[LG]《Beyond Multi-Token Prediction: Pretraining LLMs with Future Summaries》D Mahajan, S Goyal, B Y Idrissi, M Pezeshki... [FAIR at Meta & CMU] (2025)
突破多标记预测,预训练大语言模型新思路——未来摘要预测(FSP)
当前大语言模型(LLMs)主流预训练目标是“下一标记预测”(NTP),即根据已有上下文预测下一个词。但NTP存在“教师强制”弊端:训练时总用真实历史,推理时却依赖模型自生输出,导致长期推理、规划和创新写作表现受限。为缓解这一问题,已有“多标记预测”(MTP)尝试预测多个后续词,但多为短期依赖,效果有限。
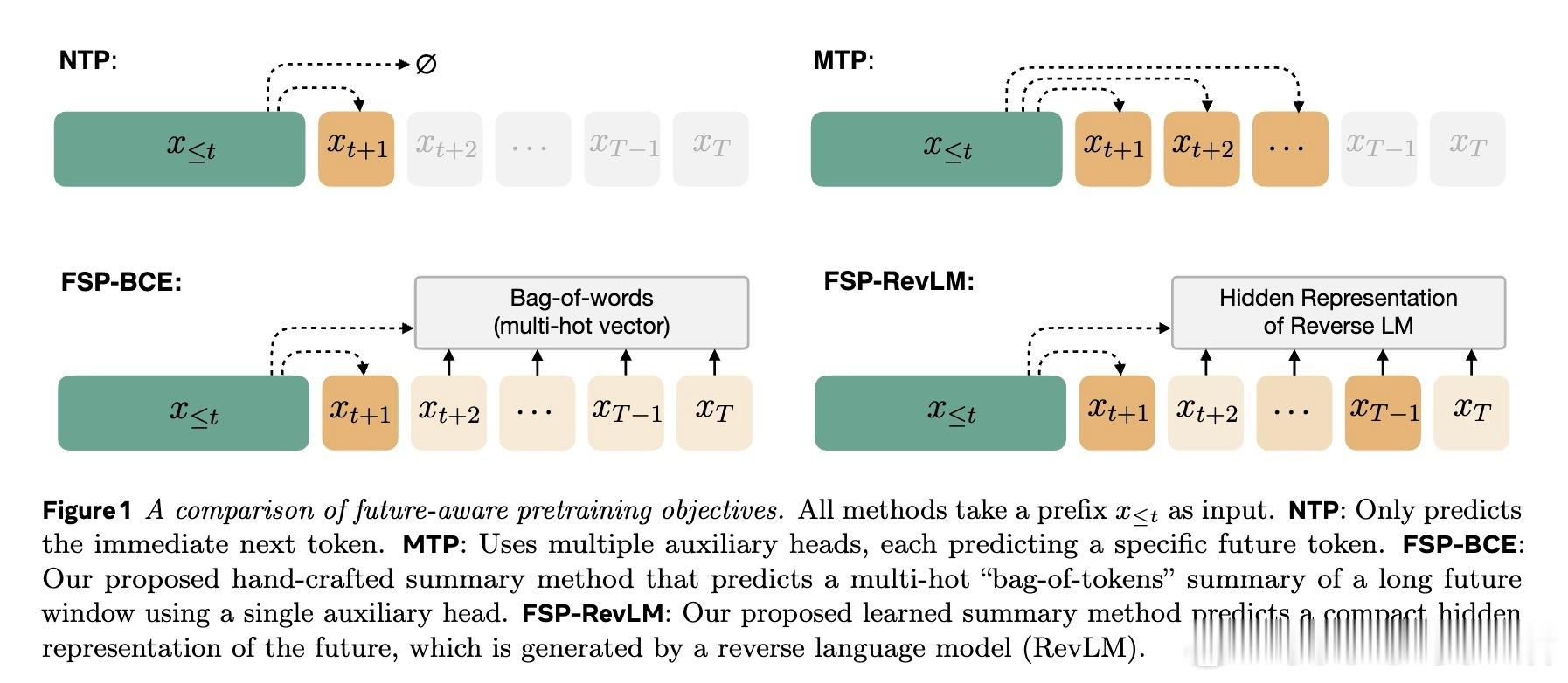
本文提出“未来摘要预测”(FSP),训练模型预测未来序列的紧凑摘要,而非单个词。具体有两种方式:
1. 手工设计未来摘要——类似未来词汇的“词袋”多热向量;
2. 学习型未来摘要——通过逆向语言模型(RevLM)生成未来序列的隐藏表示作为摘要。
实验证明,FSP不仅克服了NTP和MTP的短板,还在数学、推理和代码生成等长远任务上带来显著提升,尤其是规模达8B参数的大模型。
核心亮点:
- 长期未来摘要有助于模型学习全局规划,避免NTP常见的“捷径学习”和梯度匮乏问题。
- 学习型摘要能自适应过滤未来信息中的噪声,针对复杂任务表现更佳。
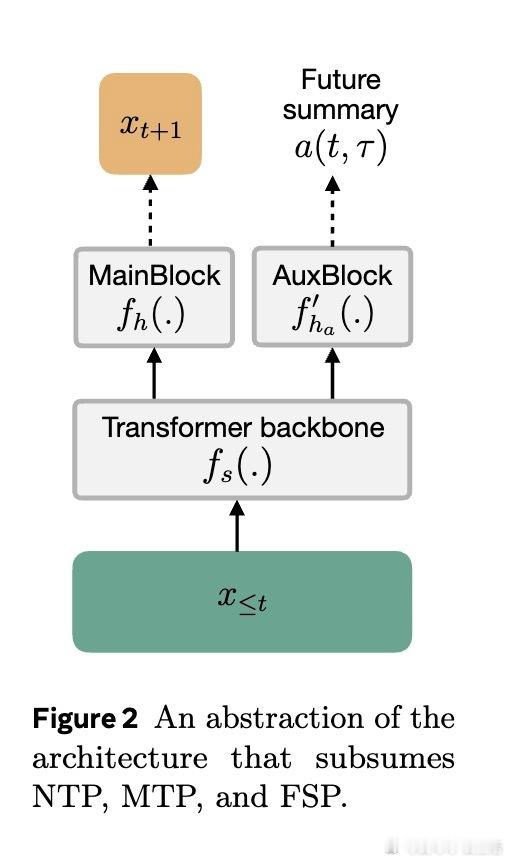
- FSP只需一个辅助预测头,具备更好扩展性和训练效率。
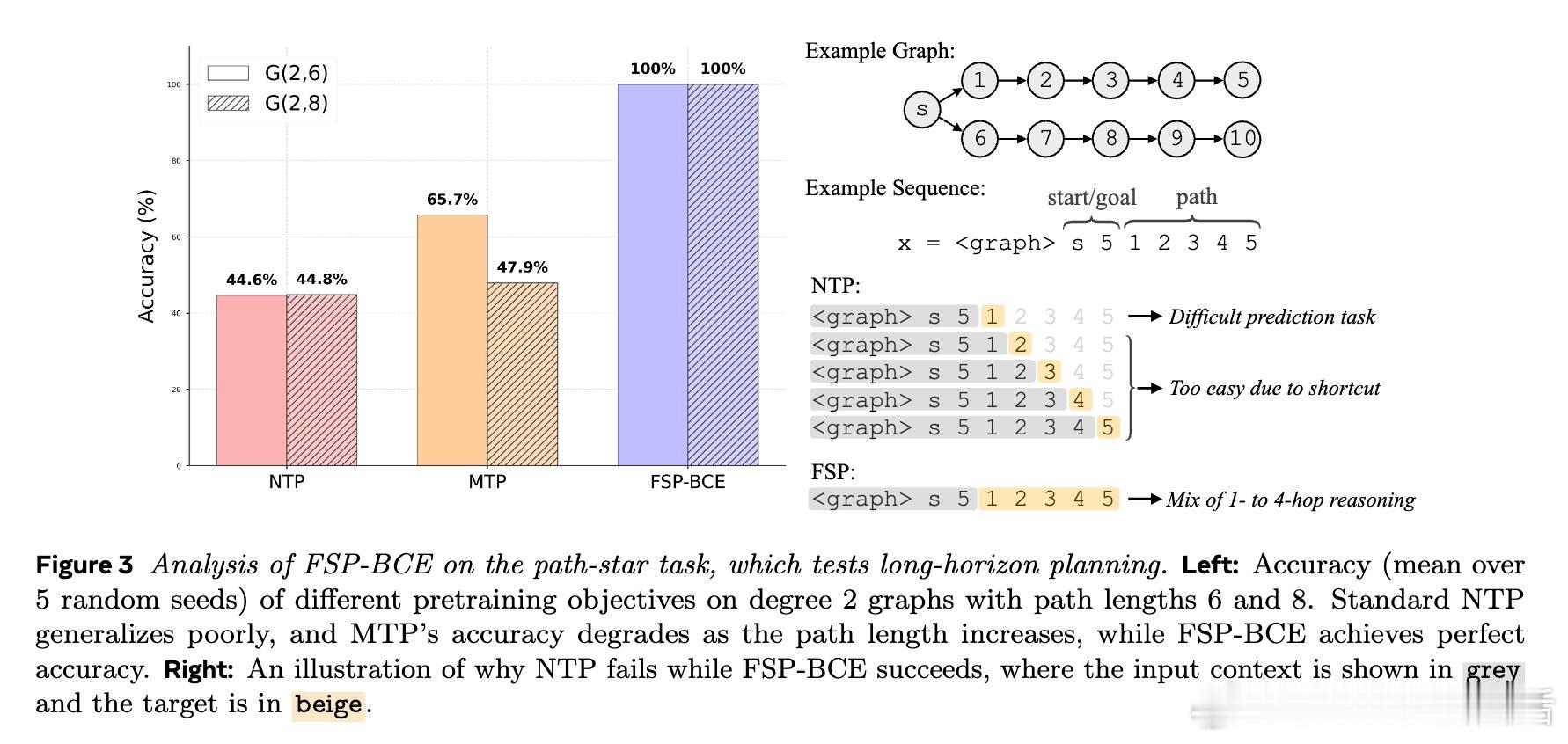
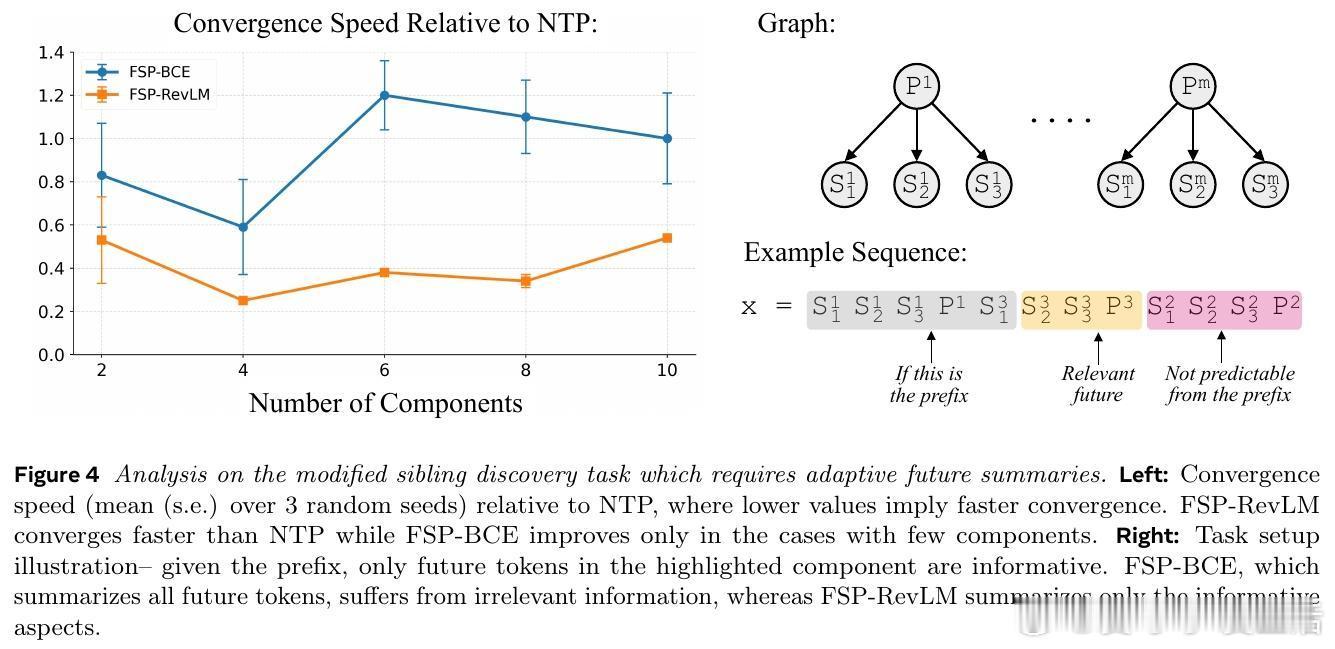
- 通过路径-星形图和兄弟节点发现等合成任务,验证了FSP在长距离依赖和复杂结构推理上的优势。
- 大规模真实预训练下,FSP明显优于传统NTP和MTP,数学推理任务提升达4%以上。
背景提示:
NTP训练时使用“教师强制”带来的训练推理不匹配(exposure bias)限制了模型的长远生成能力。MTP虽部分缓解,但受限于预测长度和辅助头数量。FSP通过预测未来的抽象摘要,提供了对未来更全局、紧凑的监督信号,激励模型学习深层次的长期依赖。
实验细节:
- 3B及8B参数模型分别在250B和1T词语语料上训练,涵盖数学、编程、大规模文本等多领域。
- 评测涵盖ARC、GSM8K、MATH、MBPP、HumanEval+等多个推理及代码生成基准。
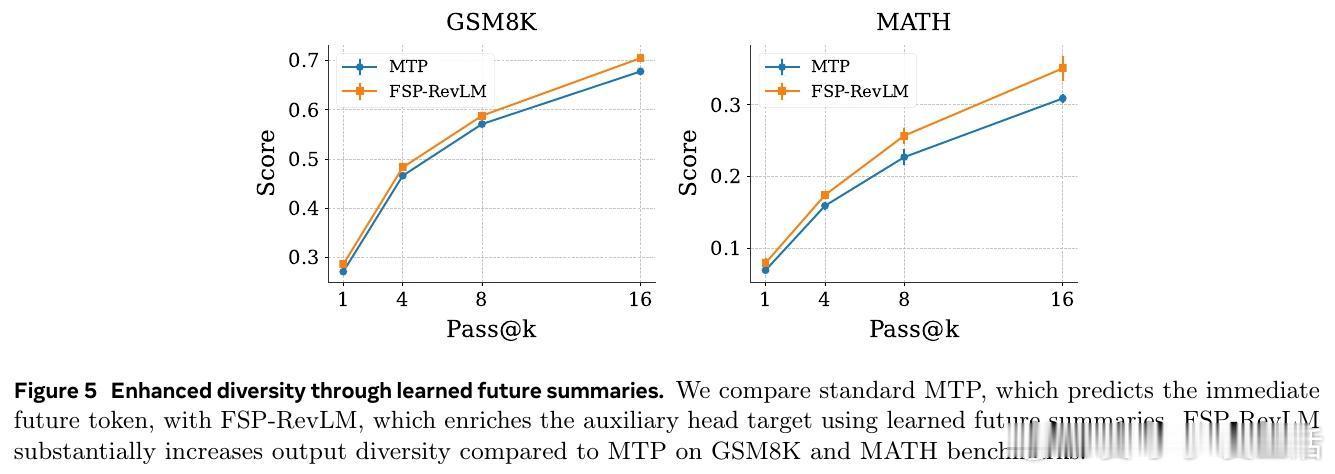
- FSP-RevLM在8B模型上多项任务得分超越NTP和MTP,尤其在ARC-Easy(76.6%)、MATH(35.1%)等长程推理任务中领先。
- FSP-BCE(手工摘要)在路径-星形图任务中表现完美,显示长期未来信息的重要性。
- 兄弟节点发现任务中,FSP-RevLM因学习型摘要的自适应能力,收敛更快且表现更稳健。
结论:
未来摘要预测为LLM预训练带来全新视角,以预测未来的抽象信息替代传统词级预测,显著提升模型对长期依赖的捕获能力和泛化性能。此方法为下一代大语言模型设计更高效、更具表现力的预训练目标指明了方向。
原文链接:arxiv.org/abs/2510.14751
大语言模型 预训练 未来摘要预测 FSP 多标记预测 NLP 机器学习