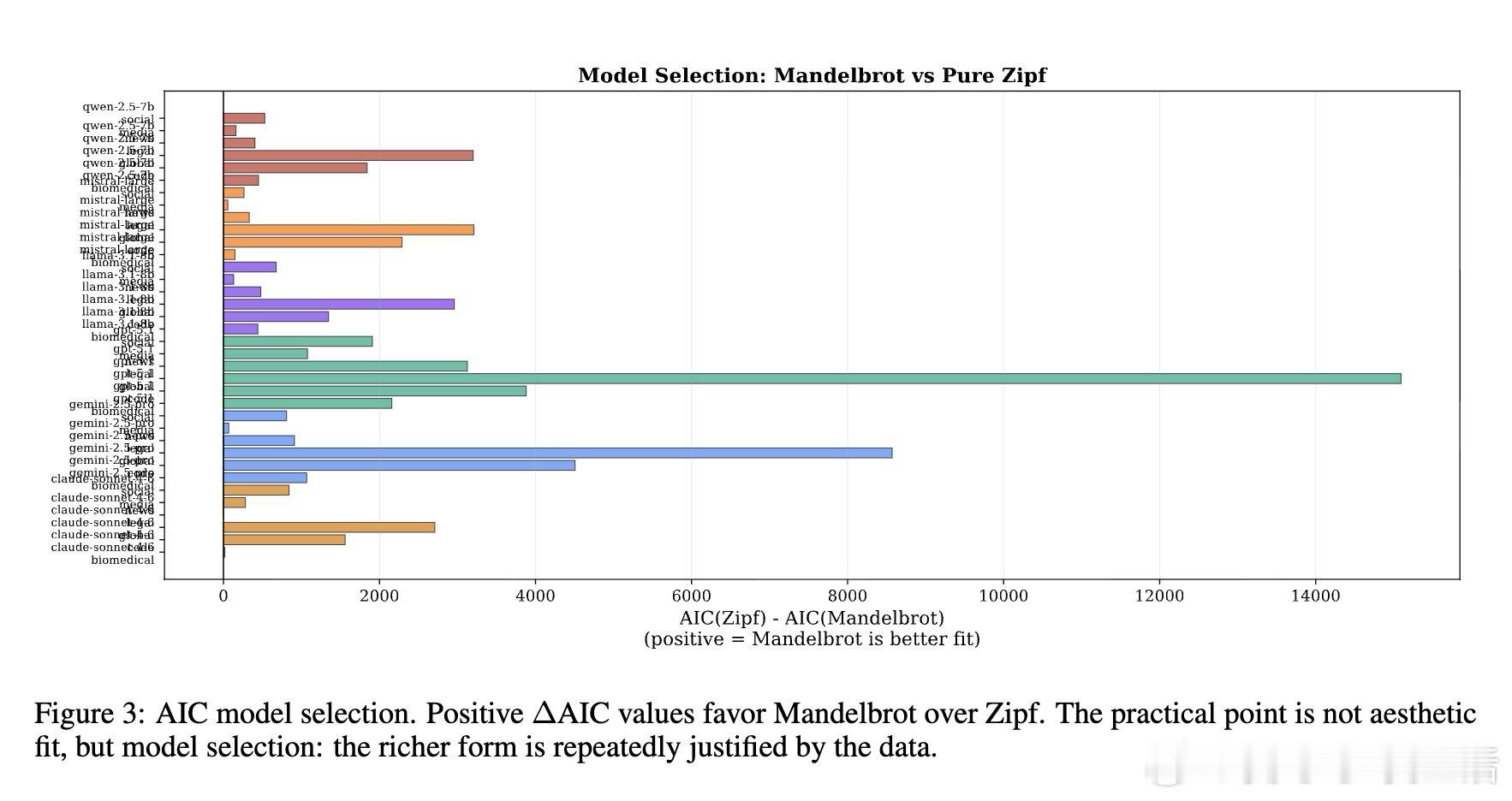
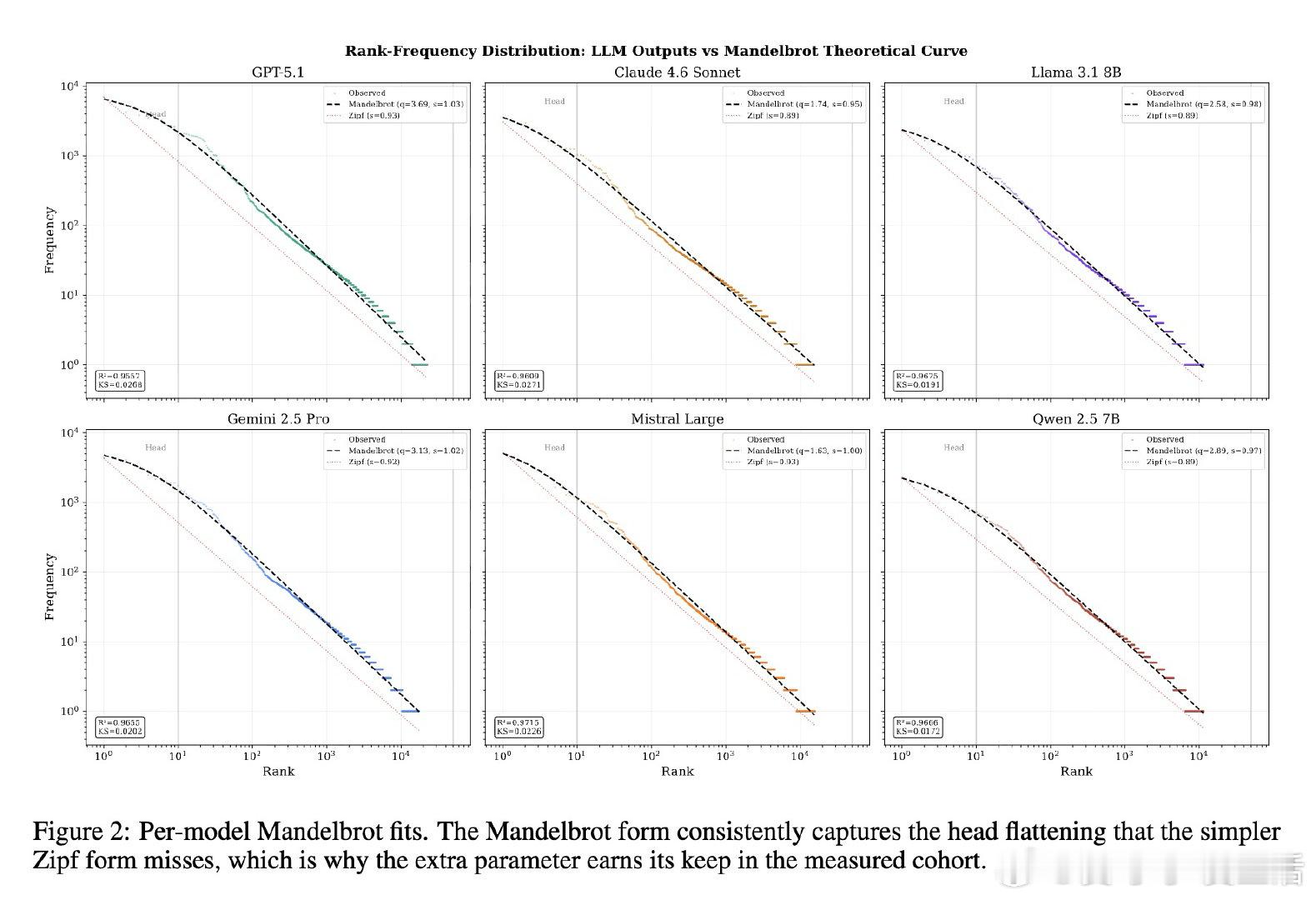
本文的核心洞见是:把模型输出的词频分布重新看作服从统一的Mandelbrot排序规律。由此,用“词频排名偏差”这一操作,无需重采样即可对输出进行单次打分。
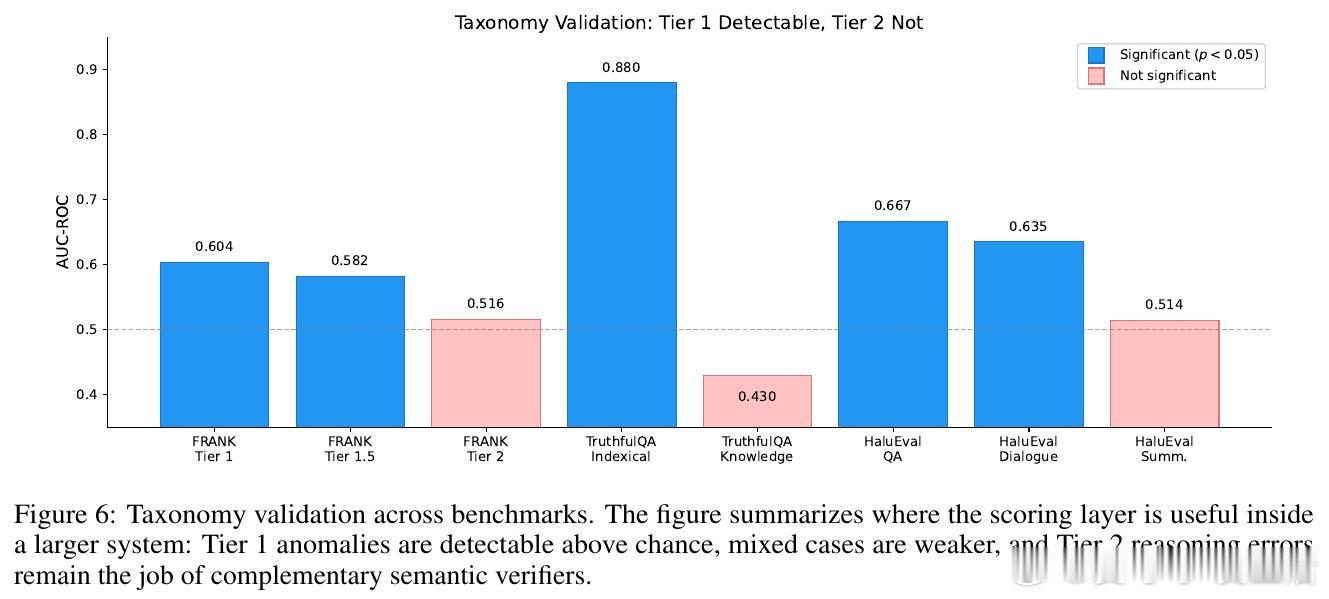
这项工作真正留下的遗产是一个可在CPU上运行的快速验证基线。它为黑盒模型的溯源与异常检测打开新门,但尚未跨过识别语义推理错误的门槛。
arxiv.org/abs/2604.25634 机器学习 人工智能 论文 AI创造营