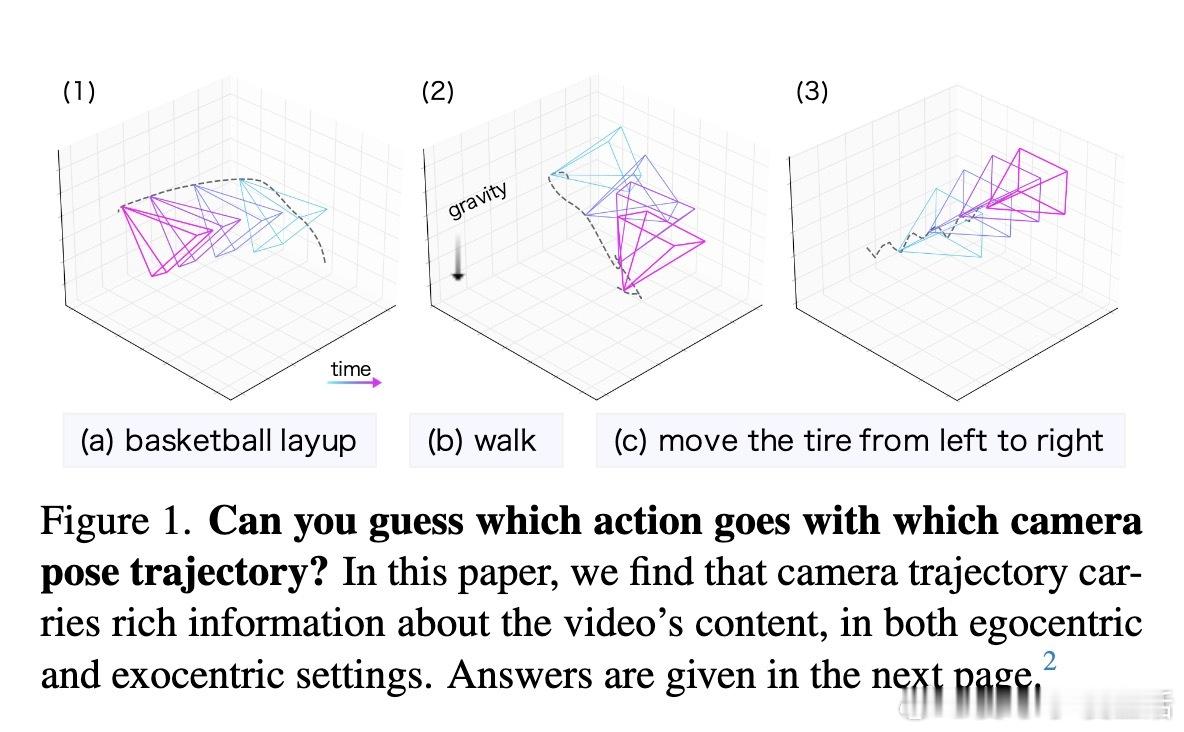
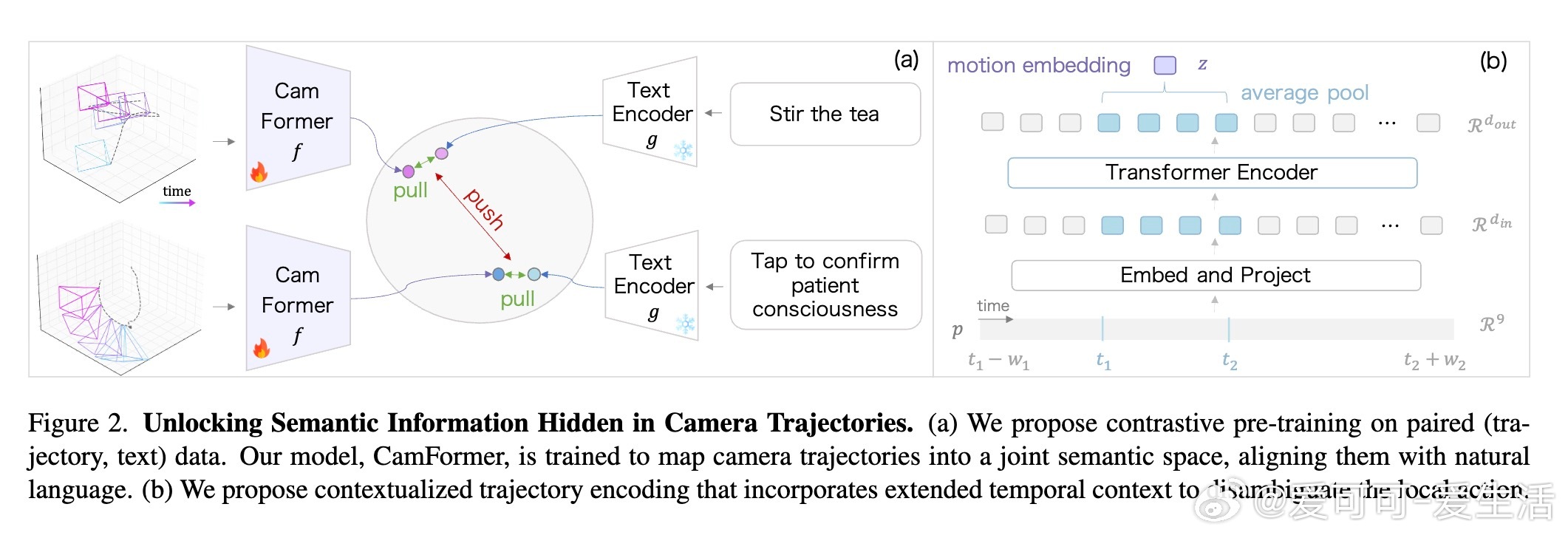
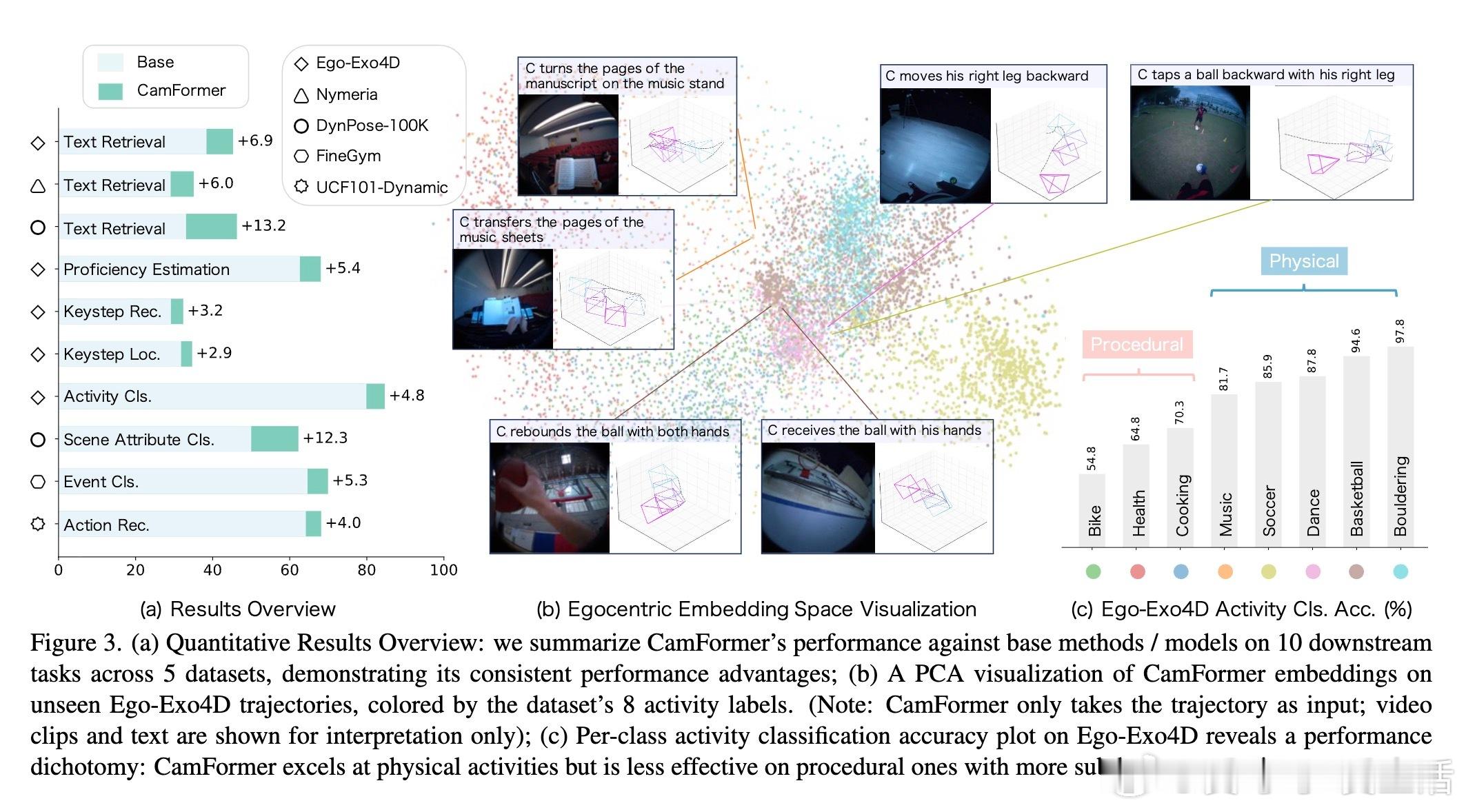
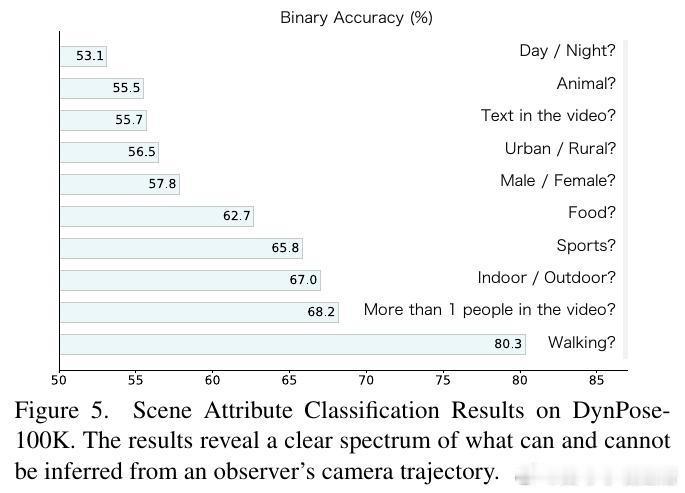
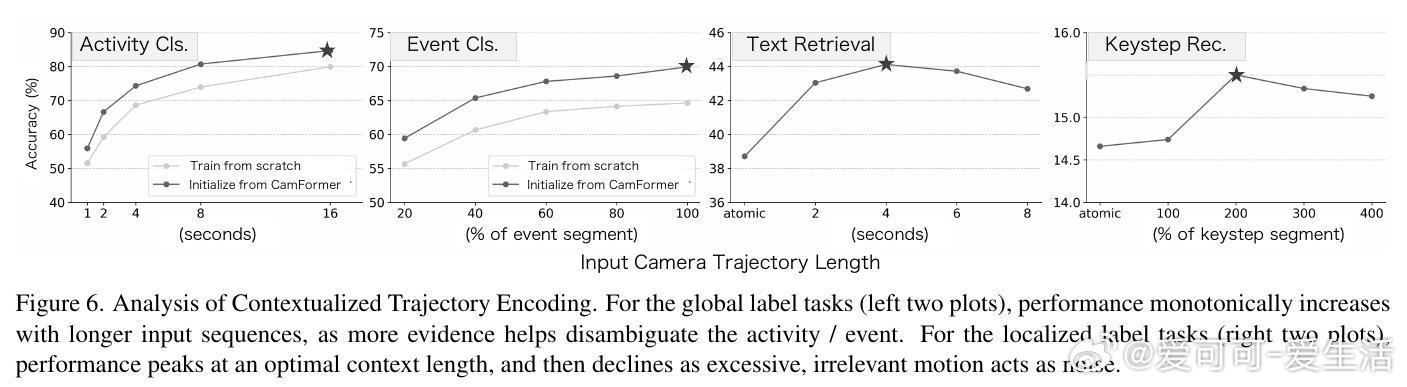
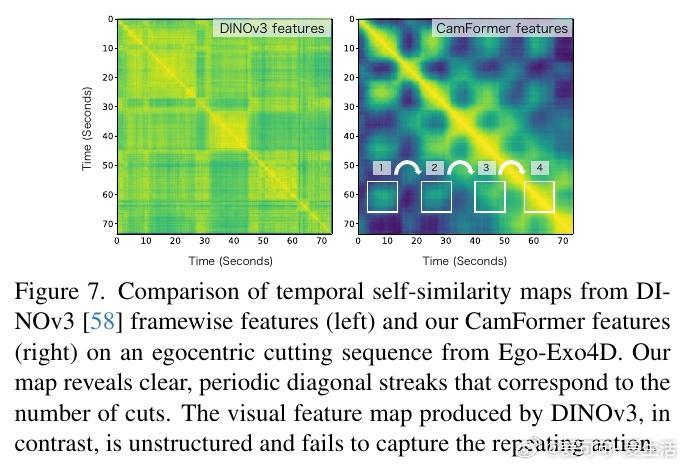
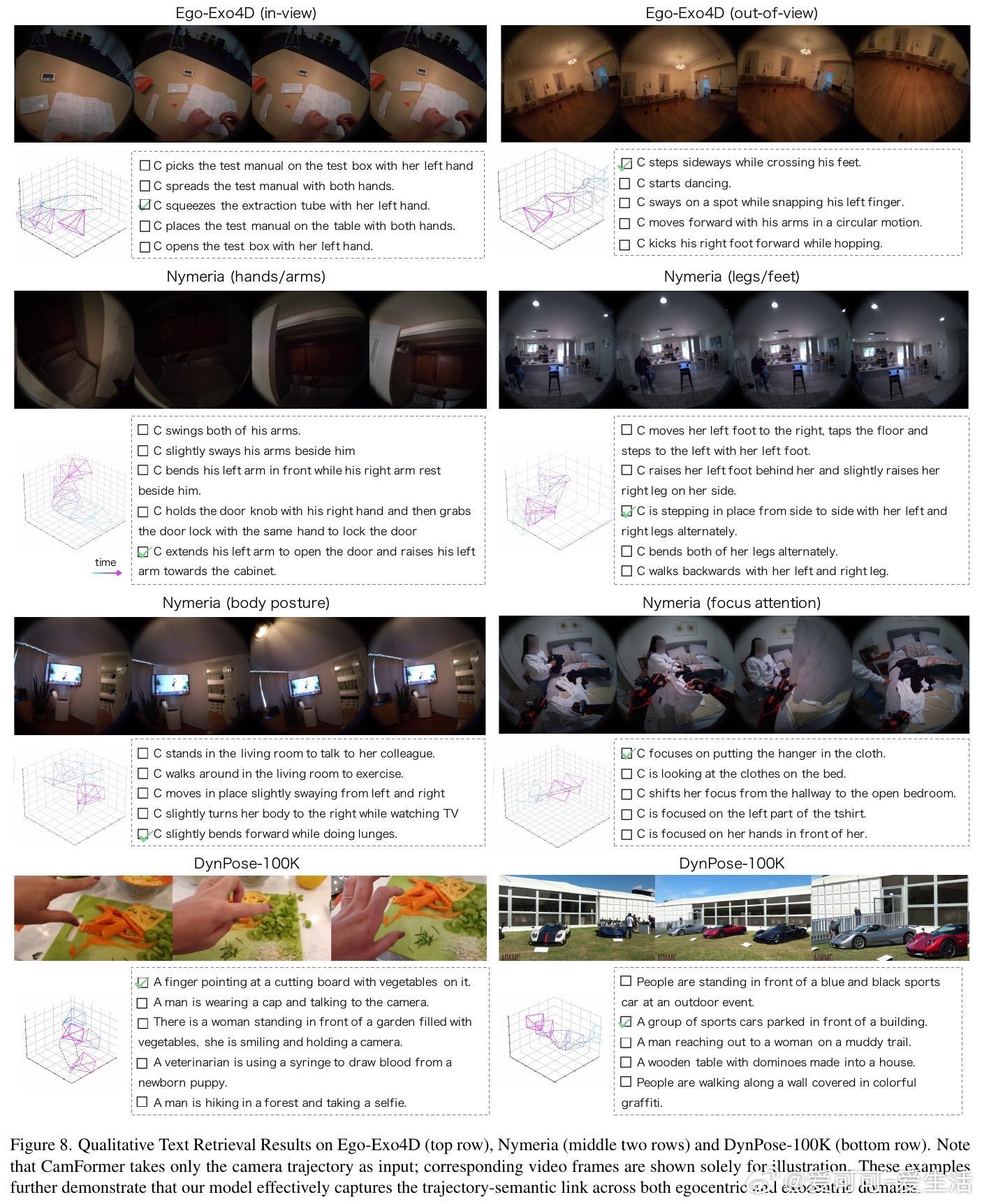
[CV]《Seeing without Pixels: Perception from Camera Trajectories》Z Xue, K Grauman, D Damen, A Zisserman... [Google DeepMind & The University of Texas at Austin] (2025) 有人能相信吗?仅凭摄像机的运动轨迹——没有看到任何像素内容——就能感知视频内容?本文开创性地提出了CamFormer,一种专门编码摄像机轨迹并与自然语言对齐的对比学习模型。事实证明,“你如何移动”,实际上能揭示“你在做什么”或“你在观察什么”。传统视频理解依赖视觉信息,但摄像机轨迹作为一种轻量、隐私友好的信号,从未被深挖其语义价值。CamFormer通过对摄像机的9维相对姿态序列进行Transformer编码,结合扩展的时间上下文,有效消解动作歧义,形成了强大的语义嵌入。在十项跨模式对齐、分类和时间分析任务中,CamFormer在自我视角(egocentric)和第三视角(exocentric)视频均表现出色,单独使用时甚至超越了计算量巨大的视觉模型。特别是在身体运动明显的活动(如篮球、攀岩)中,轨迹信号表现卓越;在程序性动作(如做饭、修车)中,轨迹与视觉互补,融合后效果最佳。更令人振奋的是,CamFormer对多种摄像机姿态估计方法均展现出强鲁棒性,从高精度多传感器SLAM数据到单目视频估计均适用,极大提升其实用价值。此外,它还能捕捉动作的周期性特征,实现重复动作计数,展现出对时间结构的敏锐感知。这项工作不仅开辟了视频理解的新范式,也呼吁社区重新审视摄像机轨迹的潜力。未来,随着姿态估计技术的进步和大规模轨迹数据积累,CamFormer有望在动作识别、技能评估、场景理解等领域发挥更大作用。更多细节、实验和可视化解析请见论文:arxiv.org/abs/2511.21681 项目主页:sites.google.com/view/seeing-without-pixels“眼睛不只是用来看,而是用来‘移动’的。”——摄像机轨迹,正是视觉意图的无声语言。