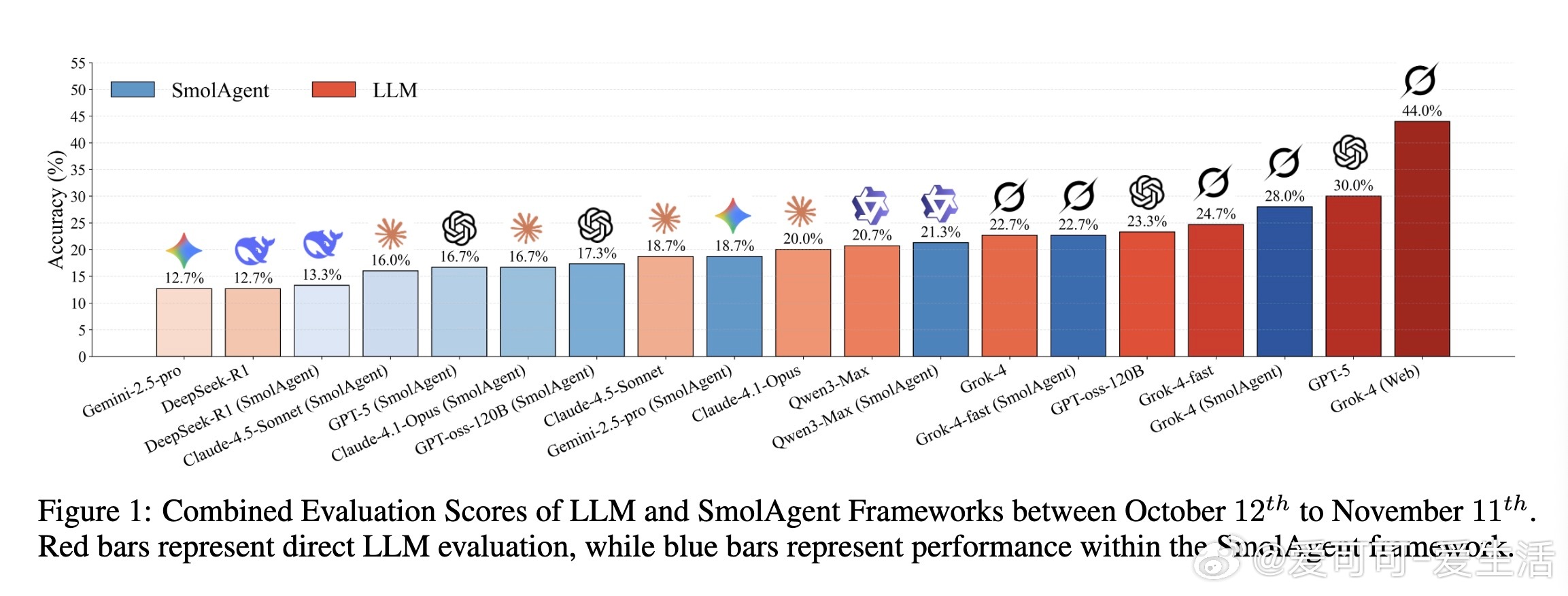
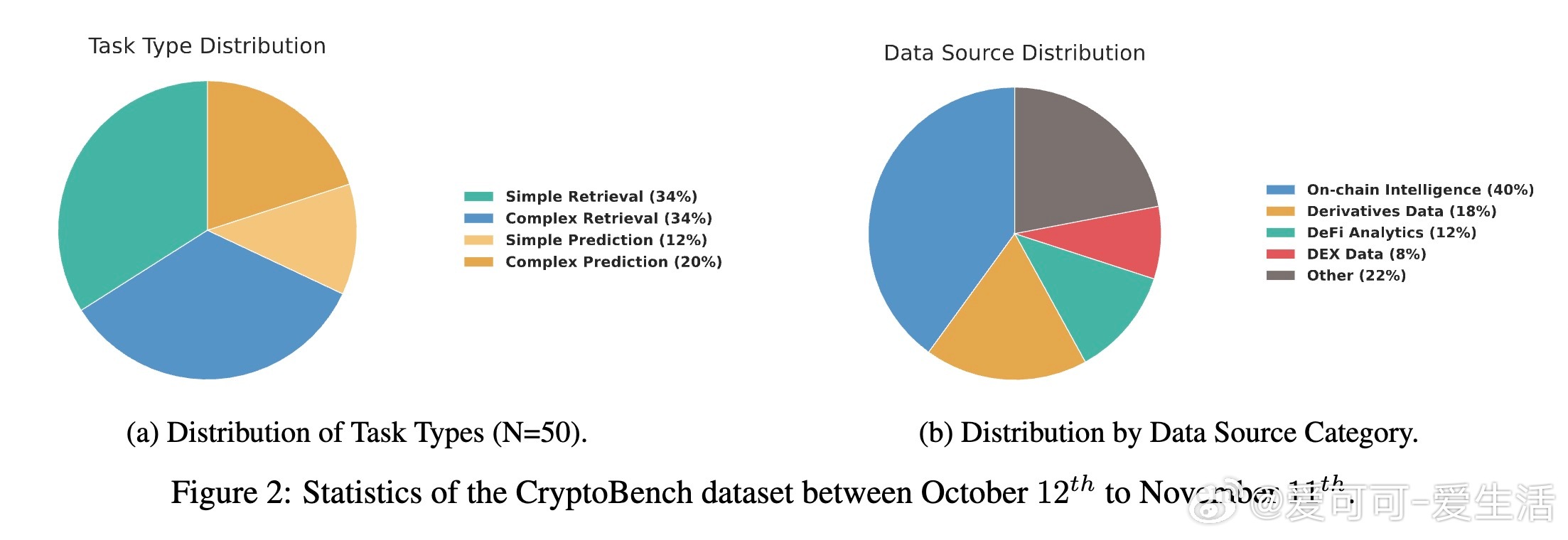
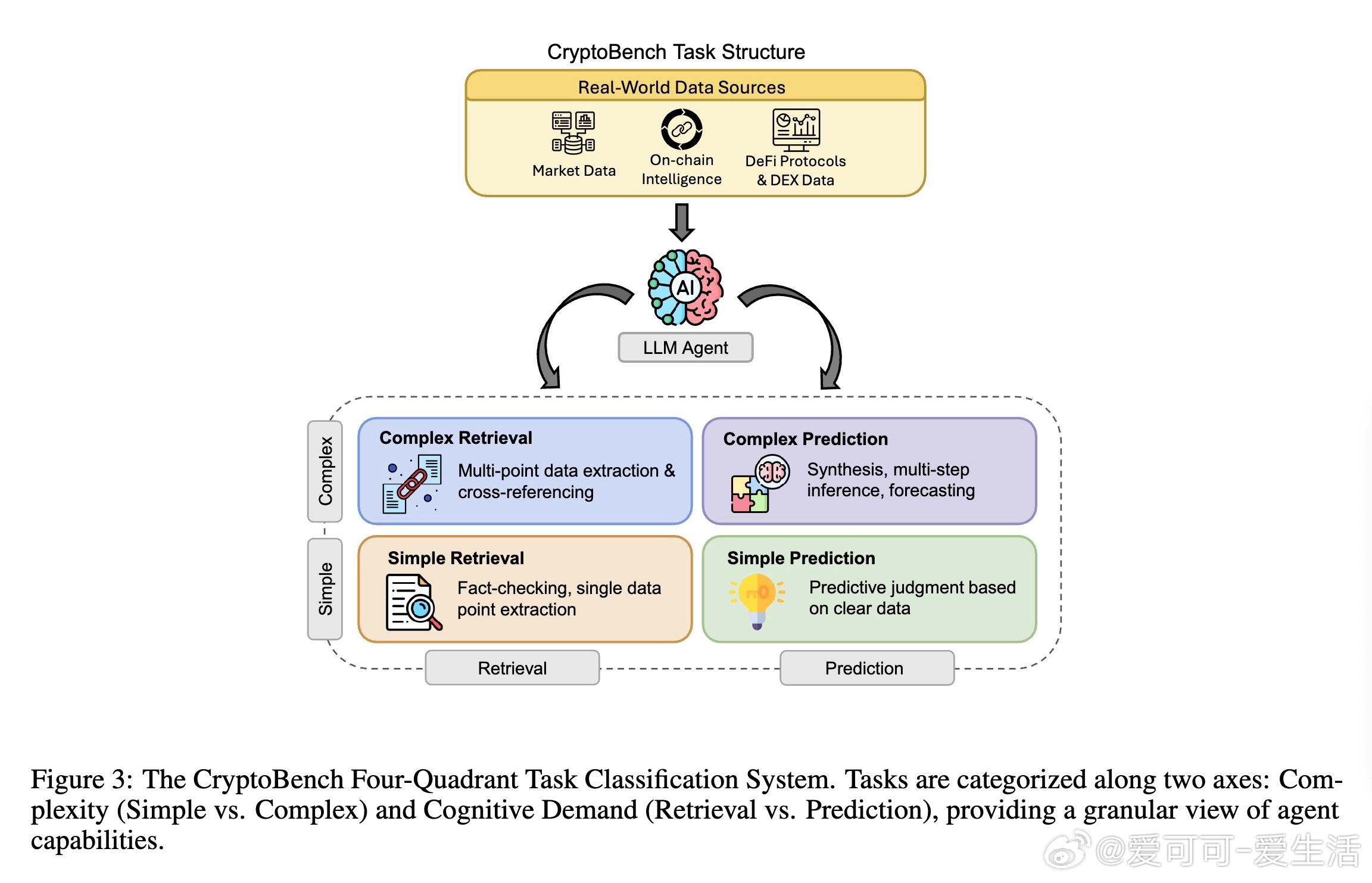
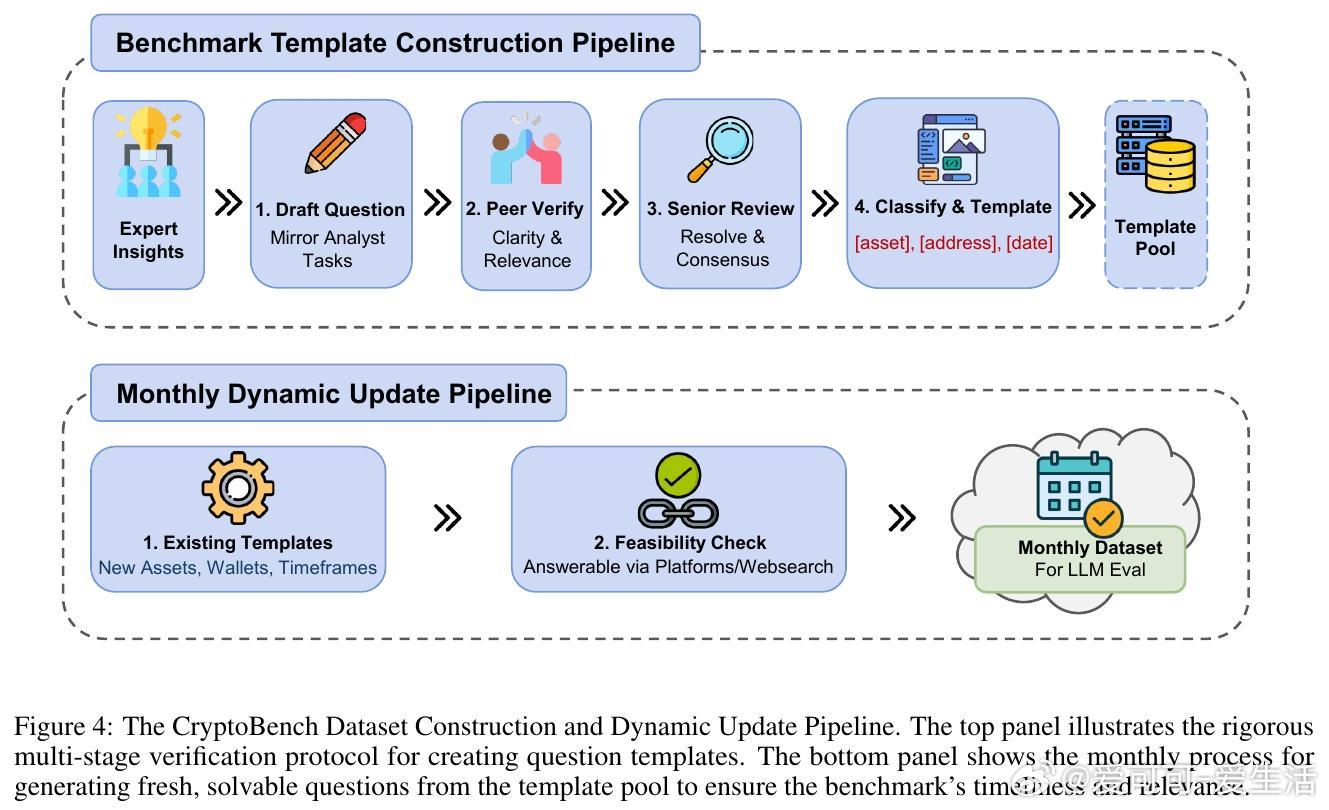
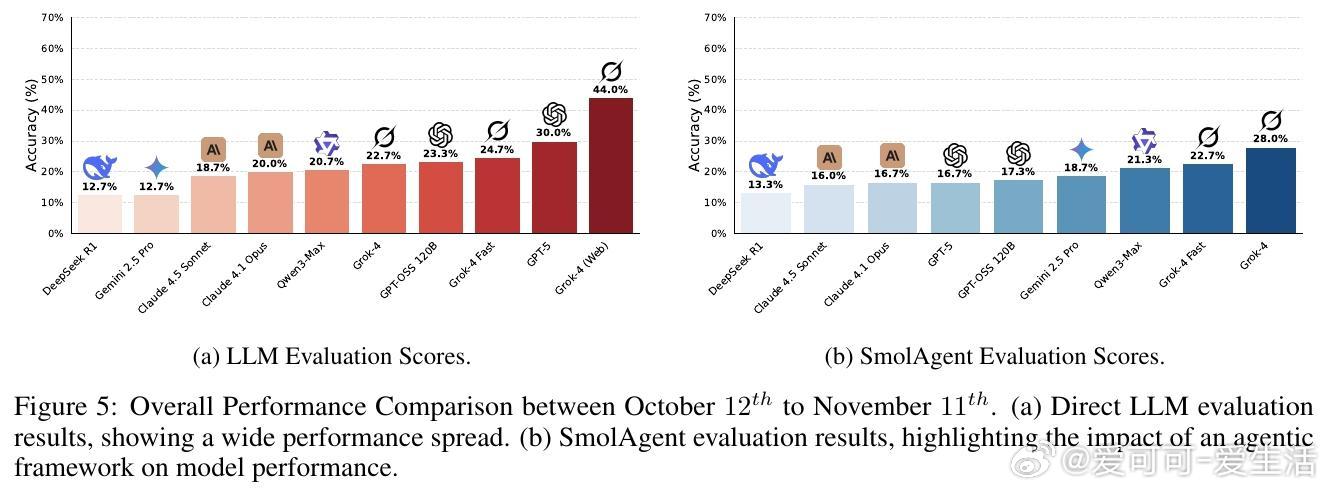
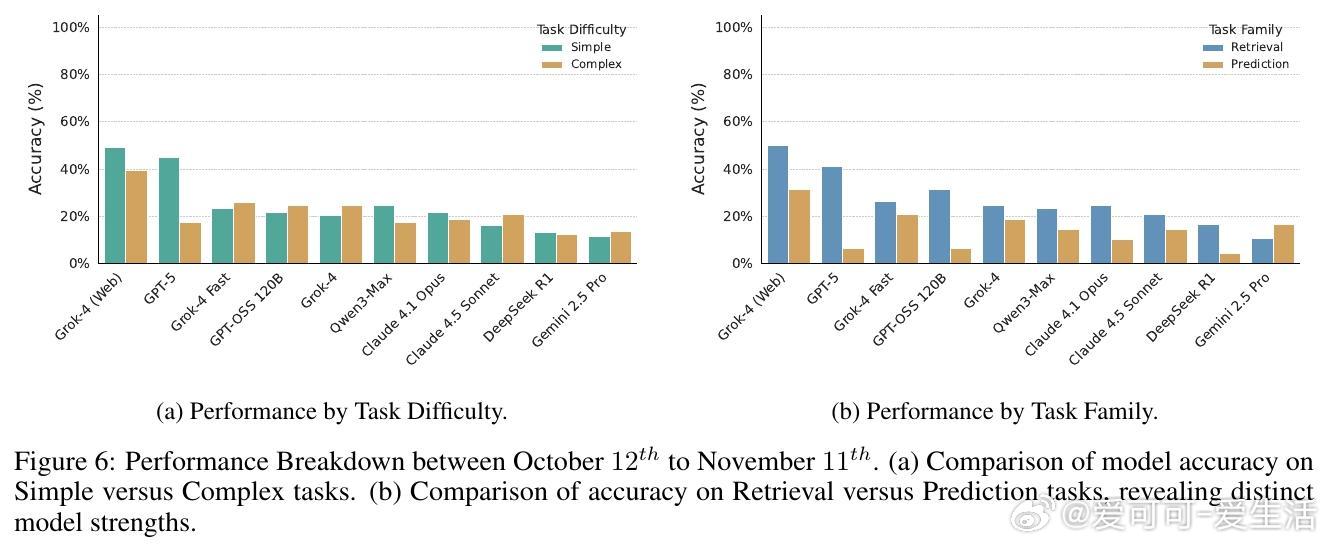
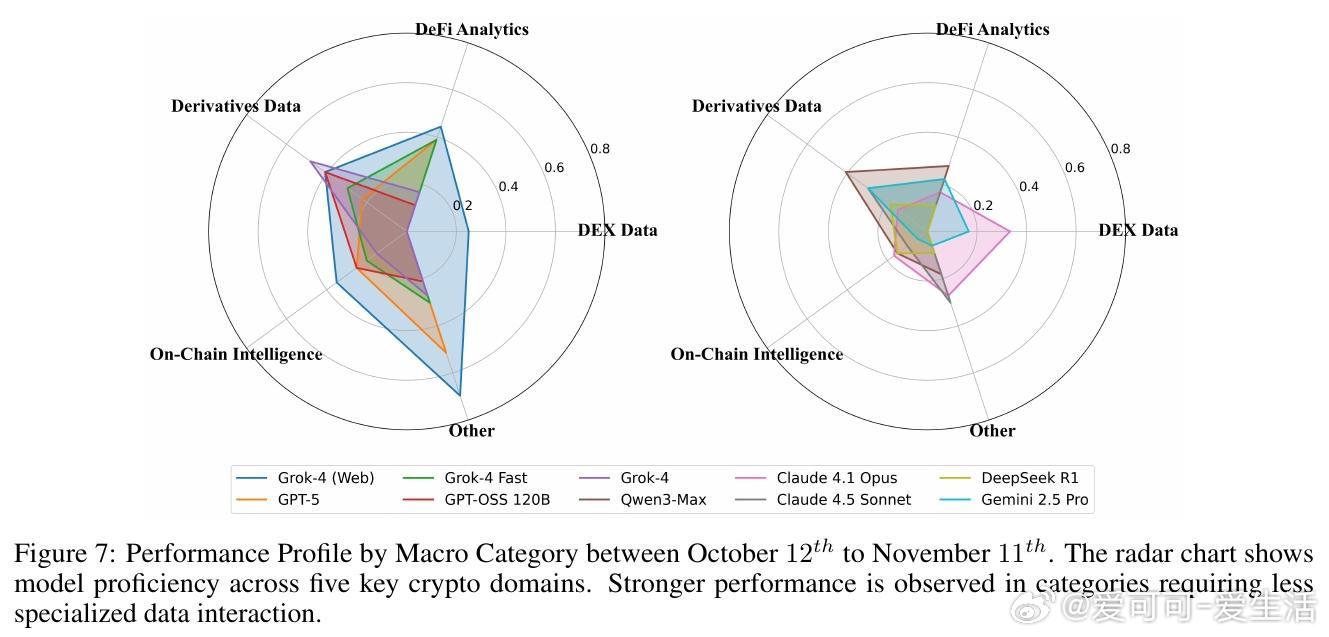
[CL]《CryptoBench: A Dynamic Benchmark for Expert-Level Evaluation of LLM Agents in Cryptocurrency》J Guo, S Huang, Z Yao, Y Zhang... [Princeton University] (2025) 在加密货币领域,专业分析需求极端的时效性、多源数据综合与预测能力,传统通用LLM评测难以满足。本文提出了首个针对加密专业场景的动态评测基准——CryptoBench。CryptoBench由资深加密分析师团队设计,每月更新50道题,涵盖“简单检索”、“复杂检索”、“简单预测”与“复杂预测”四大任务象限,真实复刻分析师日常工作流程。评测要求模型不仅能快速准确地检索链上和DeFi实时数据,还需进行多源信息融合与未来趋势预测。实验涵盖10款顶尖LLM(包括Grok-4系列、GPT-5、Claude 4.5等),在直接问答与智能代理框架下测试。结果揭示了显著的“检索-预测不平衡”——大部分模型在信息查找上表现出色,但在预测推理任务上严重不足,甚至出现虚假推断和信息陈旧等问题。这表明当前模型更像高效搜索引擎,而非真正的金融分析师。此外,代理框架的引入改变了模型表现排名,暗示模型原始智能与实际工具协同能力存在差异。失败案例分析显示,模型常犯的错误包括:优先非权威来源、依赖过时数据、数据整合错误及预测幻觉。CryptoBench强调专家级金融分析的独特挑战:极端的时间敏感性、对抗性环境及复杂多样数据的实时整合。它不仅是衡量LLM在加密领域实际能力的重要工具,也指明了未来发展方向——需要构建专门面向预测推理和实时动态数据的领域模型与复杂代理系统。全文详见:arxiv.org/abs/2512.00417