【大模型的真正机会,藏在未被压缩的 “原始数据” 里】
快速阅读:LLM 的成功建立在自然语言的高抽象度与易获取性之上。真正的研究机会隐藏在那些难以收集、冗余度极高的“原始语言”中,如视觉与机器人传感数据。
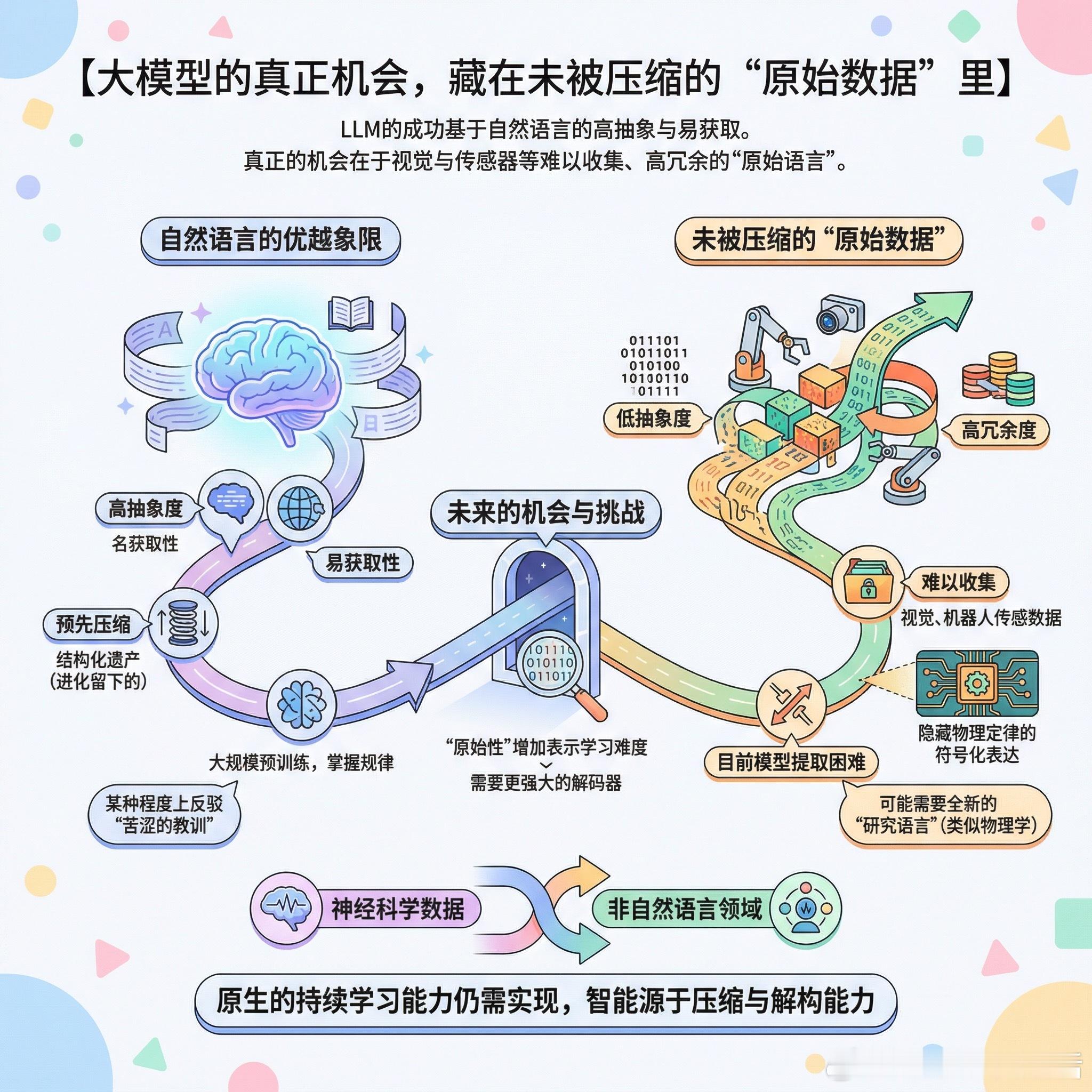
自然语言处于一个极其优越的象限:既高度抽象,又随处可见。这种属性让模型能通过大规模预训练轻松掌握其规律。
相比之下,视觉或机器人传感器数据更像是一串未经压缩的原始比特流。它们包含大量冗余,甚至隐藏着物理定律的符号化表达,目前的模型在提取这些底层特征时表现吃力。这种“原始性”增加了表示学习的难度。
有观点认为,语言模型的智能源于压缩能力。面对那些尚未被人类预先压缩过的、低抽象度的模态,模型需要更强大的解码器去完成任务。神经科学数据虽具潜力,但规模化采集仍是个难题。甚至可能需要一种全新的“研究语言”,像物理学那样提供更高层的抽象。
自然语言的成功某种程度上反驳了“苦涩的教训”。它是一个进化留下的结构化遗产,而非纯粹靠算力堆出来的产物。在这些非自然语言领域,原生的持续学习能力远未实现。
kindxiaoming.github.io/blog/2026/everything-is-language/