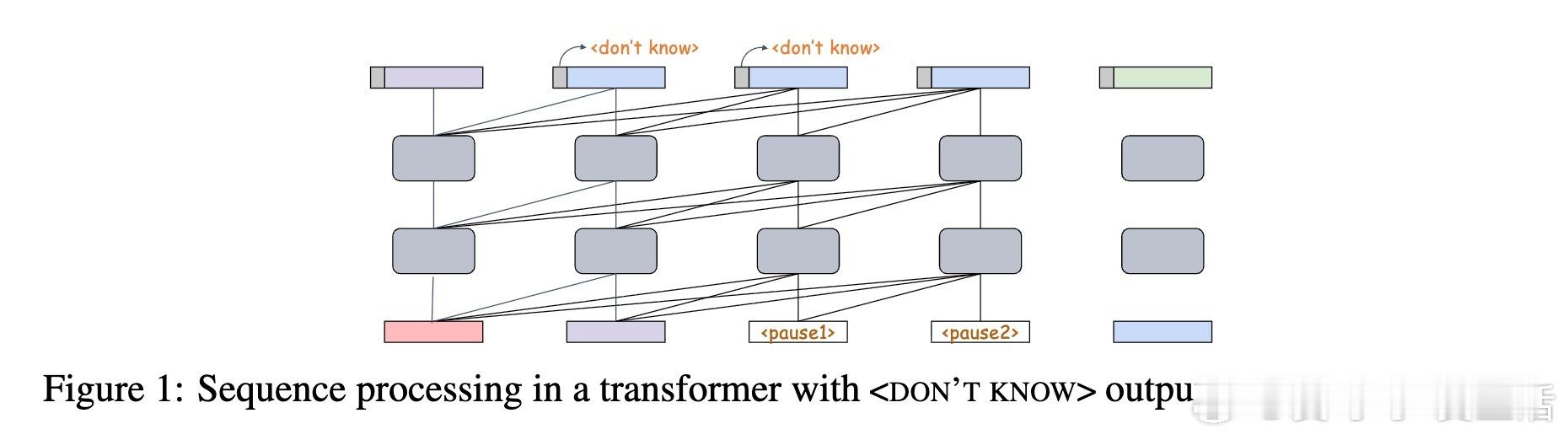
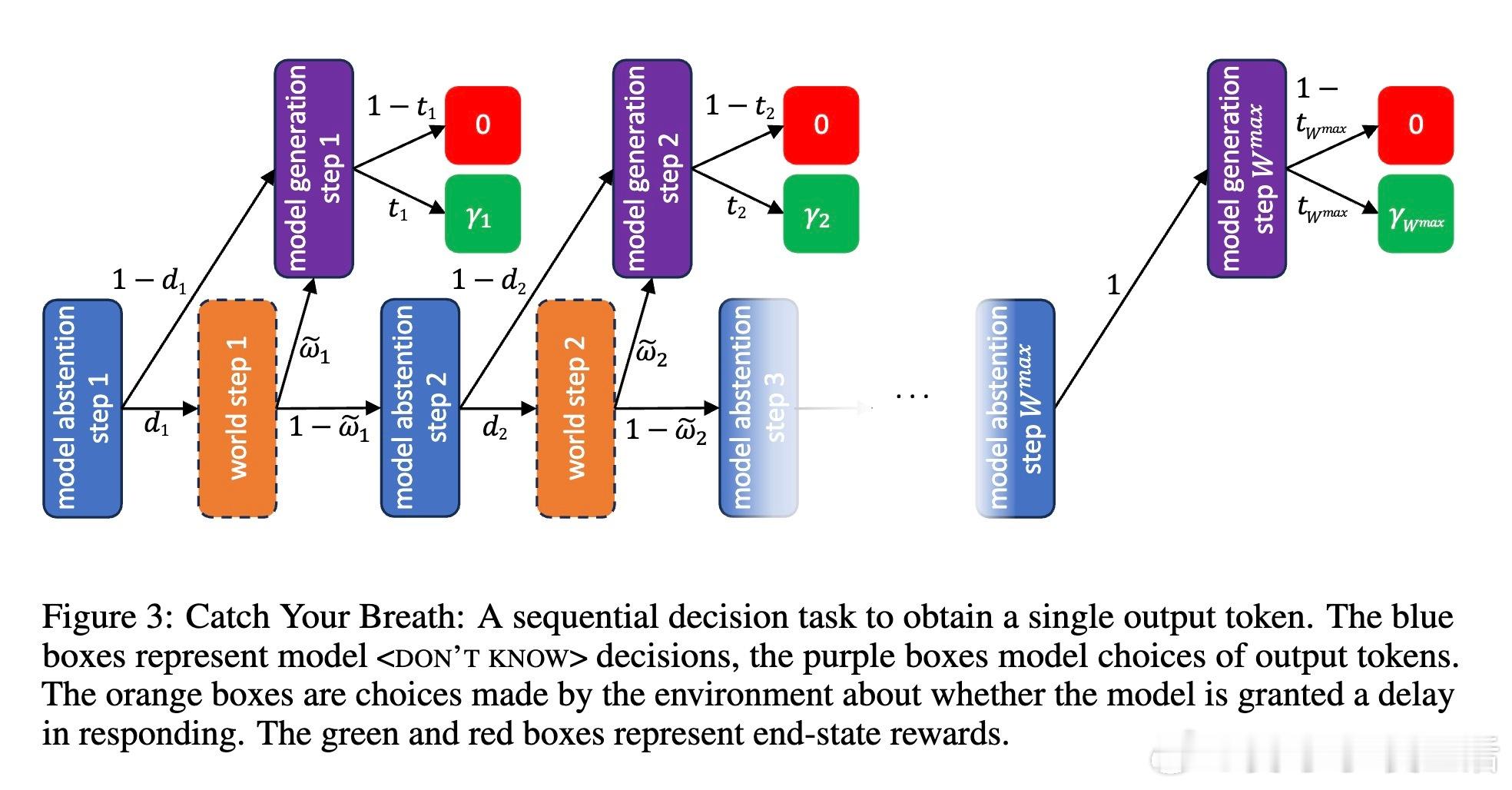
[CL]《Catch Your Breath: Adaptive Computation for Self-Paced Sequence Production》A Galashov, M Jones, R Ke, Y Cao... [Google DeepMind] (2025)
Catch Your Breath:自适应计算实现自节奏序列生成
近日,Google DeepMind团队提出了一种创新的训练方法——Catch Your Breath(CYB)损失,赋予语言模型根据输入Token动态调节计算步数的能力。模型可通过输出特殊的“”标记请求额外计算时间,插入“”Token延迟响应,从而提升预测的准确性与效率。
【核心理念】
- 模型将每个输出决策视为带有时间成本的顺序决策问题,实现速度与准确度的权衡。
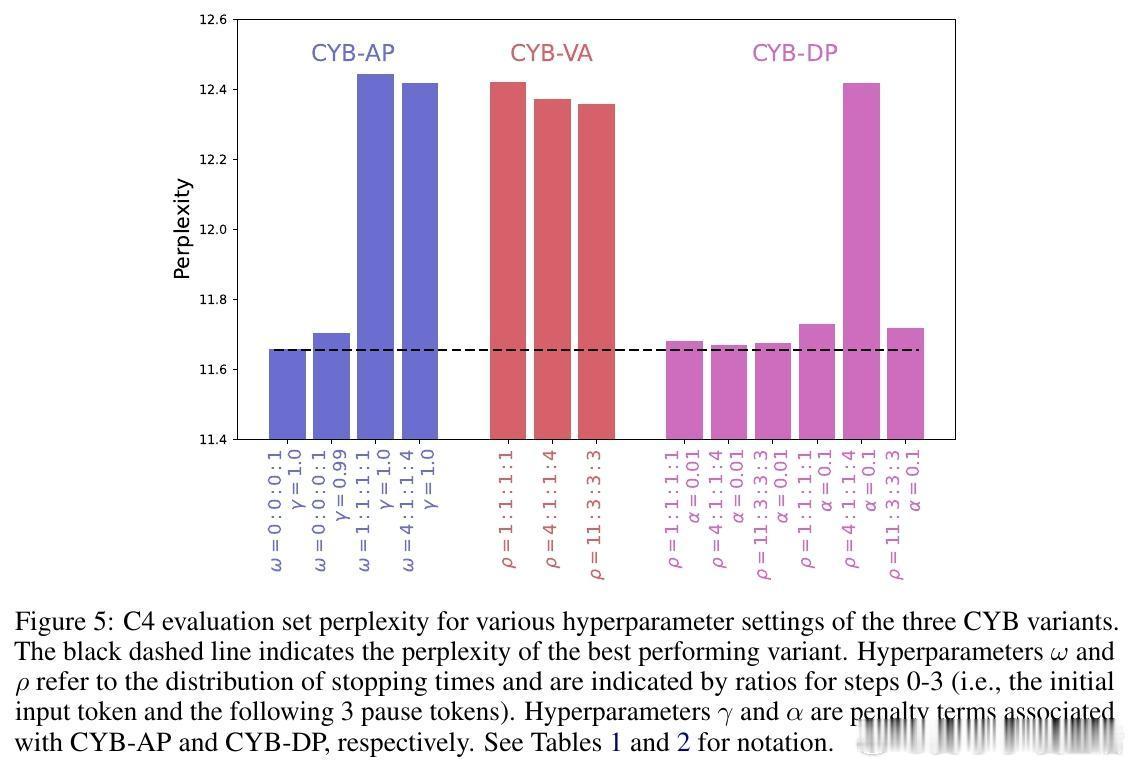
- 提出三种CYB变体:
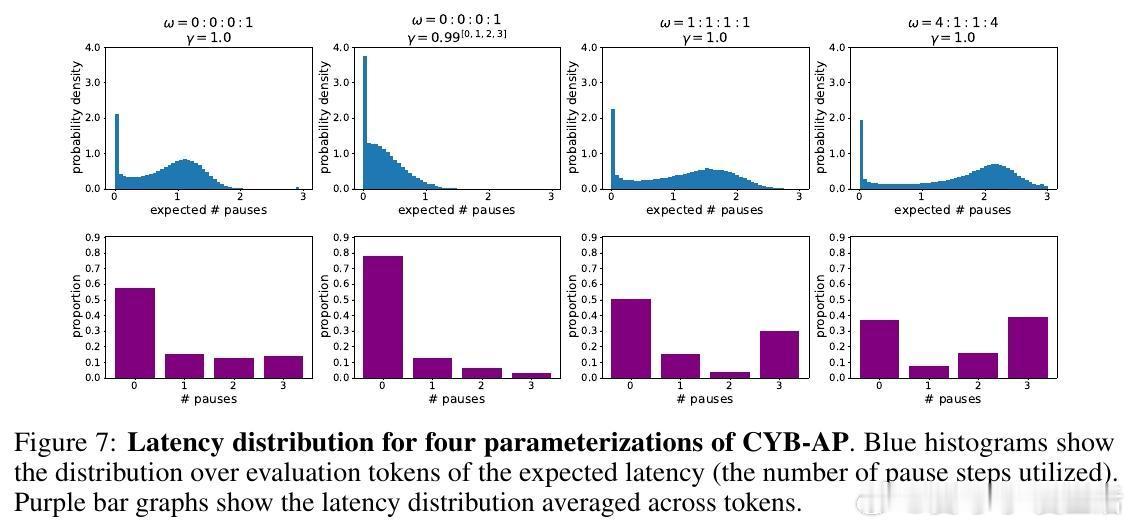
1. CYB-AP(Anytime Prediction):任何步骤均可输出结果,准确率随时间折扣。
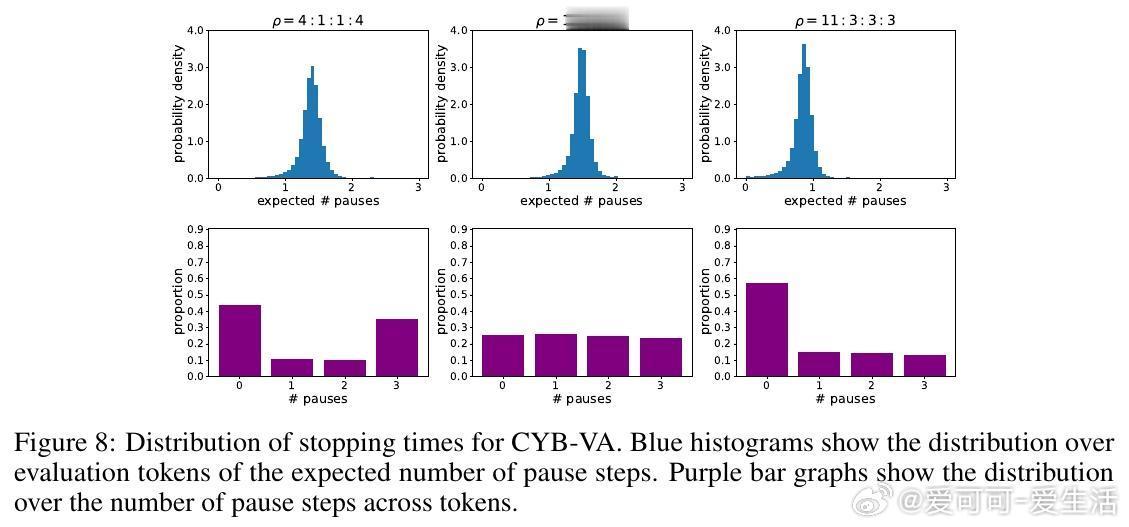
2. CYB-VA(Variational Approach):最大化准确率,满足预设停止时间分布。
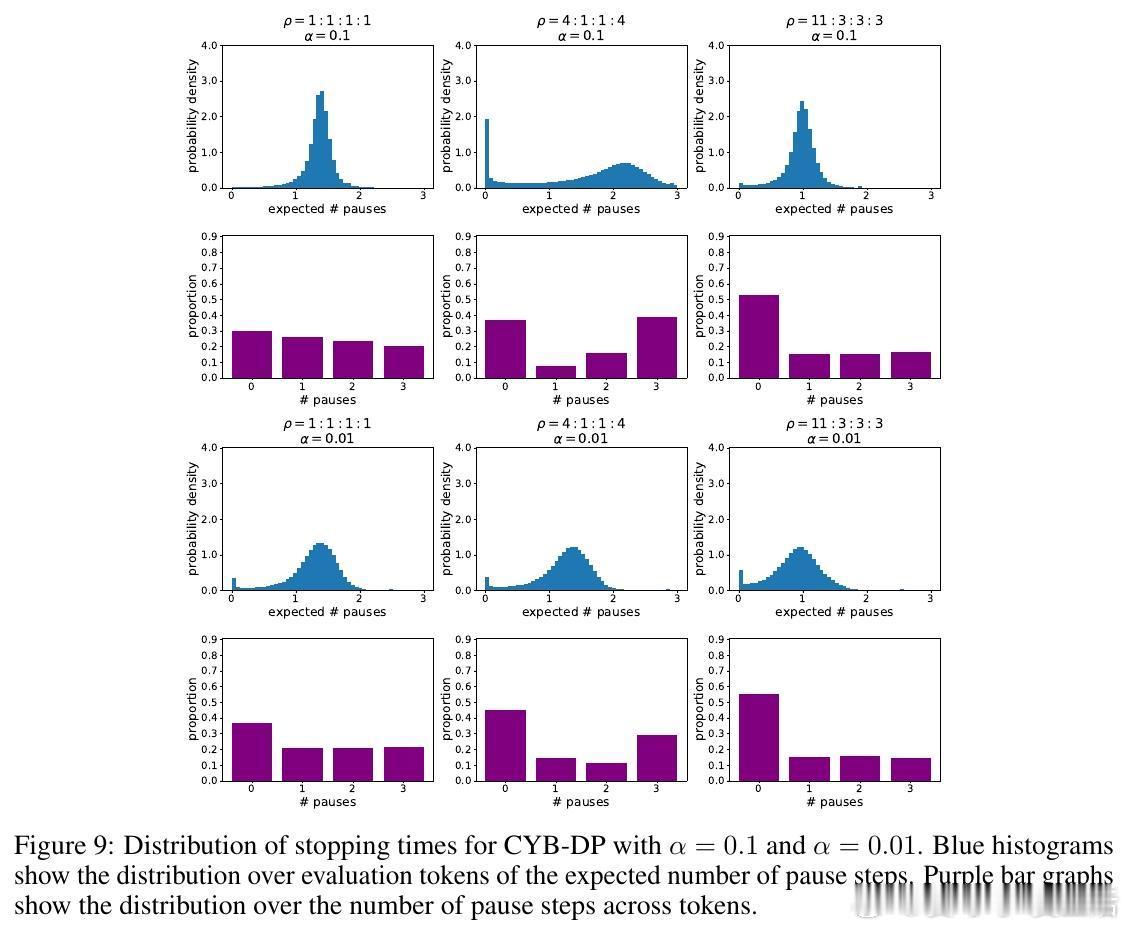
3. CYB-DP(Distributional Penalty):基于计算预算对停止时间分布施加惩罚。
【方法优势】
- 训练出的模型能针对不同Token的复杂度和上下文自适应调整计算步数,如对复数名词“patients”请求更多暂停,而对缩写“wasn”则快速响应。
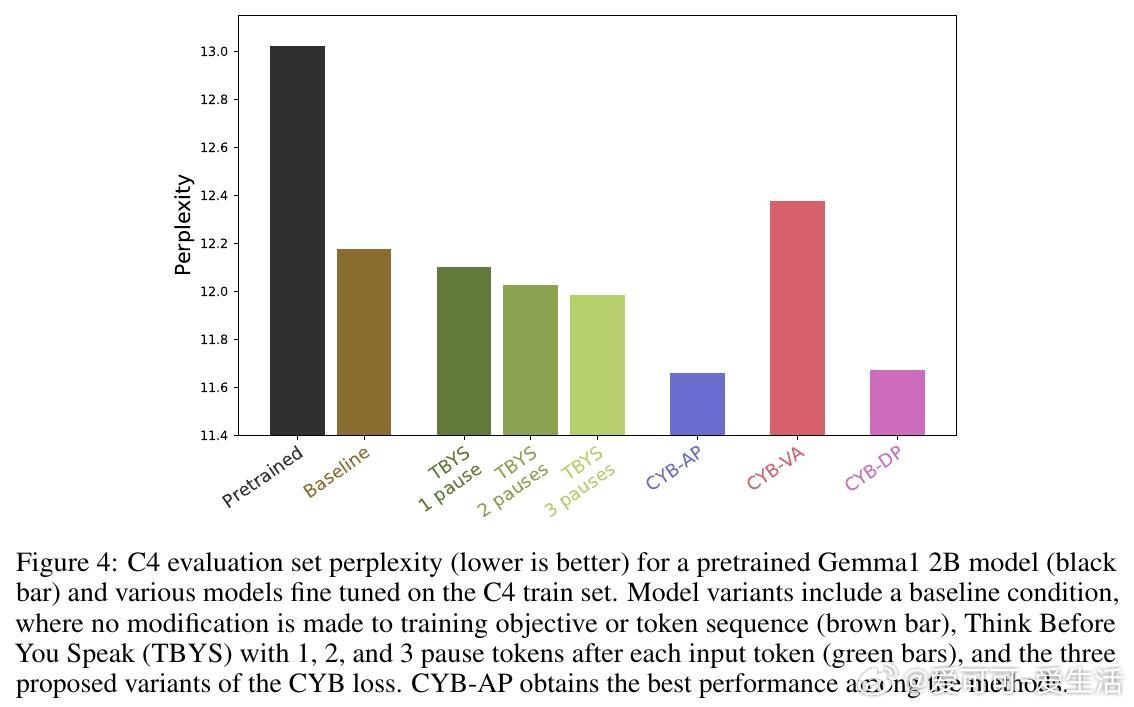
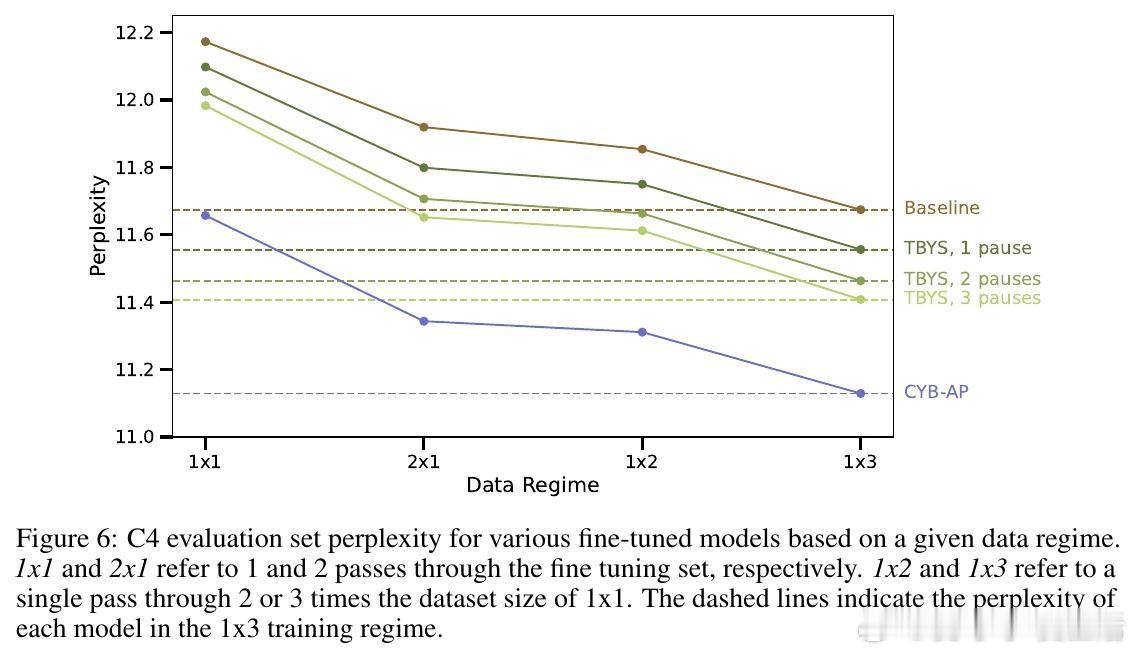
- CYB-AP表现优异,训练效率提升显著:基线模型需3倍数据量才能匹配其性能,且模型自动校准延迟概率以提升准确率。
- 通过在C4数据集上微调实验,CYB-AP与CYB-DP明显优于传统交叉熵损失及已有“Think Before You Speak”方法。
【实现细节】
- 利用RoPE位置编码,赋予每个“”Token与前一个非暂停Token相同的位置索引,保证输入序列位置稳定。
- 训练时固定在每个真实Token后插入固定数量的暂停Token,推理时亦保持一致,避免上下文窗口混乱。
- “”标记作为模型输出空间的一部分,通过调整模型后验概率鼓励合理使用。
【未来方向】
- 探索变动数量暂停Token的训练与推理策略,尤其适合后续基于强化学习的自适应推理。
- 研究模型如何利用“”Token进行多步推理,可能通过条件化注意力权重进一步增强计算效率。
- 深入分析模型对不同Token和语境的自适应计算行为,助力理解语言模型的内部推理机制。
【背景启发】
研究灵感源自人类阅读行为——阅读时视线停留时间随信息整合难度变化而变化,模型模拟这种“微推理”机制,实现对复杂信息的动态处理。
该工作将“自适应计算”与“非内容控制Token”创新结合,为提升大规模语言模型的效率与推理能力提供了新范式。
欲深入了解技术细节与实验结果,请访问论文全文:arxiv.org/abs/2510.13879
语言模型 自适应计算 深度学习 自然语言处理 AI研究