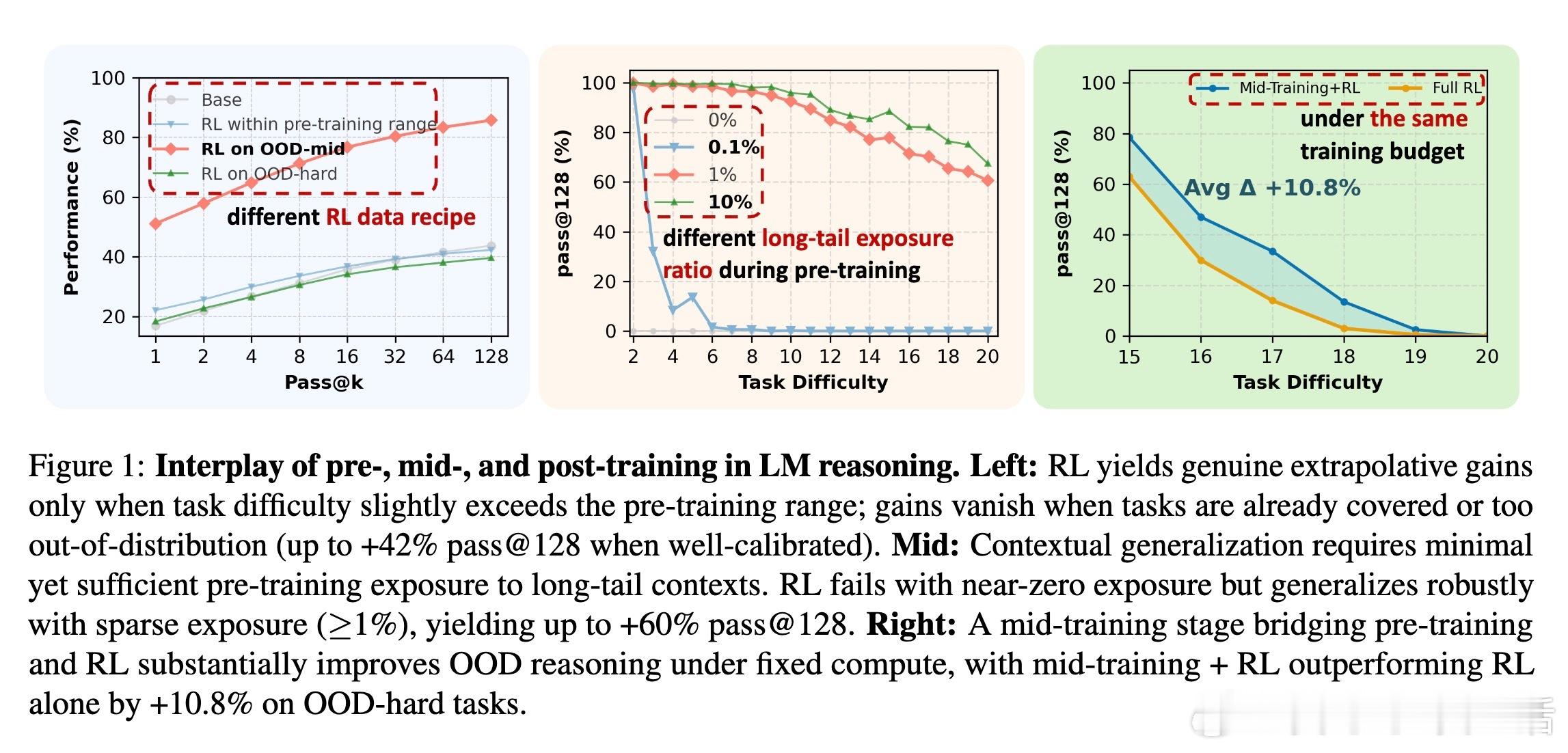
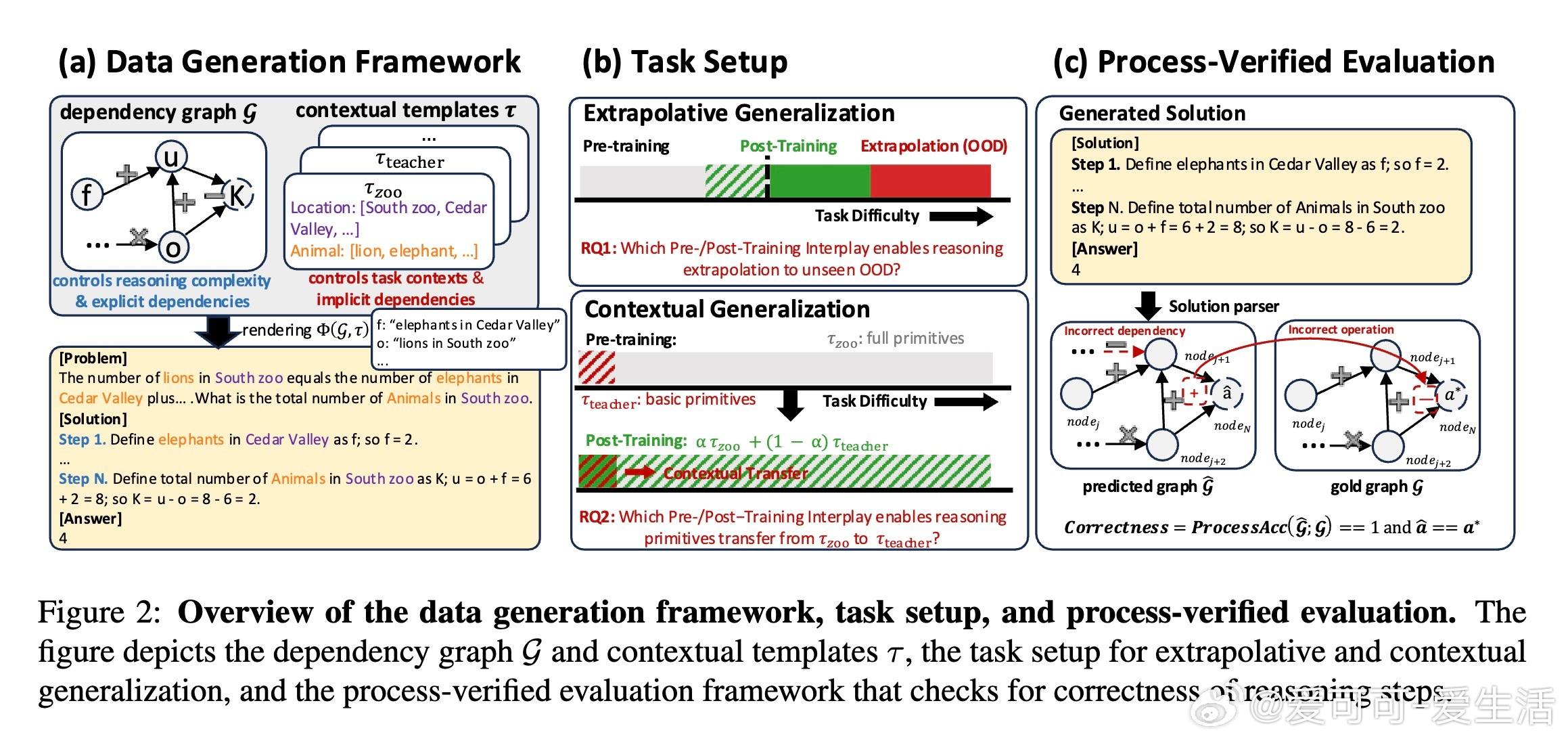
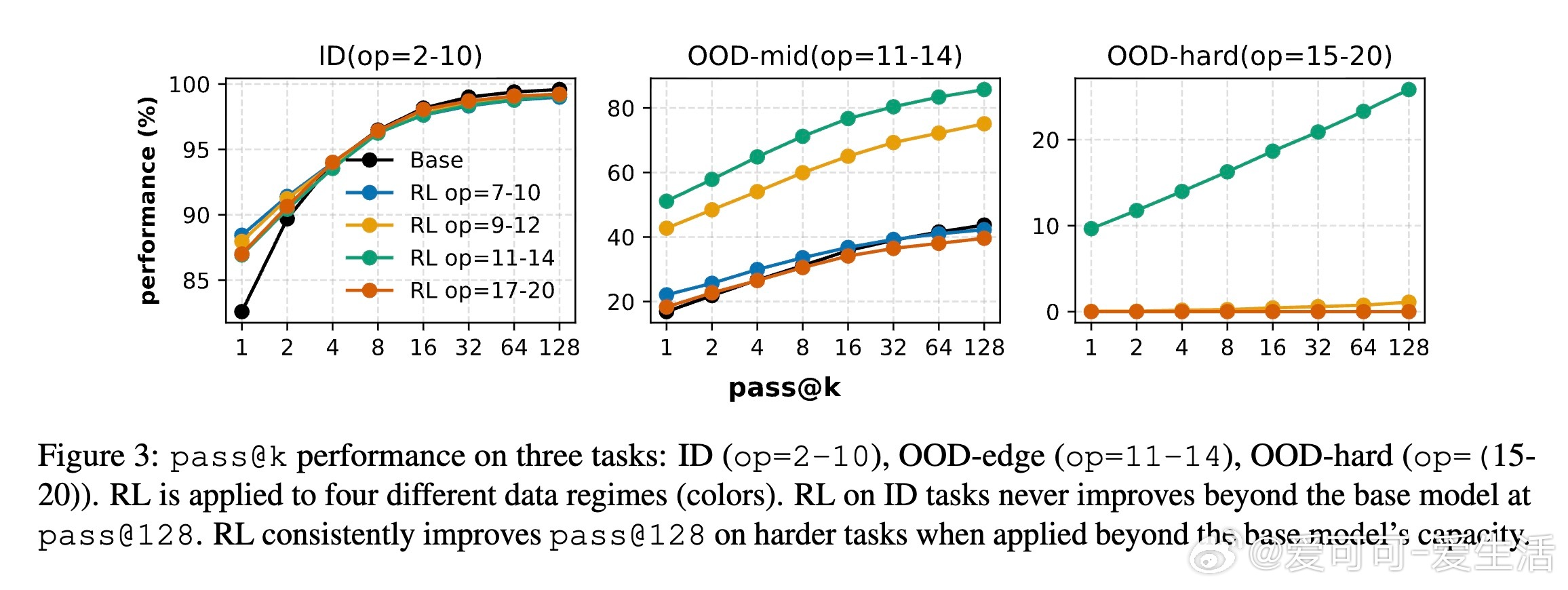
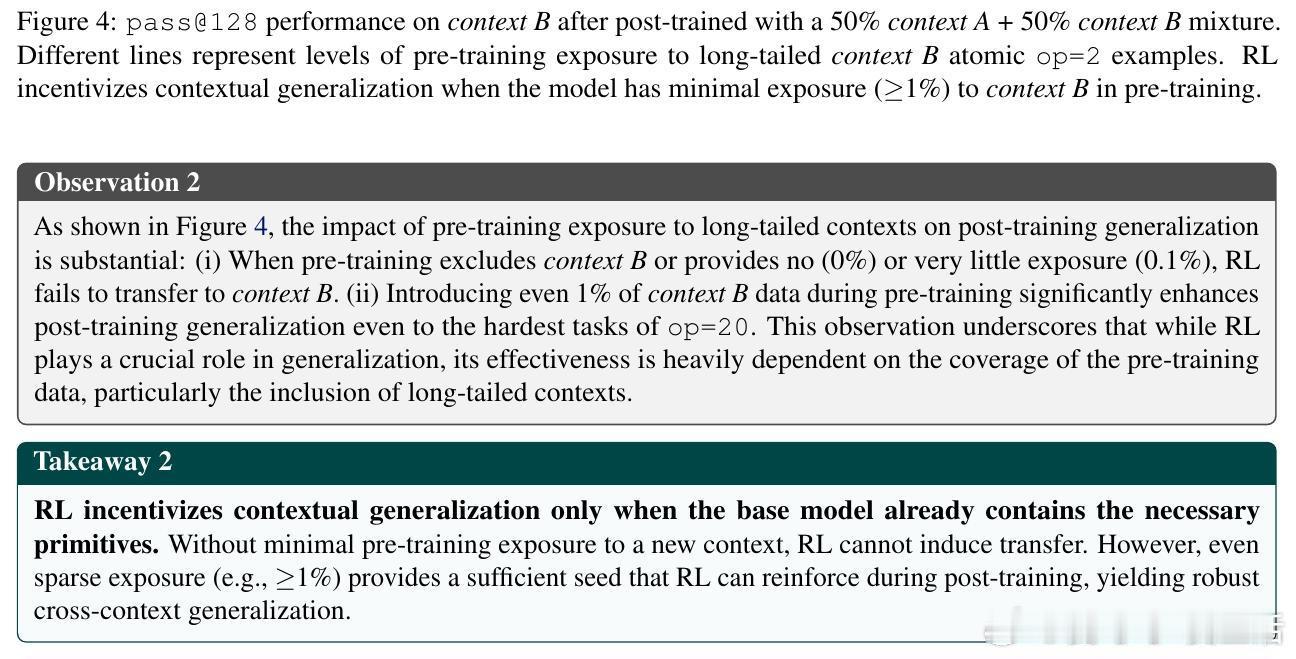
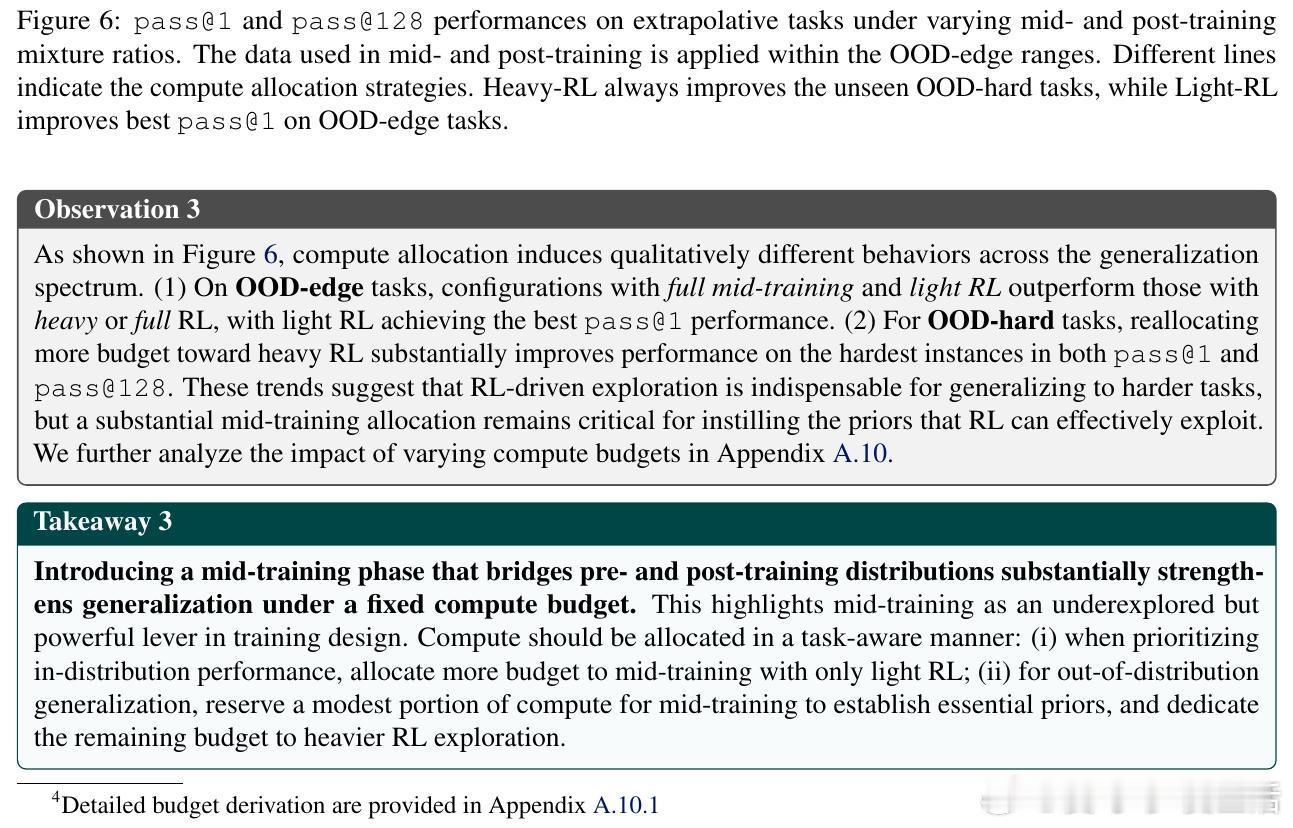
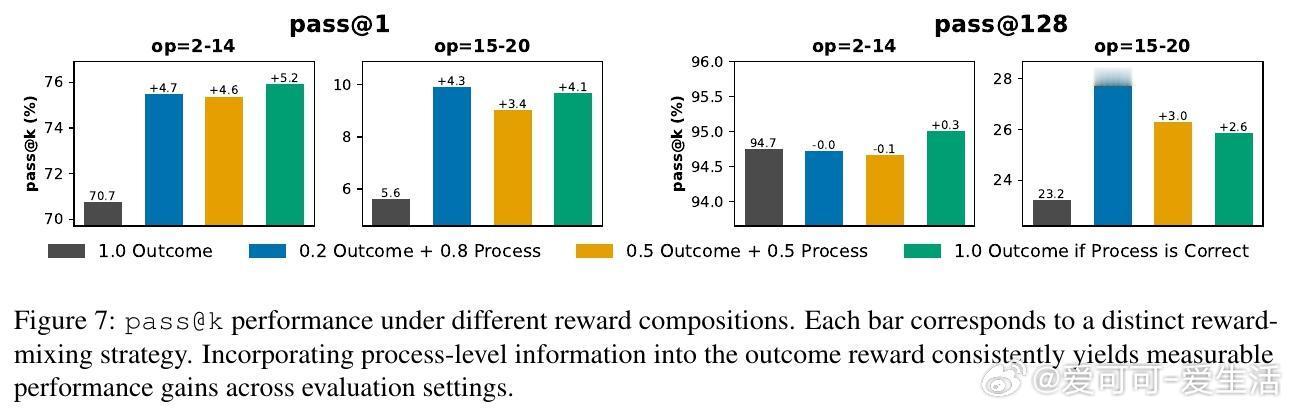
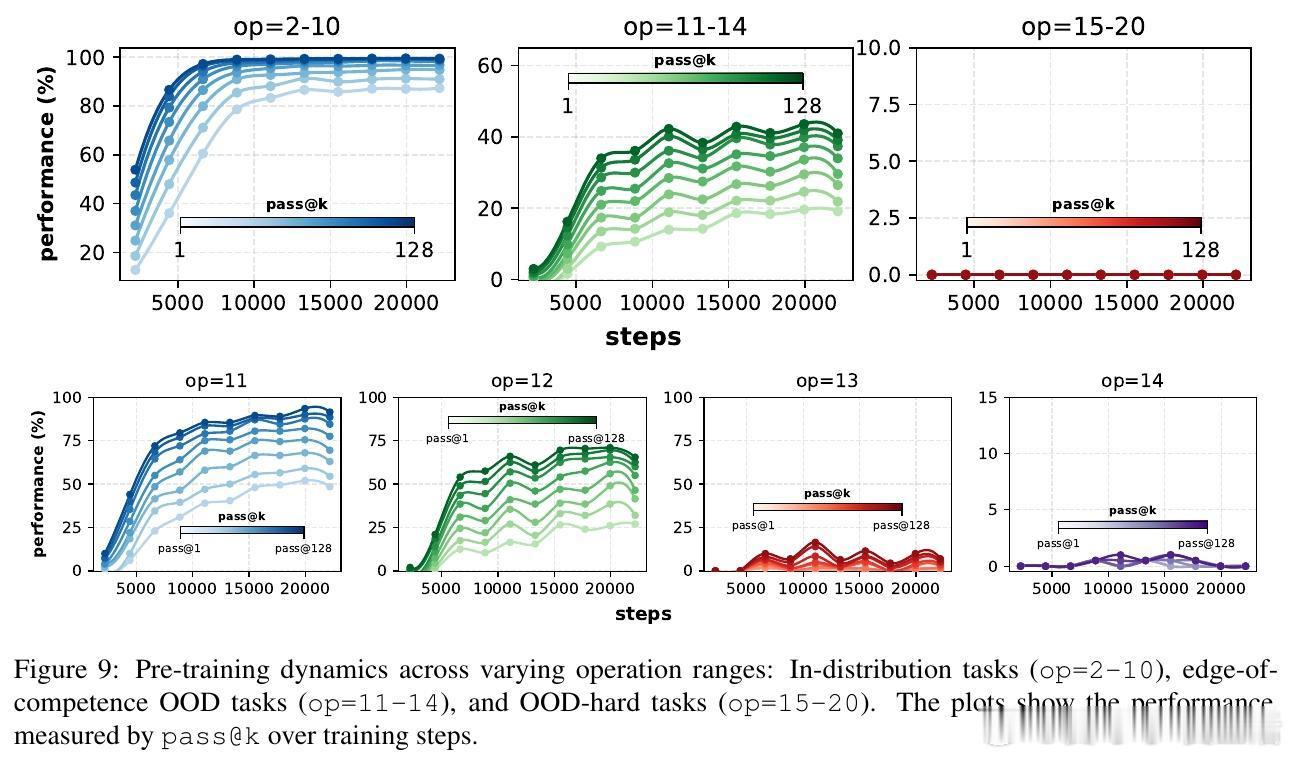
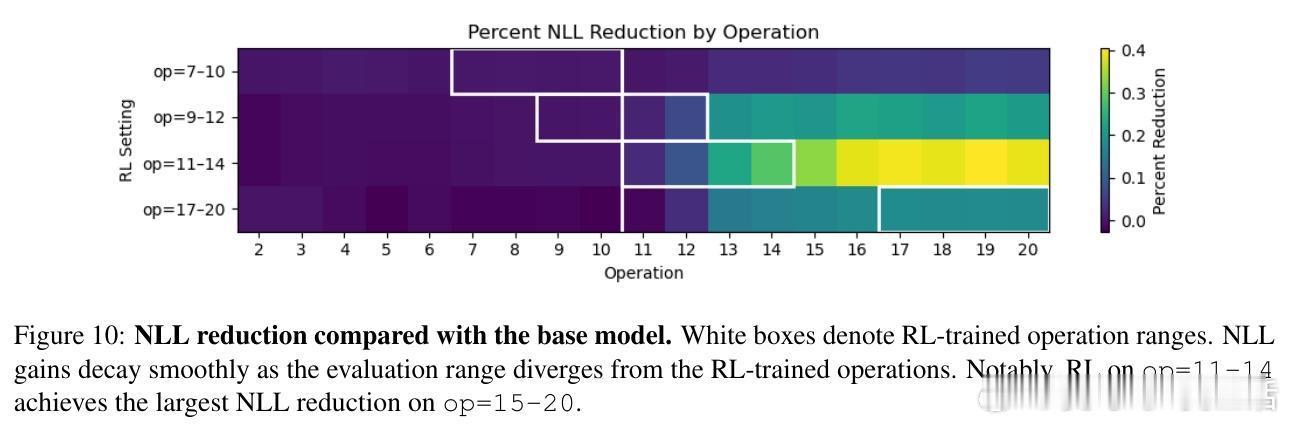
[CL]《On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models》C Zhang, G Neubig, X Yue [CMU] (2025) 近期强化学习(RL)技术在提升语言模型推理能力上表现突出,但是否真能超越预训练阶段所获得的能力,一直存在争议。原因在于现代训练流程缺乏可控性:预训练语料庞大且不透明,中间训练(mid-training)阶段常被忽视,RL目标与模型已有知识的复杂交互难以解析。为破解这一难题,本文构建了一个完全可控的实验框架,利用合成推理任务、明确的原子操作和可解析的推理步骤,系统操控预训练、中间训练和RL后训练的数据分布,精确拆解各阶段对模型推理能力的因果贡献。他们从两个维度评估模型推理能力:一是“深度泛化”,即模型能否解决比预训练更复杂的组合推理任务;二是“广度泛化”,即模型是否能迁移推理能力到不同表述上下文。实验证明:1. RL带来的真正能力提升(pass对于上下文泛化,模型必须在预训练阶段至少接触过相关的基础推理原语。即使极少量(≥1%)的预训练覆盖,也足以让RL在后训练阶段实现跨上下文的鲁棒转移。3. 中间训练作为连接预训练和RL后训练的桥梁,极大提升了模型的推理表现,尤其在计算资源固定的情况下,结合中间训练和RL的混合训练效果远超单独使用RL。4. 在奖励设计中引入过程级监督(即不仅奖励最终答案正确,还奖励中间推理步骤的正确性)有效抑制了“奖励劫持”现象,提升推理的真实性和泛化能力。该研究不仅澄清了预训练、中间训练与RL在推理能力塑造中的相互作用,也为设计更高效的训练策略提供了实证指导:- 预训练应覆盖关键基础推理原语,确保RL后训练有坚实基础可依赖;- RL数据应聚焦于模型“能力边缘”的任务,避免资源浪费和学习停滞;- 适当分配计算预算于中间训练和RL后训练,兼顾稳定性与探索性;- 奖励函数应兼顾结果正确与过程合理,促进模型生成更真实可信的推理路径。这项工作以严谨的合成数据和可验证的推理过程为基础,排除数据污染和偶然正确的干扰,确保研究结论具有高度说服力和实用价值。它为理解和提升语言模型的推理能力开辟了清晰路径,推动了智能系统在复杂推理任务中的稳健表现。详细内容见论文 arxiv.org/abs/2512.07783。