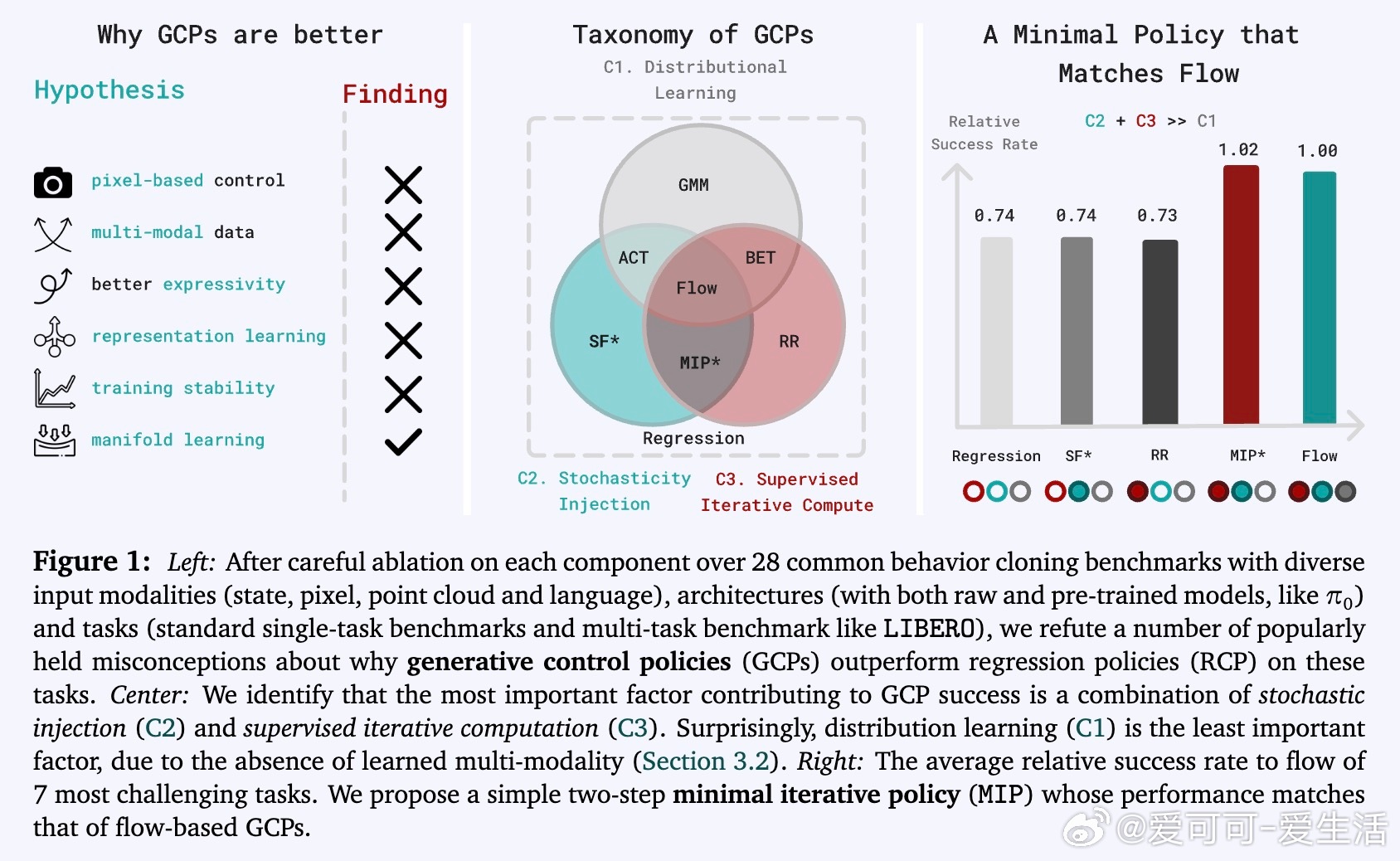
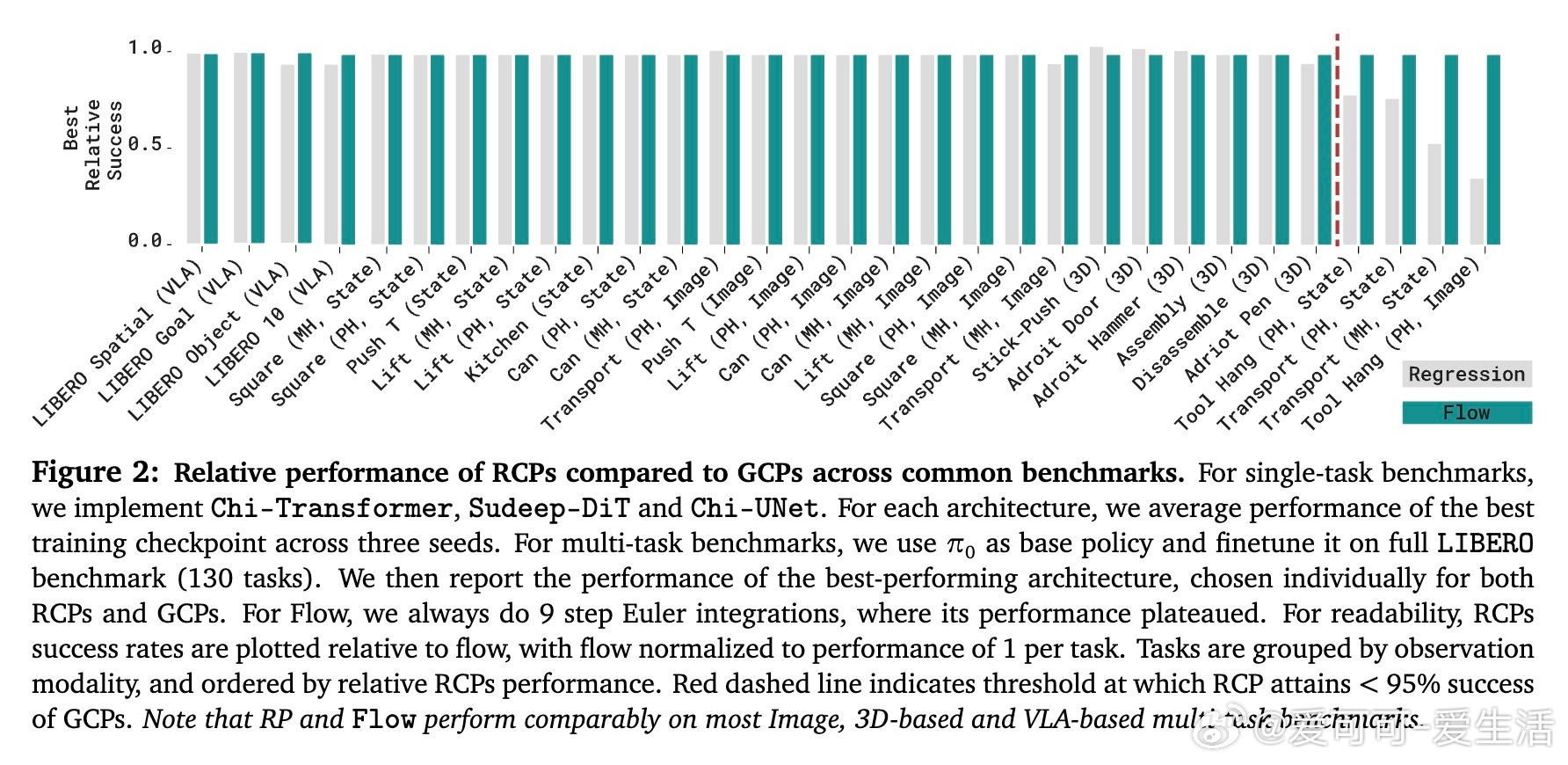
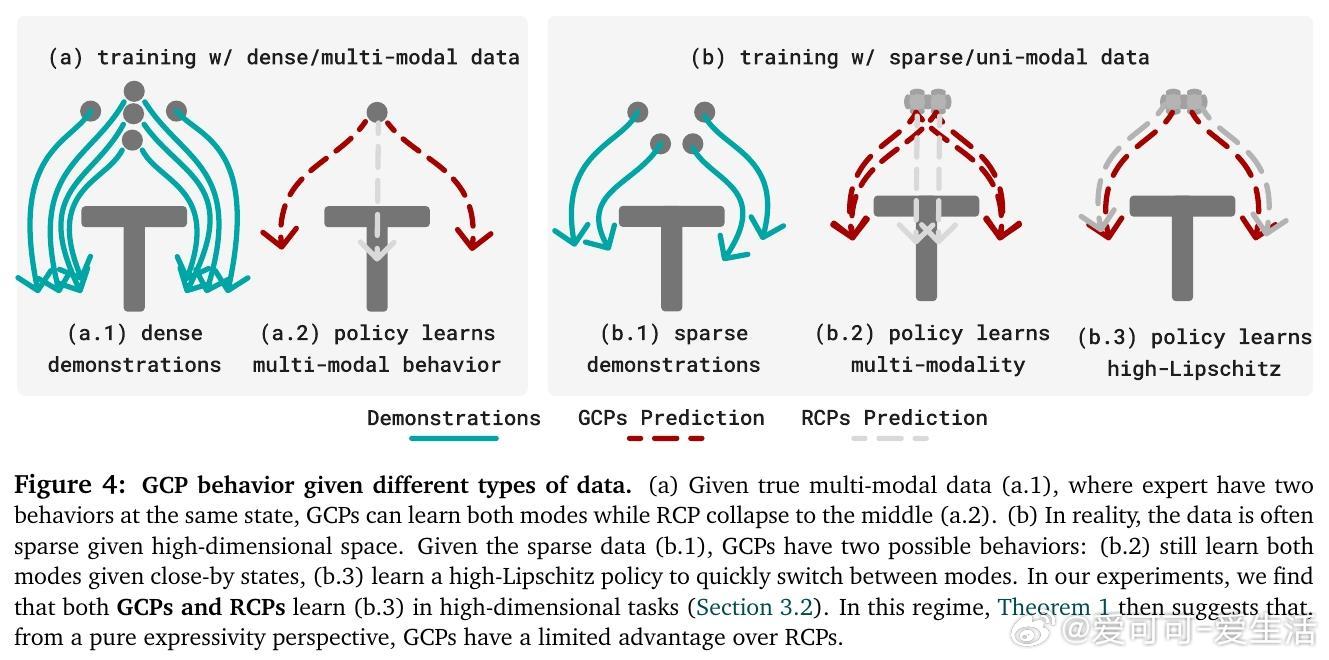
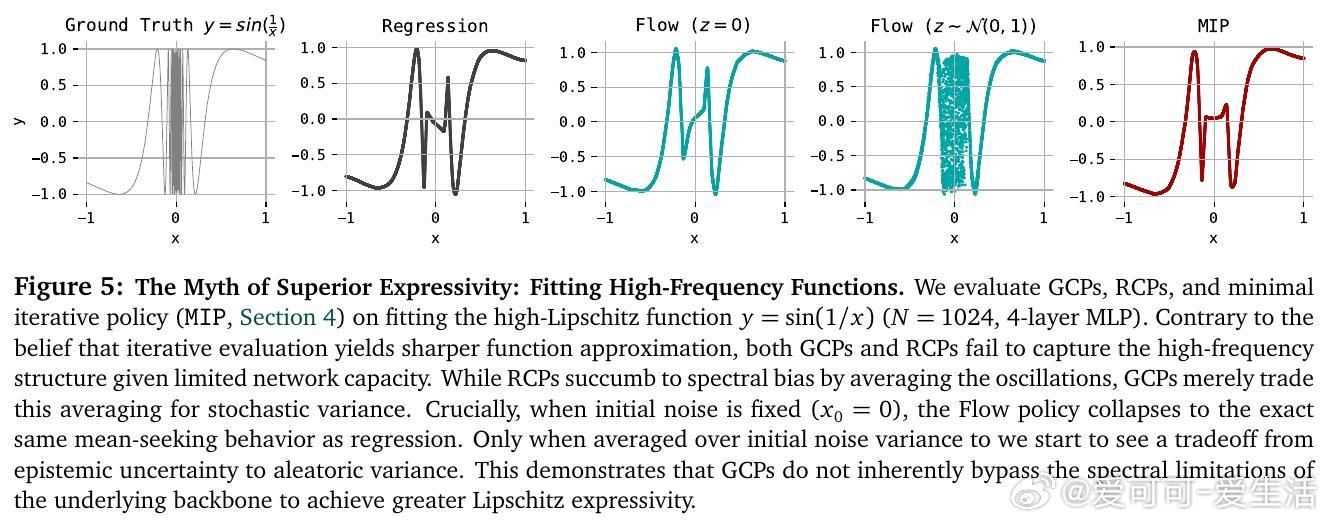
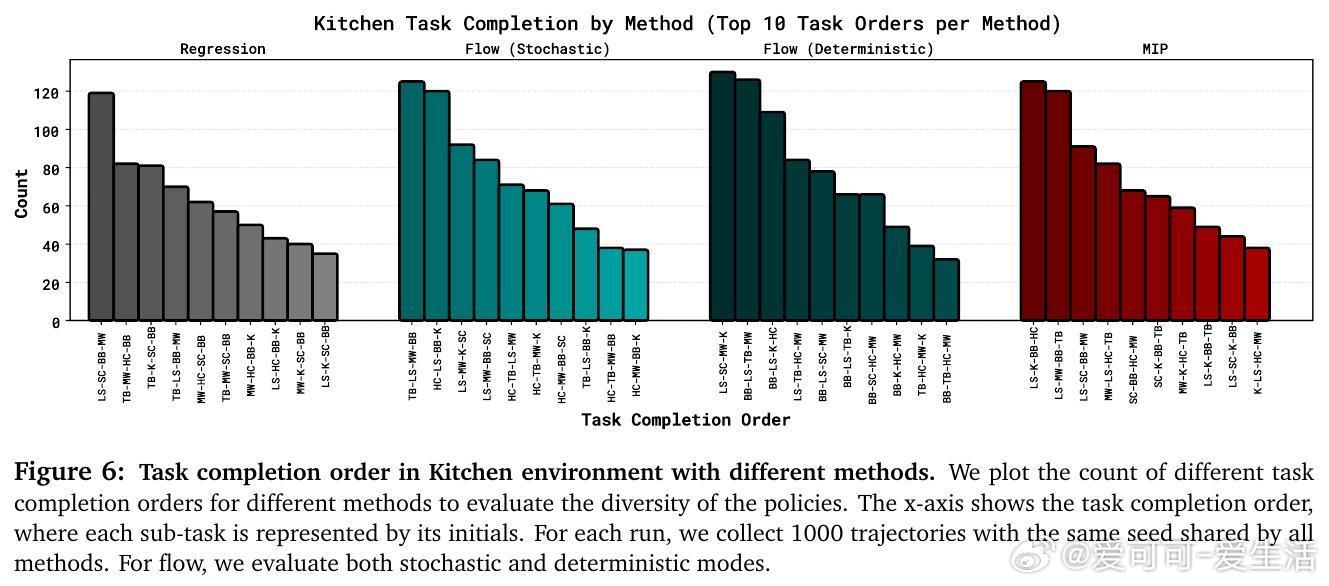
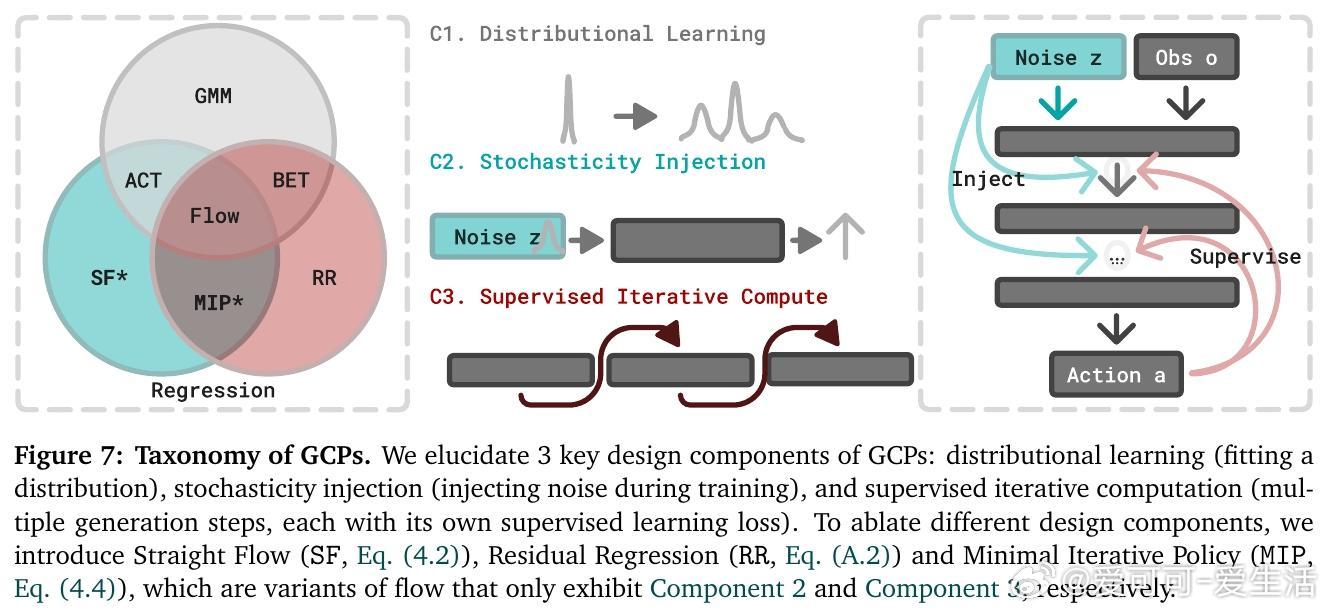
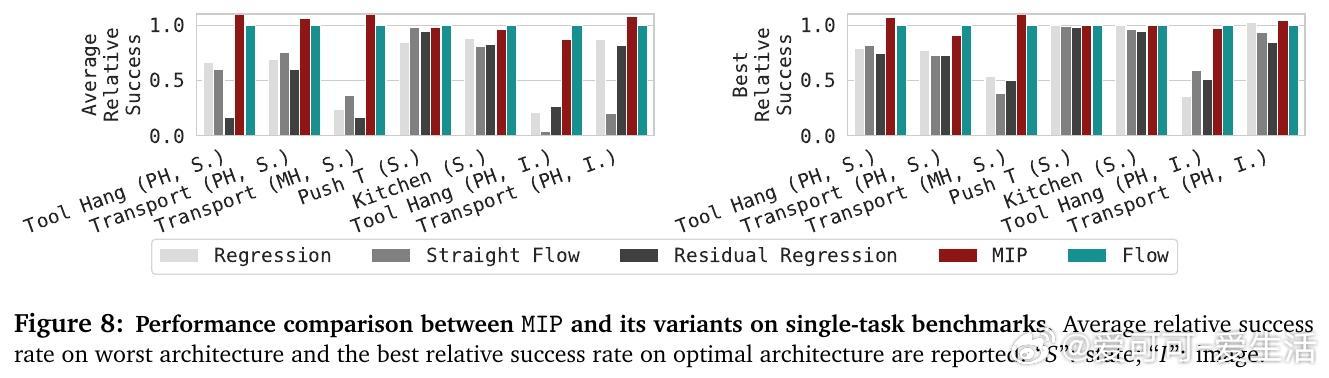
[RO]《Much Ado About Noising: Dispelling the Myths of Generative Robotic Control》C Pan, G Anantharaman, N Huang, C Jin... [CMU] (2025) 在机器人行为克隆领域,生成式控制策略(GCPs)因其优异表现备受关注,但它们成功的真正原因却长期被误解。本文系统剖析了这一现象,得出令人深思的结论。首先,作者通过28个多模态、多任务、多架构的行为克隆基准测试,发现GCPs并非因为能更好地捕捉动作的多模态分布或更复杂的函数映射而领先传统回归控制策略(RCPs)。实际上,RCPs在大多数任务中表现已十分接近GCPs,差距仅在极少数需要极高精度的任务中出现。深入分析后,研究团队提出了生成式控制策略的三个核心设计成分:1. 分布式学习(Distributional Learning):拟合观察到动作的条件分布。2. 随机性注入(Stochasticity Injection):训练时注入噪声以稳定学习过程。3. 监督迭代计算(Supervised Iterative Computation):通过多步骤迭代,每步均提供监督信号以提升性能。他们设计了一种最简迭代策略(MIP),仅结合了随机性注入和监督迭代计算,却在多种机器人控制任务上达到与复杂Flow-based GCPs同等甚至更优的表现,证明了分布拟合本身并非成功关键。更进一步,作者引入“流形遵循性”(Manifold Adherence)概念,指出GCPs和MIP表现优异的根源在于其对动作流形的良好投影能力。验证中发现,验证集的重构误差并不能反映策略的实际性能,唯有在偏离训练数据分布的状态下,策略能保持动作合理性,才能保证闭环控制效果。随机噪声的注入则是稳定迭代计算、抑制误差累积的关键。此外,架构设计对性能的影响远大于生成式与回归式策略的选择。现代Transformer、UNet等架构赋予了模型强大表达能力,而动作分块(action chunking)等设计也显著提升策略表现。这项研究颠覆了“GCPs因多模态和复杂表达力而优越”的传统观点,强调了:- 真正关键是“随机性 + 监督迭代”的训练范式带来的内在归纳偏置;- 精准拟合动作分布非必需,策略应聚焦于控制性能本身;- 设计简洁高效的迭代策略可大幅节省训练与推理成本。未来工作将探索这一范式在强化学习、预训练及长远规划中的适用性,并推动机器人控制策略设计走向更科学、简洁的方向。详细论文及代码:simchowitzlabpublic.github.io/much-ado-about-noising-project/github.com/simchowitzlabpublic/much-ado-about-noisingarxiv.org/abs/2512.01809这不仅是对机器人控制策略设计的重新审视,更是对“生成”与“控制”本质差异的深刻洞见。理解本质,方能创新。