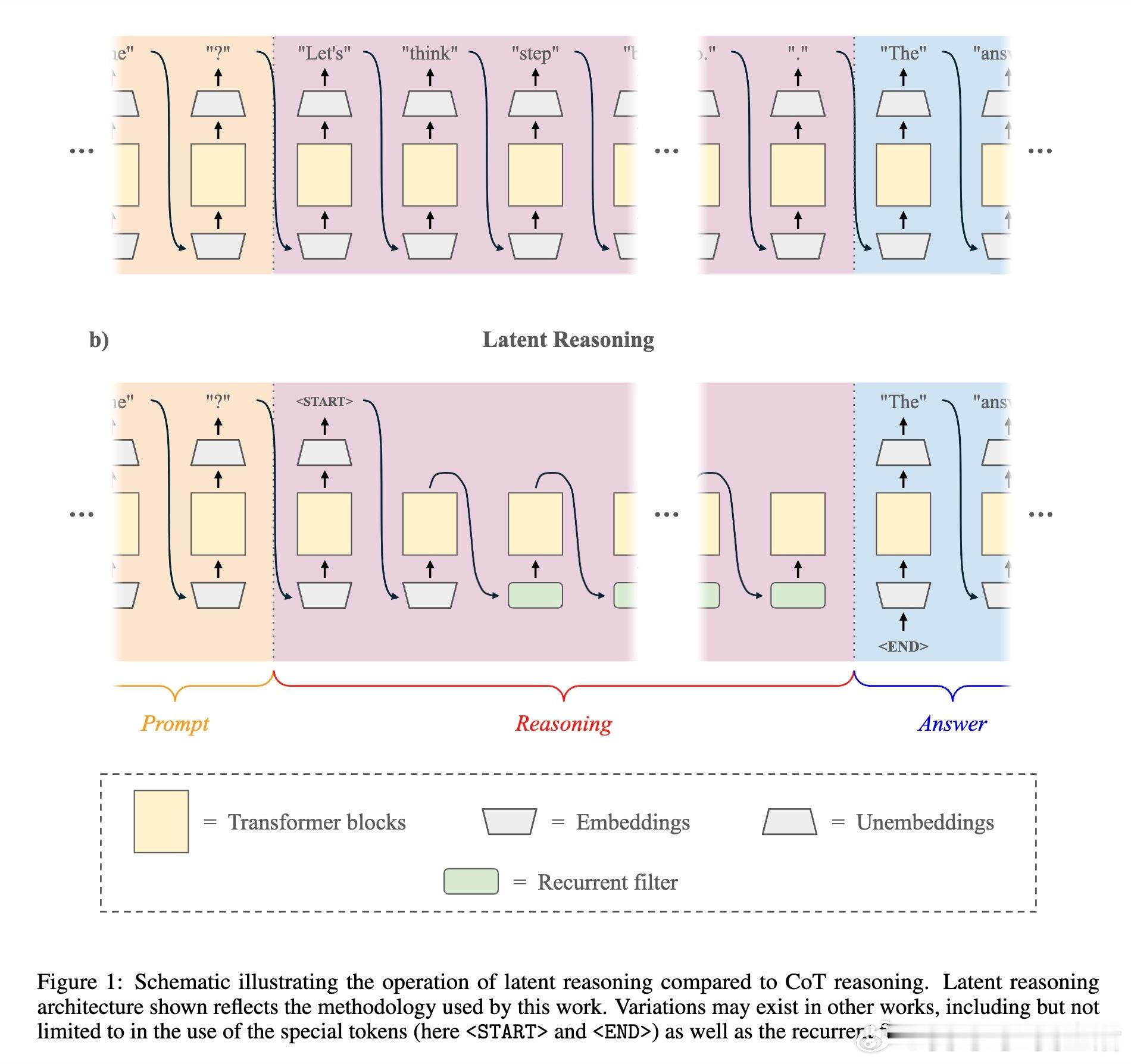
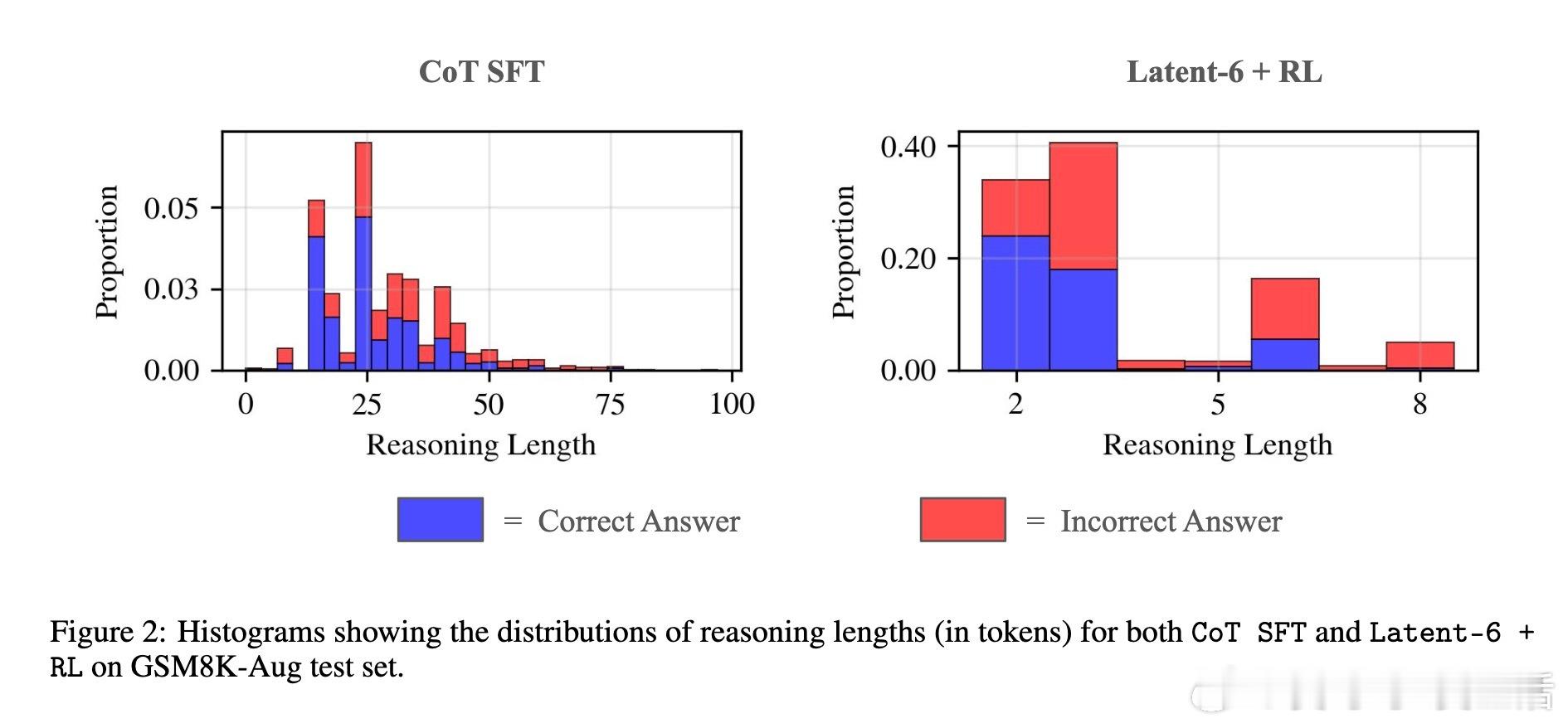
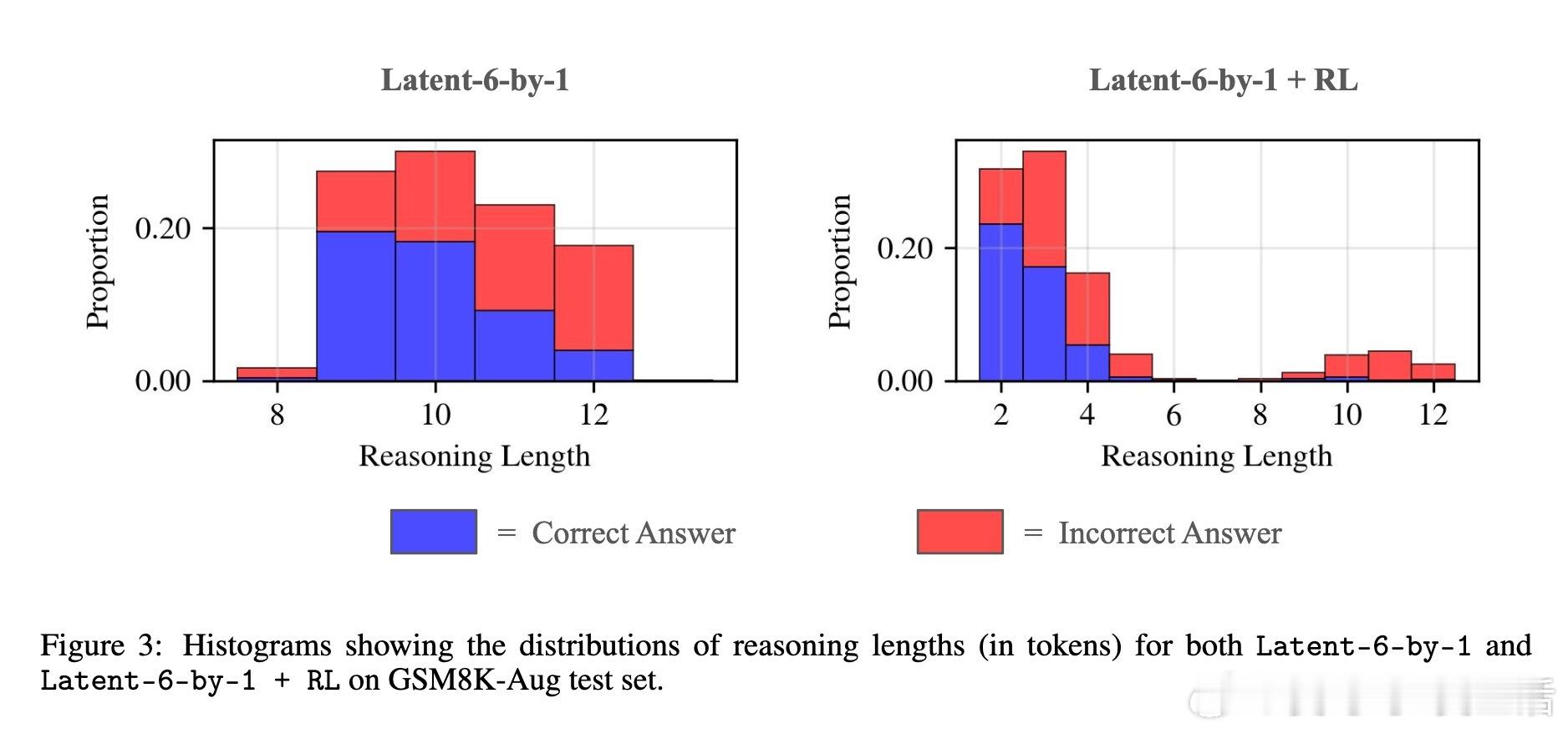
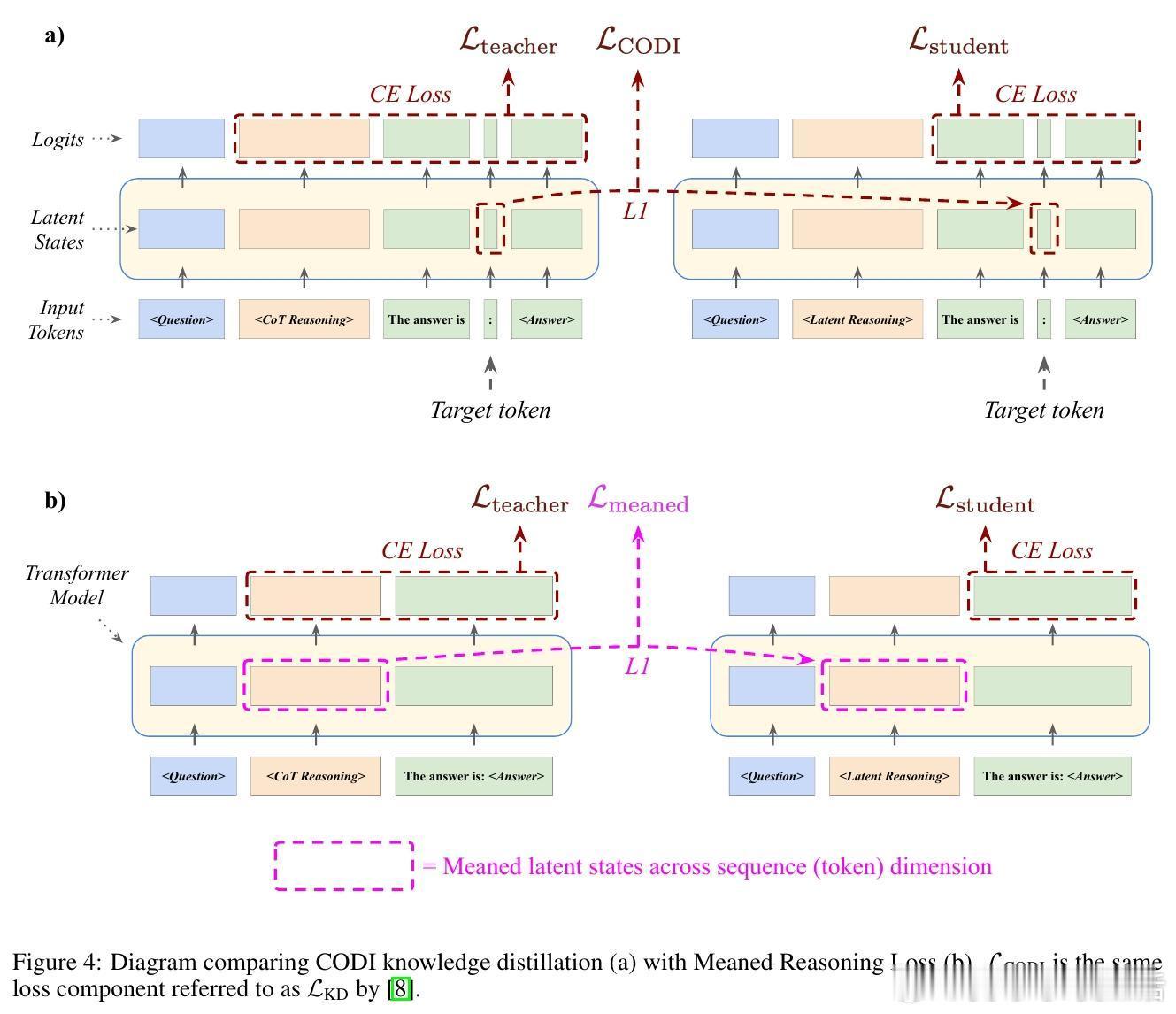
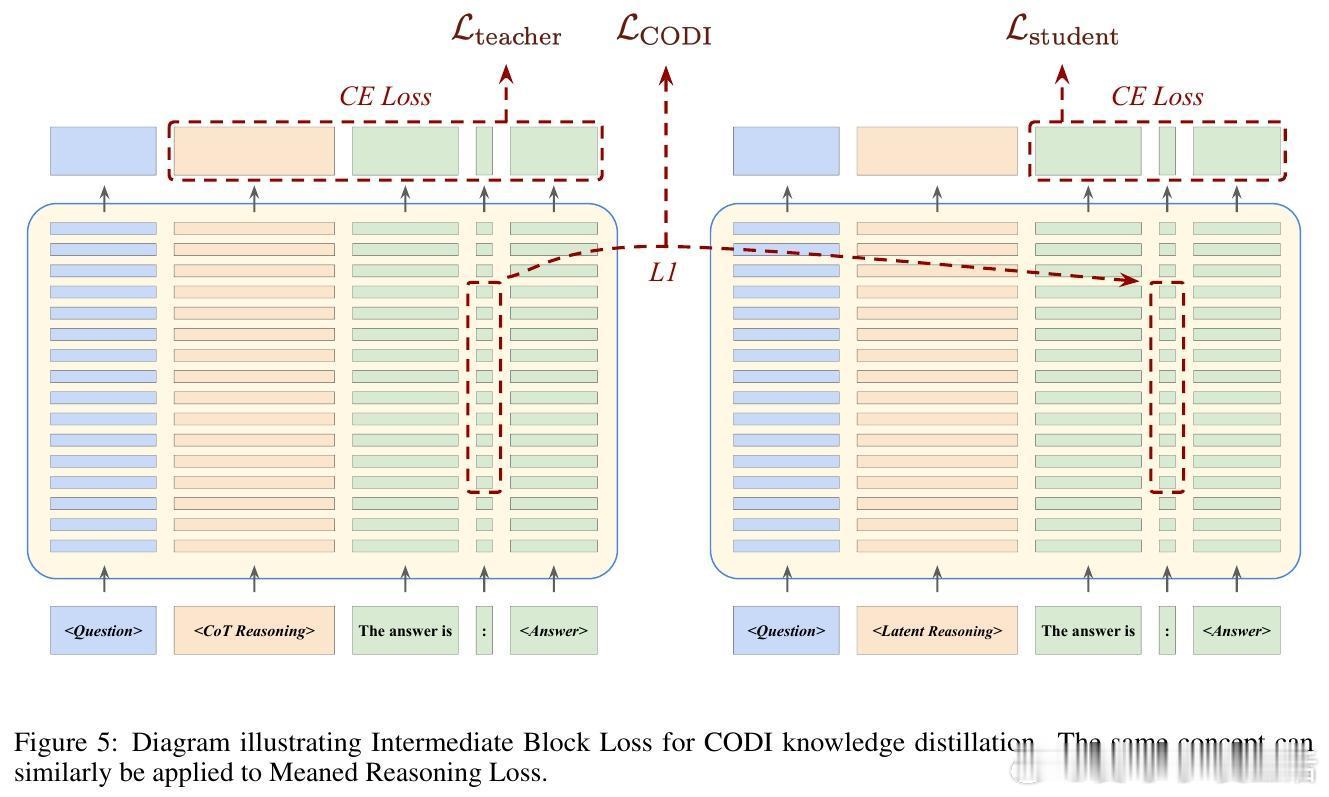
[LG]《Learning When to Stop: Adaptive Latent Reasoning via Reinforcement Learning》A Ning, Y Kuo, G Gomes [University of Virginia & CMU] (2025) 在大型语言模型的推理效率提升中,链式思维(Chain-of-Thought, CoT)虽有效,但存在“过度思考”导致计算资源浪费的问题,同时受限于以人类语言为媒介的推理方式。最新提出的“潜在推理”(Latent Reasoning)技术,通过直接将Transformer模型的隐状态传递作为推理过程,突破了语言符号的限制,实现了推理长度的大幅压缩。本文提出了一种自适应潜在推理方法,结合监督微调(SFT)与强化学习(RL),让模型能自主决定何时终止推理,动态调整推理长度。具体做法是为潜在推理模型增加一个二分类头,在每一步判断是否继续推理。强化学习阶段采用Group Relative Policy Optimization算法,通过正确性奖励、格式惩罚与相对长度奖惩机制,促使模型在保证准确率的同时最大程度减少推理长度。实验证明,基于Llama 3.2 1B和GSM8K-Aug数据集,经过强化学习优化的潜在推理模型相比传统CoT推理,推理长度平均减少52.94%,且准确率不受影响。这表明模型能够根据问题难度“少想多快”,或“多想以求精”,有效节约计算和内存资源。实验中还发现推理长度与错误率呈正相关,强化学习使模型倾向于对简单问题缩短推理过程,对难题延长思考时间。此外,文章探讨了潜在推理的知识蒸馏问题,尝试了多种损失函数设计(如Meaned Reasoning Loss和Intermediate Block Loss),但未能超越现有方法CODI,显示潜在推理知识蒸馏仍具挑战性,需未来深入研究。总的来说,这项工作展示了通过自适应潜在推理和强化学习,有望突破当前语言模型推理效率瓶颈,推动更智能、高效的模型设计。未来计划扩展至更多模型和任务,优化训练参数,尝试不同架构改进,并持续探索知识蒸馏技术。全文及代码详见:github.com/apning/adaptive-latent-reasoning 论文链接:arxiv.org/abs/2511.21581