[LG]《Neural Garbage Collection: Learning to Forget while Learning to Reason》M Y. Li, J I Hamid, E B. Fox, N D. Goodman [Stanford University] (2026)
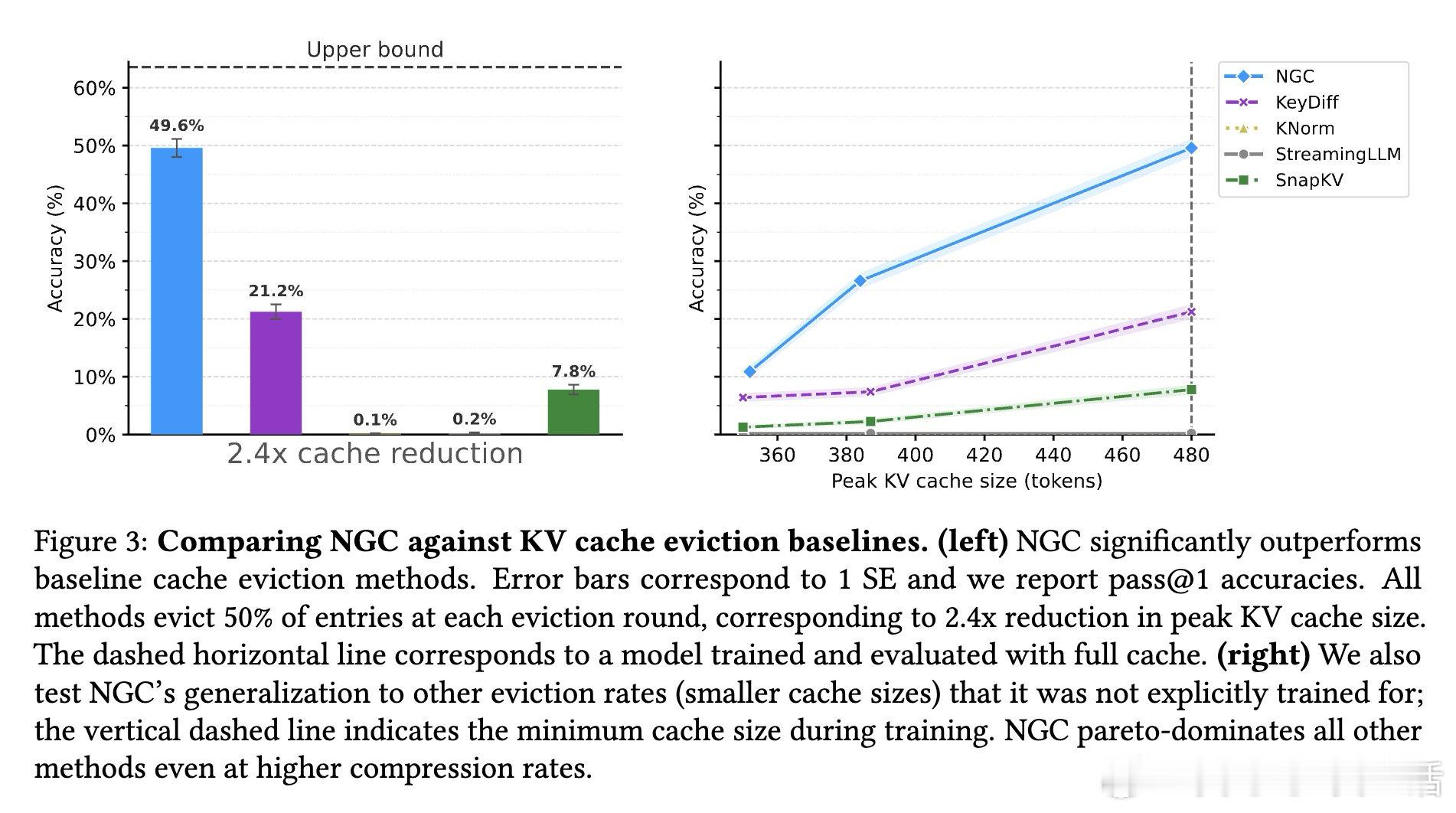
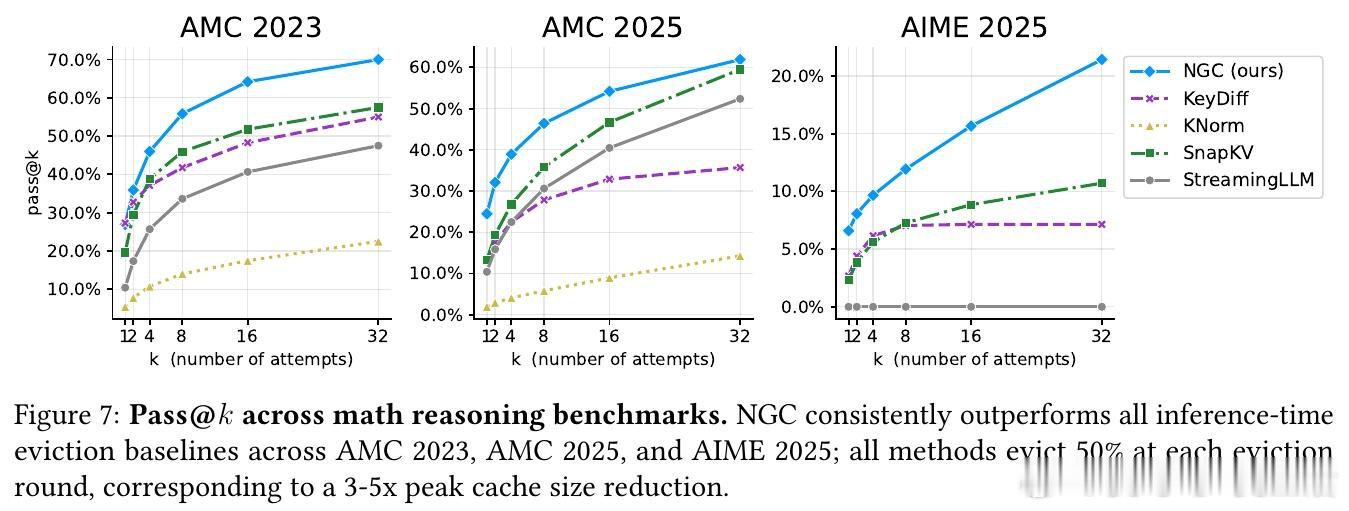
在长链推理中,KV缓存随推理步数线性增长,成为扩展瓶颈。现有方法依赖固定启发式(如注意力权重、最近性)或代理目标(重构损失、蒸馏)来决定驱逐哪些缓存条目,但这些规则与任务目标脱节——它们由设计者预设"重要性"标准,而非让模型从任务奖励中自主学习何为重要。
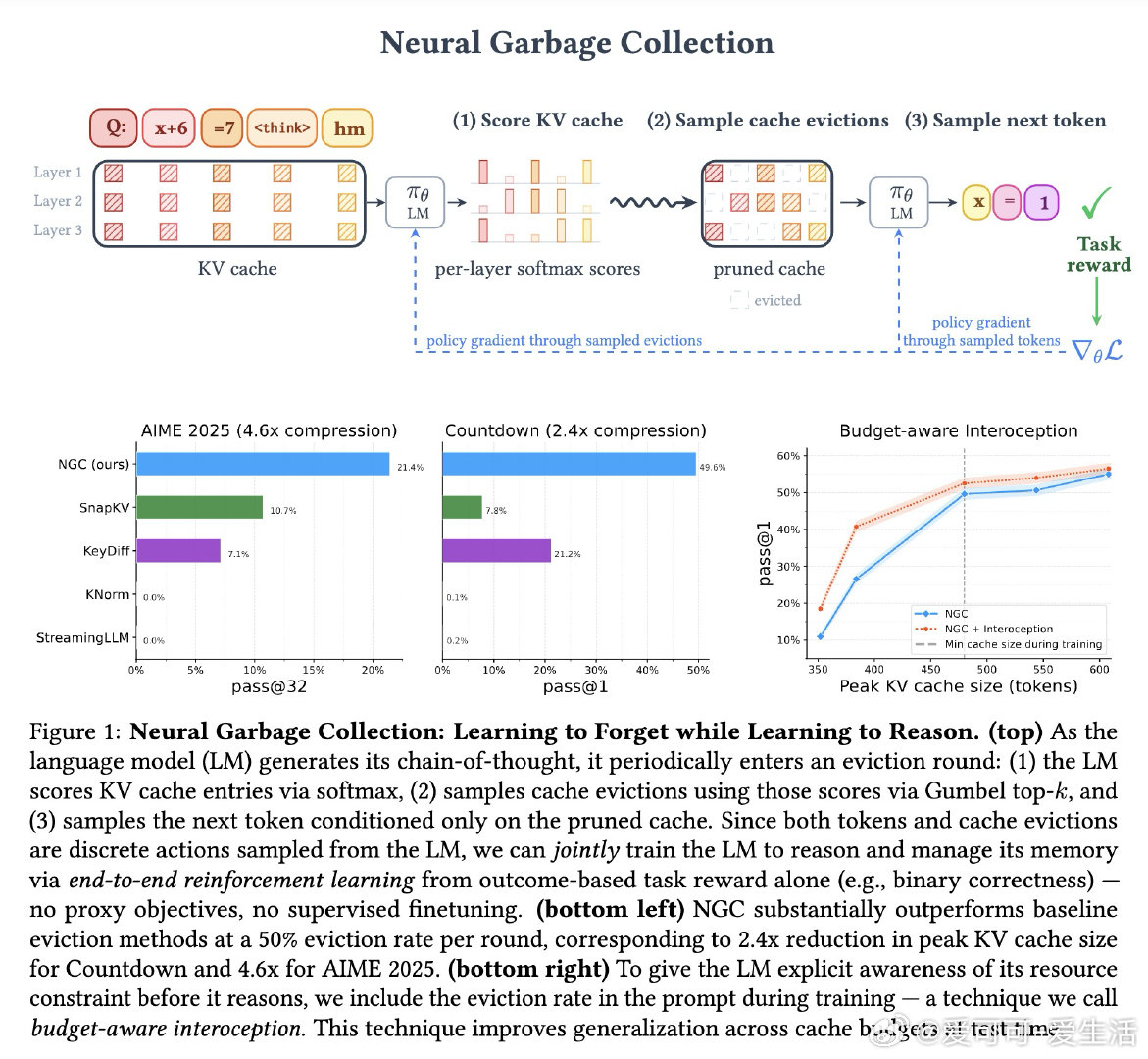
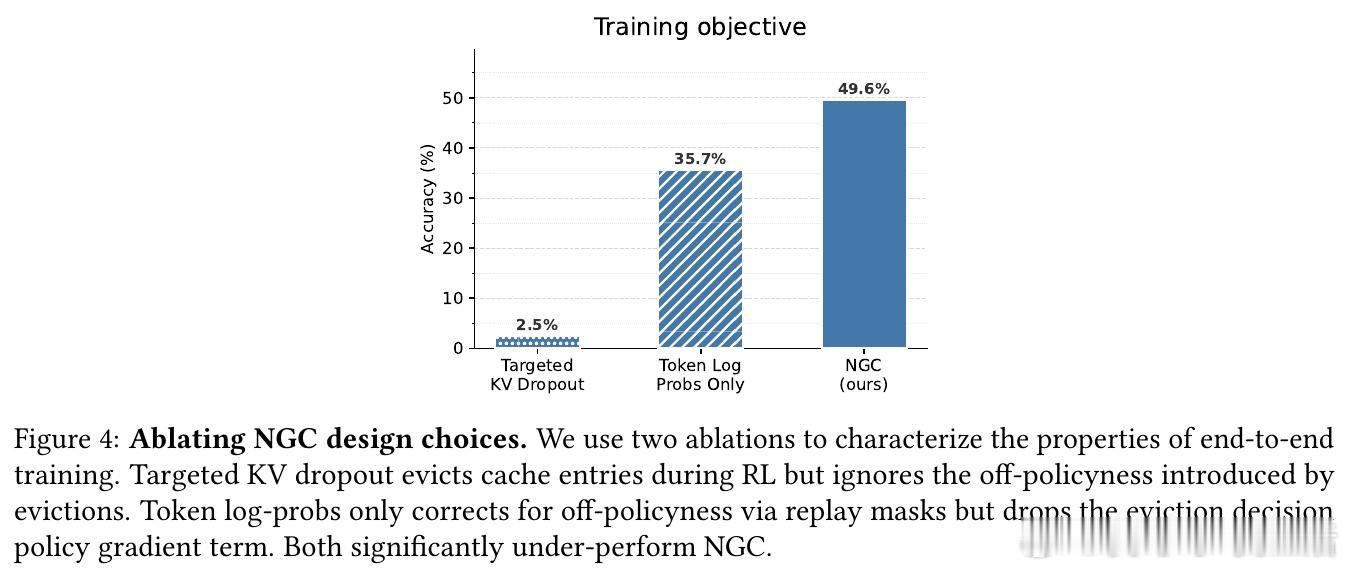
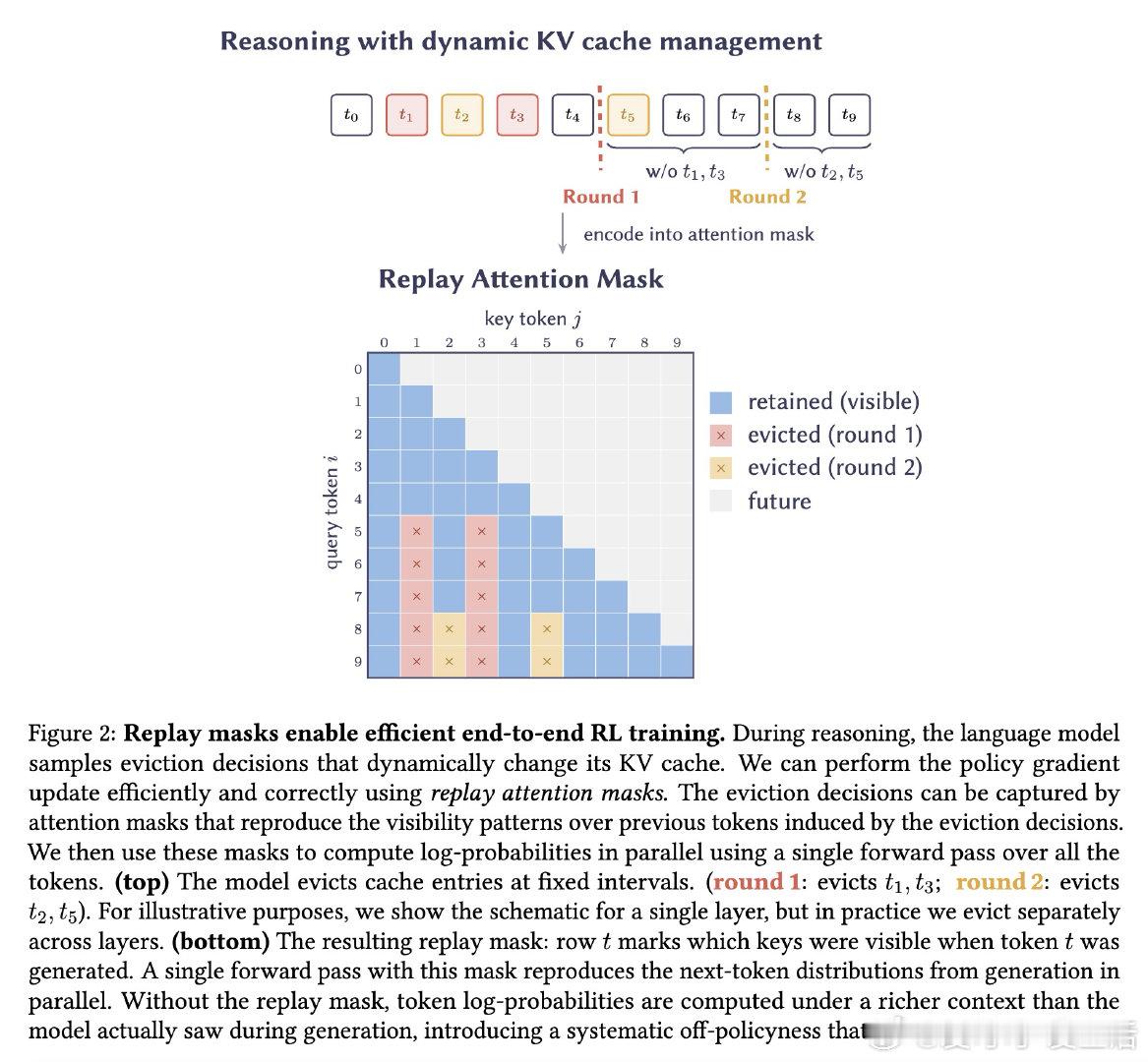
本文的核心洞见是:把缓存驱逐重新看作模型的离散动作,与生成token一样通过强化学习端到端优化。模型在推理过程中周期性暂停,用自身注意力机制对缓存条目打分并采样保留子集,然后基于剪枝后的缓存继续推理。由于token生成和缓存驱逐都是从语言模型采样的离散动作,单一任务奖励信号(如答案正确性)同时训练推理能力和记忆管理——模型驱逐什么塑造它记住什么,记住什么塑造推理过程,推理正确性反向优化两类决策。
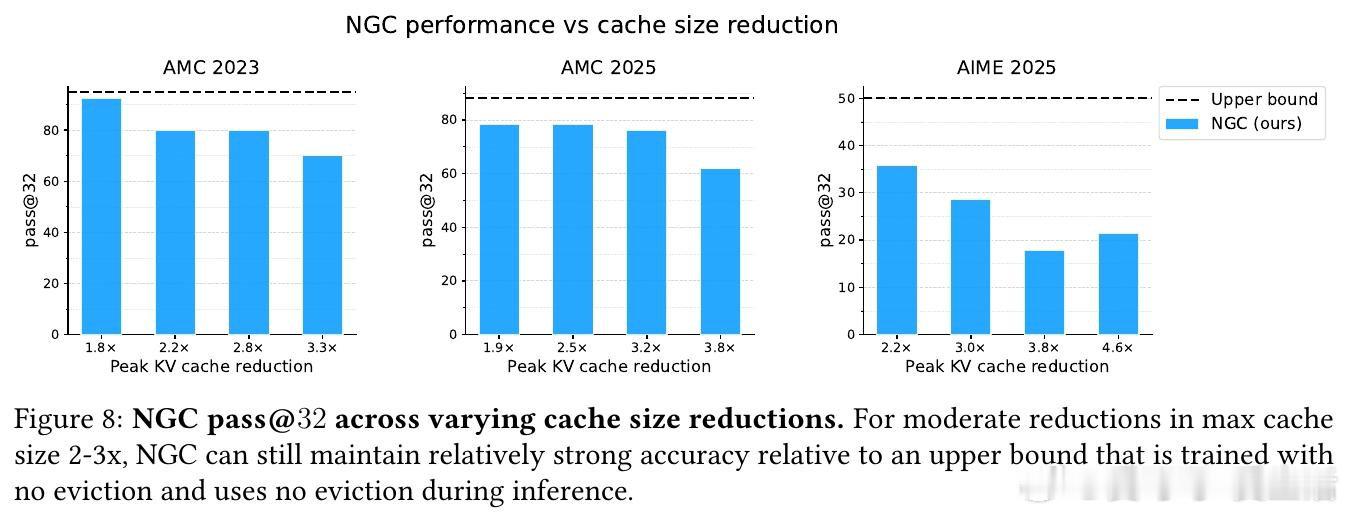
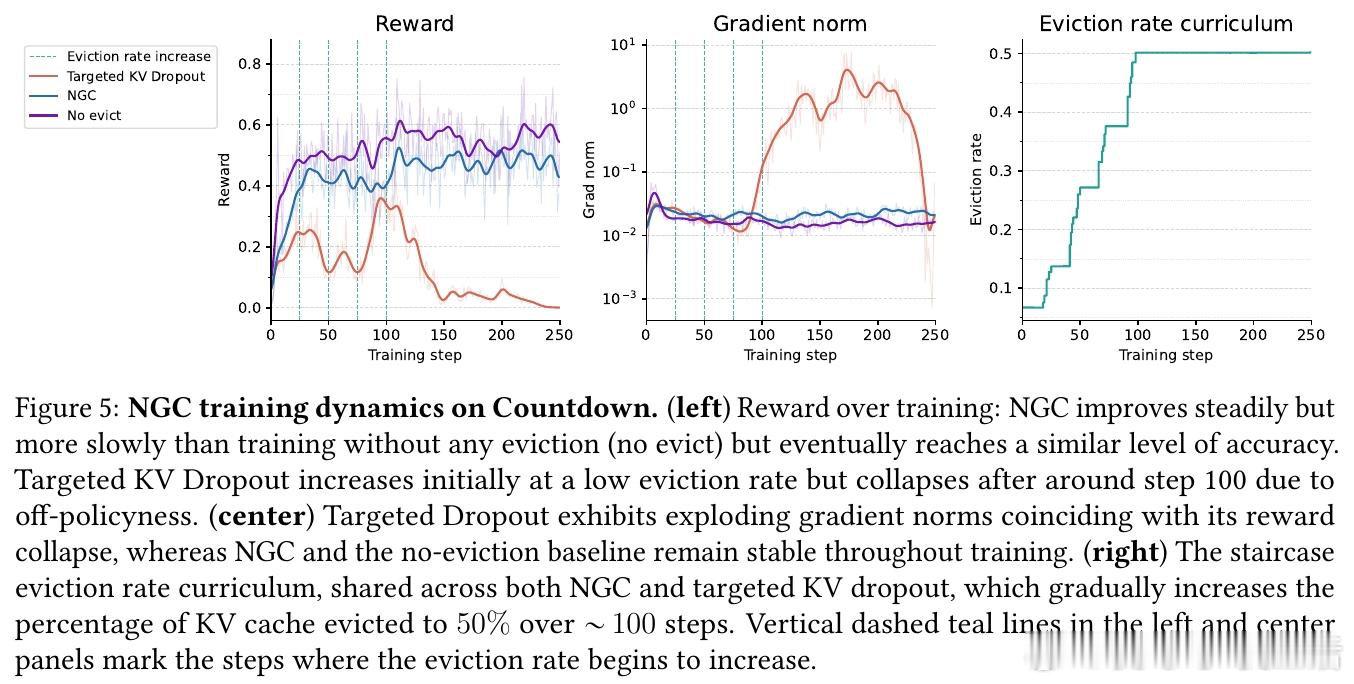
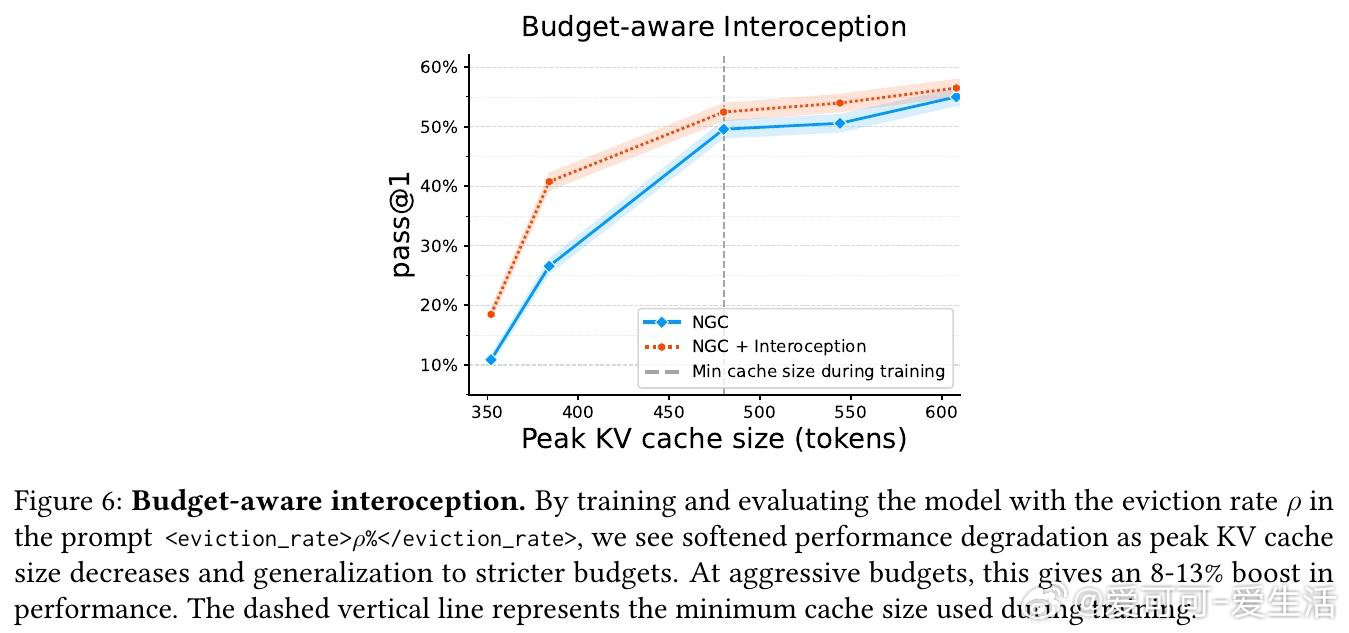
这项工作真正留下的遗产是将效率本身视为可学习能力,而非手工设计的系统优化。它为后来者打开的新门是:通过端到端优化压力同时驱动模型能力与资源效率的提升,潜在逆转"更强即更贵"的传统权衡。但尚未跨过的门槛是:方法仍需驱逐率课程来稳定训练,且在极端压缩率下性能仍会退化;此外,当前实现局限于transformer架构,对其他架构的泛化性未知。
arxiv.org/abs/2604.18002 机器学习 人工智能 论文 AI创造营