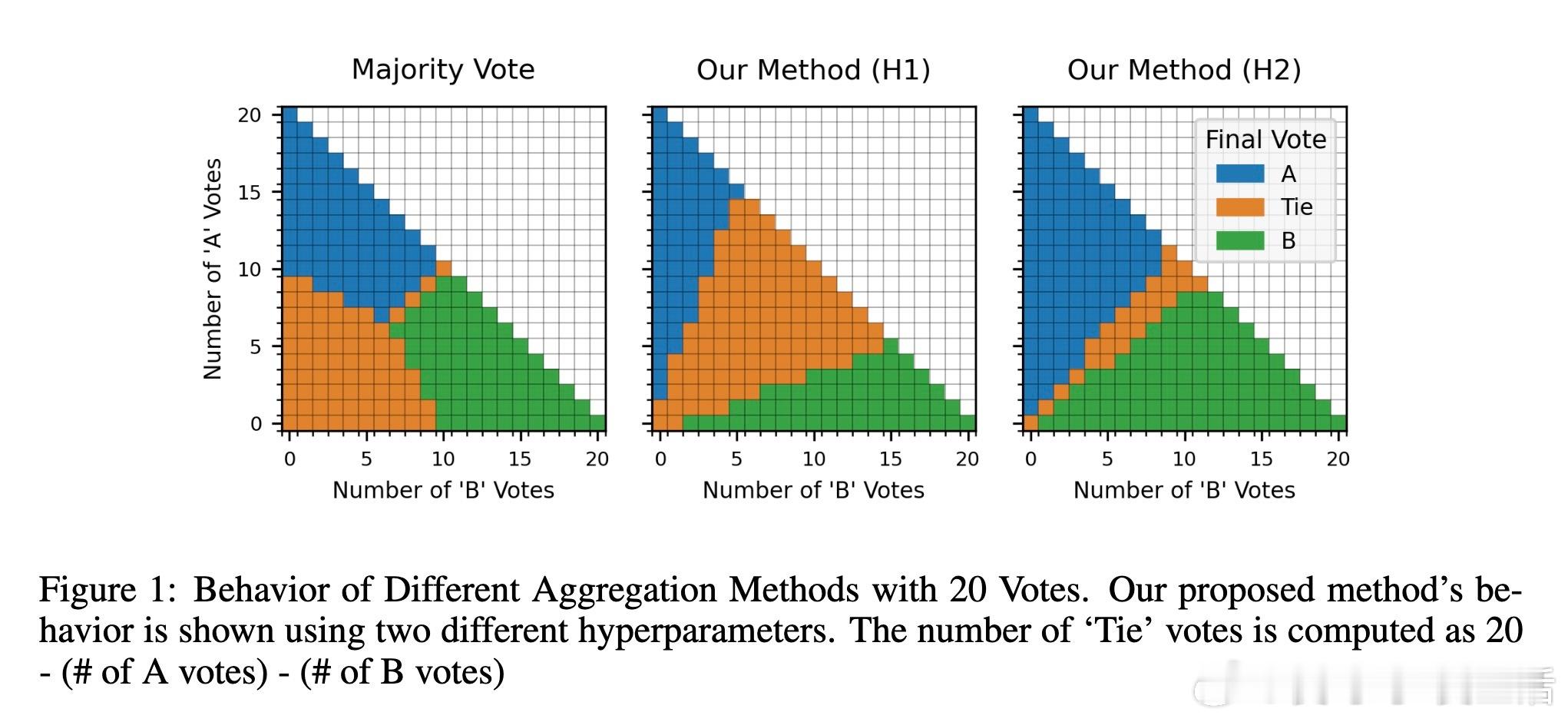
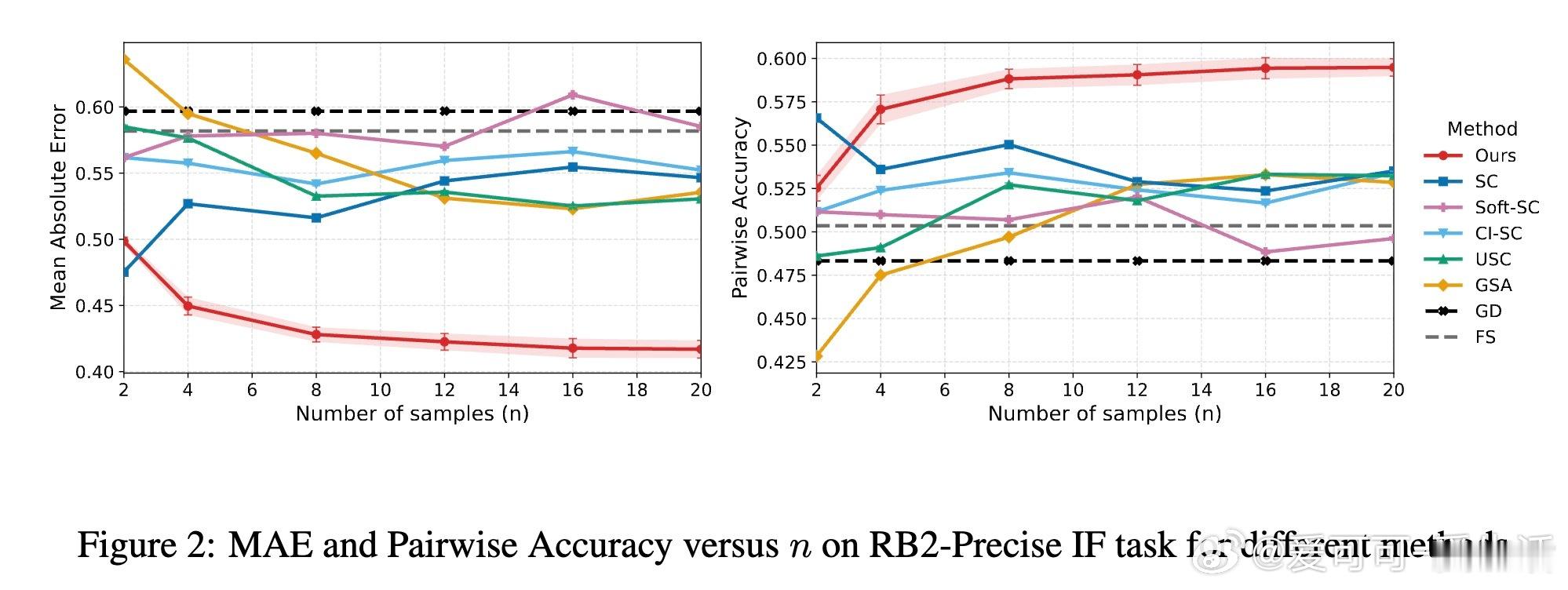
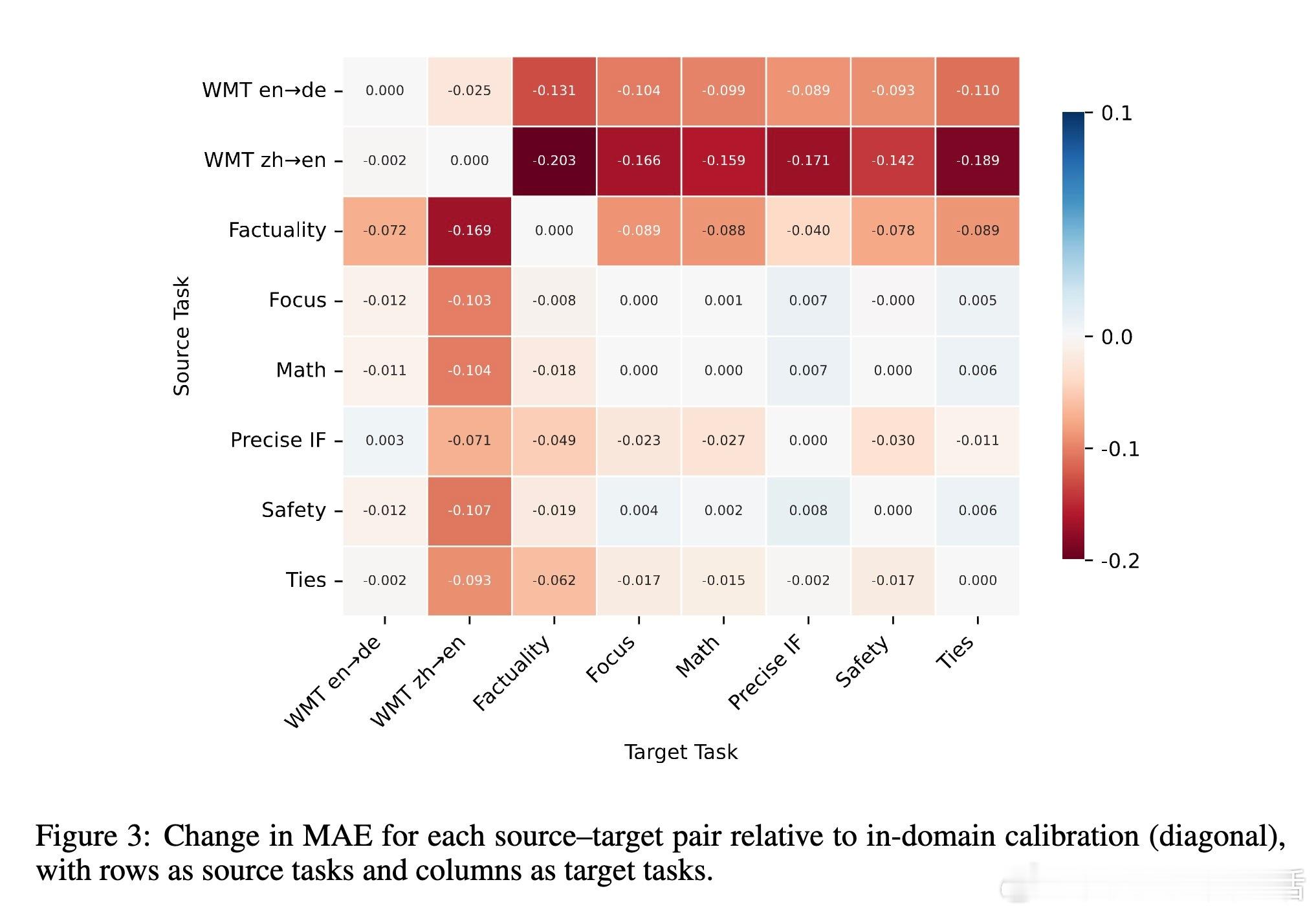
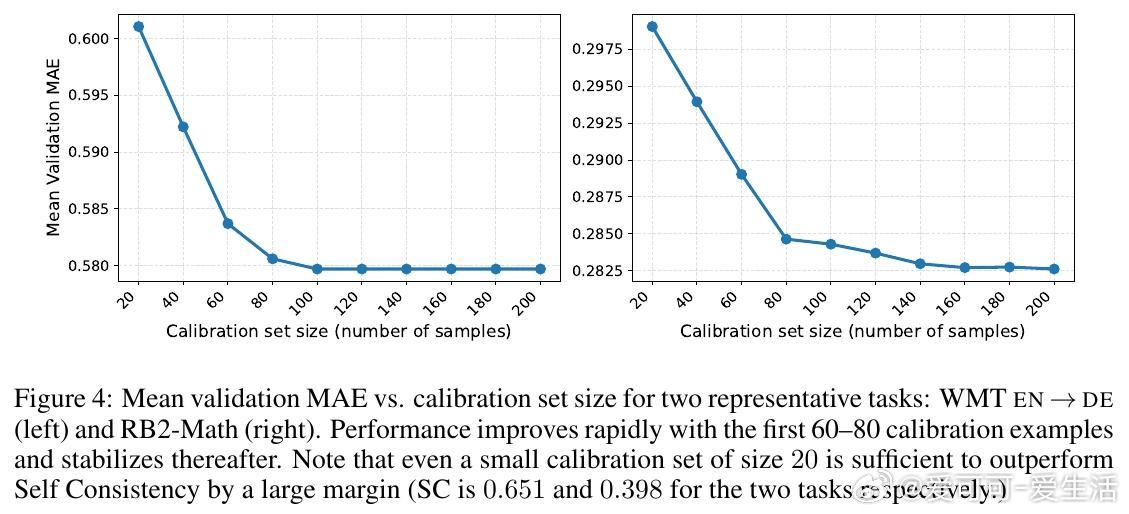
[LG]《Distribution-Calibrated Inference time compute for Thinking LLM-as-a-Judge》H Dadkhahi, F Trabelsi, P Riley, J Juraska... [Google & Google DeepMind] (2025) 近年来,Thinking大语言模型(LLM)作为“评判者”在文本生成质量评估中备受关注。单次判断存在噪声,常用的投票聚合方法(多数投票、软自洽等)在允许平局时表现不稳定,难以有效反映投票分布中的细腻信息。针对这一“平局困境”,本文提出了一种基于推理时计算(Inference-Time Compute, ITC)的分布校准聚合方法。核心思想是利用Bradley-Terry-Davidson模型对三类偏好(支持A、支持B、平局)进行参数化建模,结合“极性”(非平局票的边际差距)与“决定性”(非平局率)两个特征,区分微弱边际与强烈共识,避免简单多数投票忽略证据强度的缺陷。模型参数通过在小规模校准集上最小化离散等级概率评分(Discrete Ranked Probability Score,DRPS)进行拟合,保证概率预测良好校准,与评价指标(MAE)完美对齐。在机器翻译(WMT23)与奖励模型评测(Reward Bench 2)等多项真实任务中,分布校准聚合显著降低MAE并提升成对准确率,甚至超越个体人类评分员的表现。研究还揭示了允许平局选项有助于缓解LLM的系统性偏见(如位置偏见),并且不同模型与提示词对平局概率敏感,强调推理聚合的鲁棒性和适应性。实验证明,适当分配推理时计算资源,结合统计学严谨的分布模型聚合,能将嘈杂的单次判断转化为更可靠的评估结果,为自动化评测体系奠定坚实基础。未来工作将探索更广泛的序数和多分类输出,以及跨任务的参数迁移和鲁棒性验证。全文详见:arxiv.org/abs/2512.03019