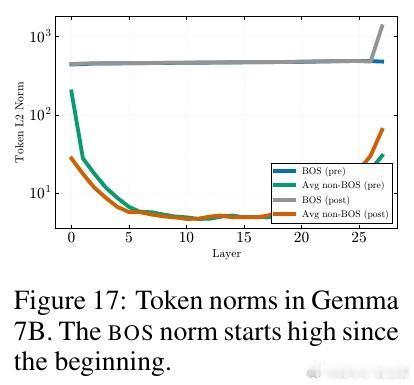
[LG]《Attention Sinks and Compression Valleys in LLMs are Two Sides of the Same Coin》E Queipo-de-Llano, Á Arroyo, F Barbero, X Dong... [University of Oxford] (2025)
深入研究了大型语言模型(LLM)中两个看似独立但实则紧密相关的现象——“Attention Sinks”(注意力汇聚)与“Compression Valleys”(压缩谷),并提出了全新的统一理论!
🔍 研究亮点:
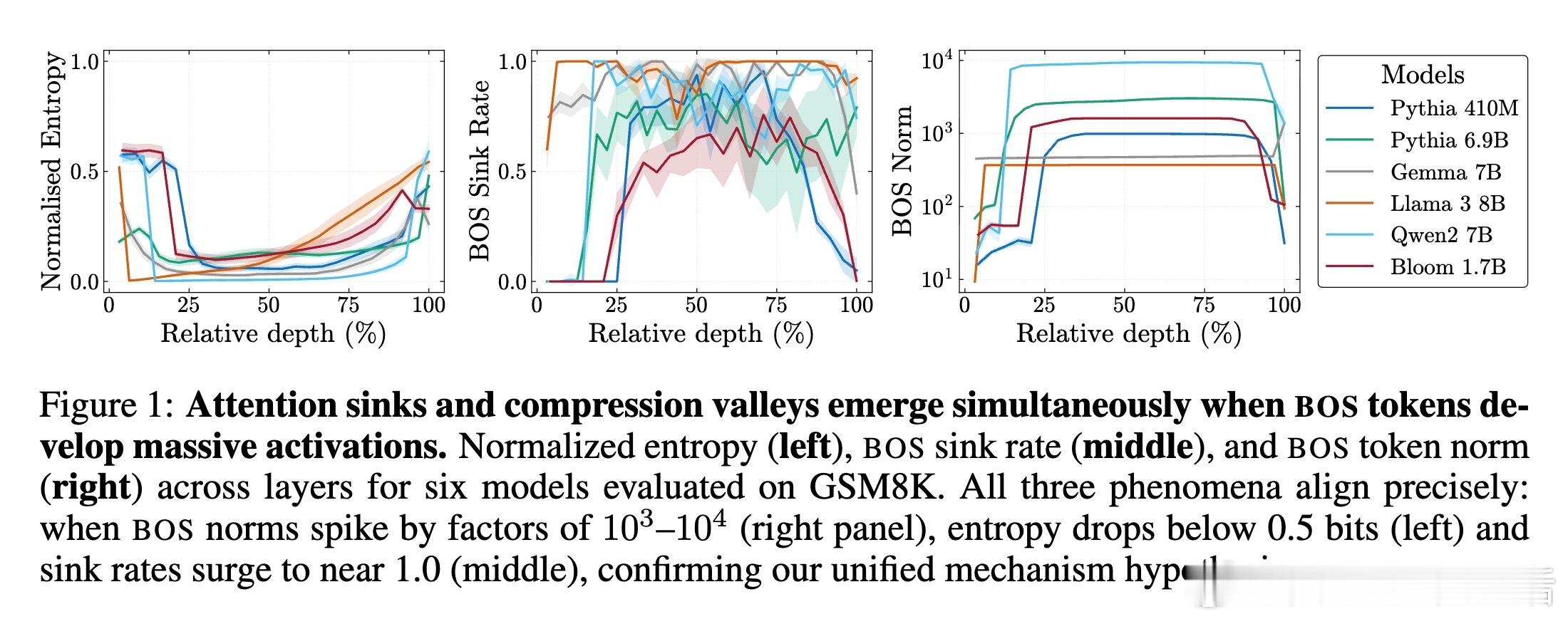
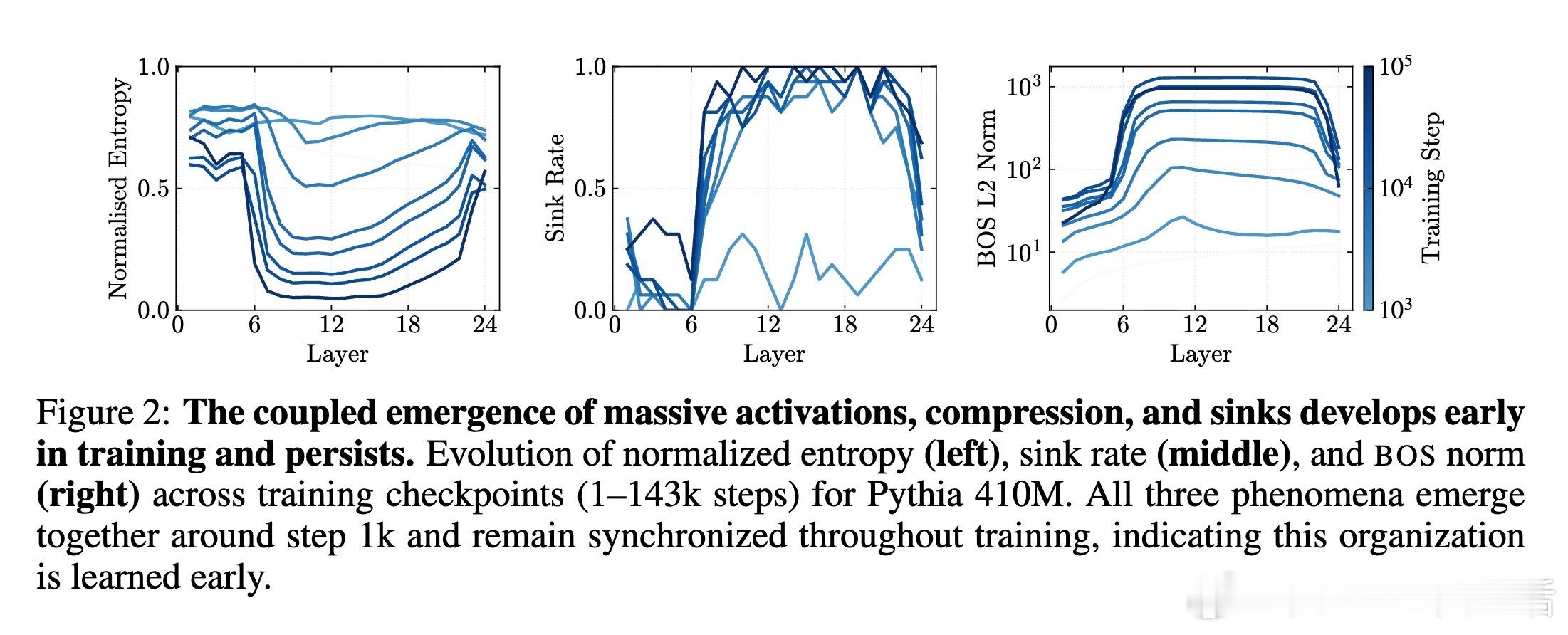
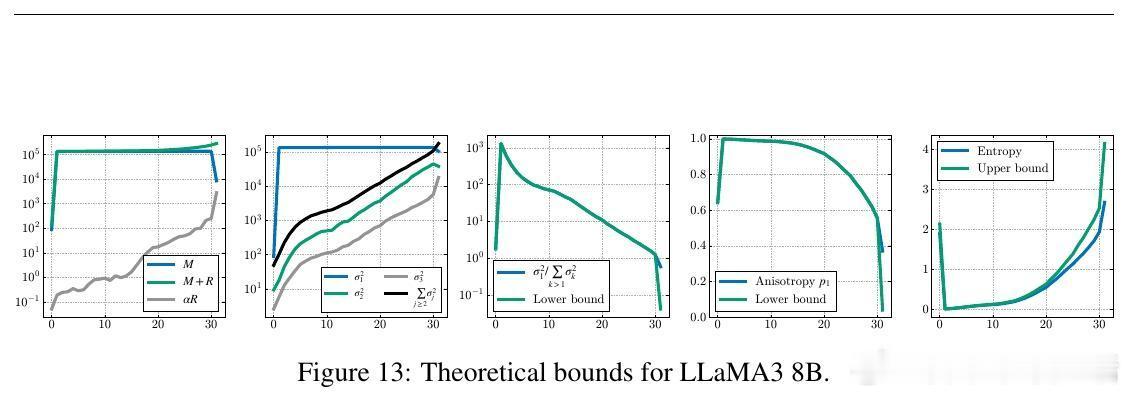
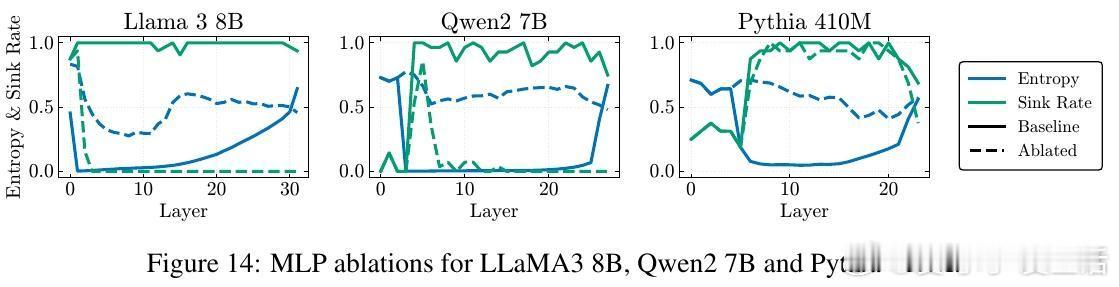
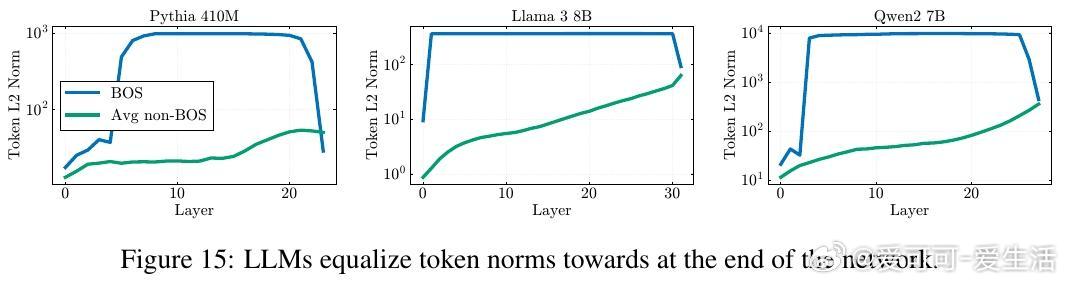
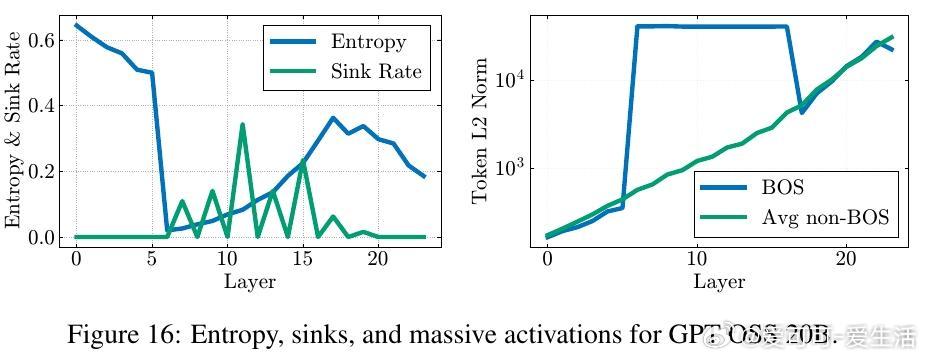
1️⃣ 统一机制发现——这两个现象均源自残差流中的“Massive Activations”(大规模激活),尤其是在序列起始符(bos token)上激活值极大,导致表示压缩和注意力汇聚同时出现。
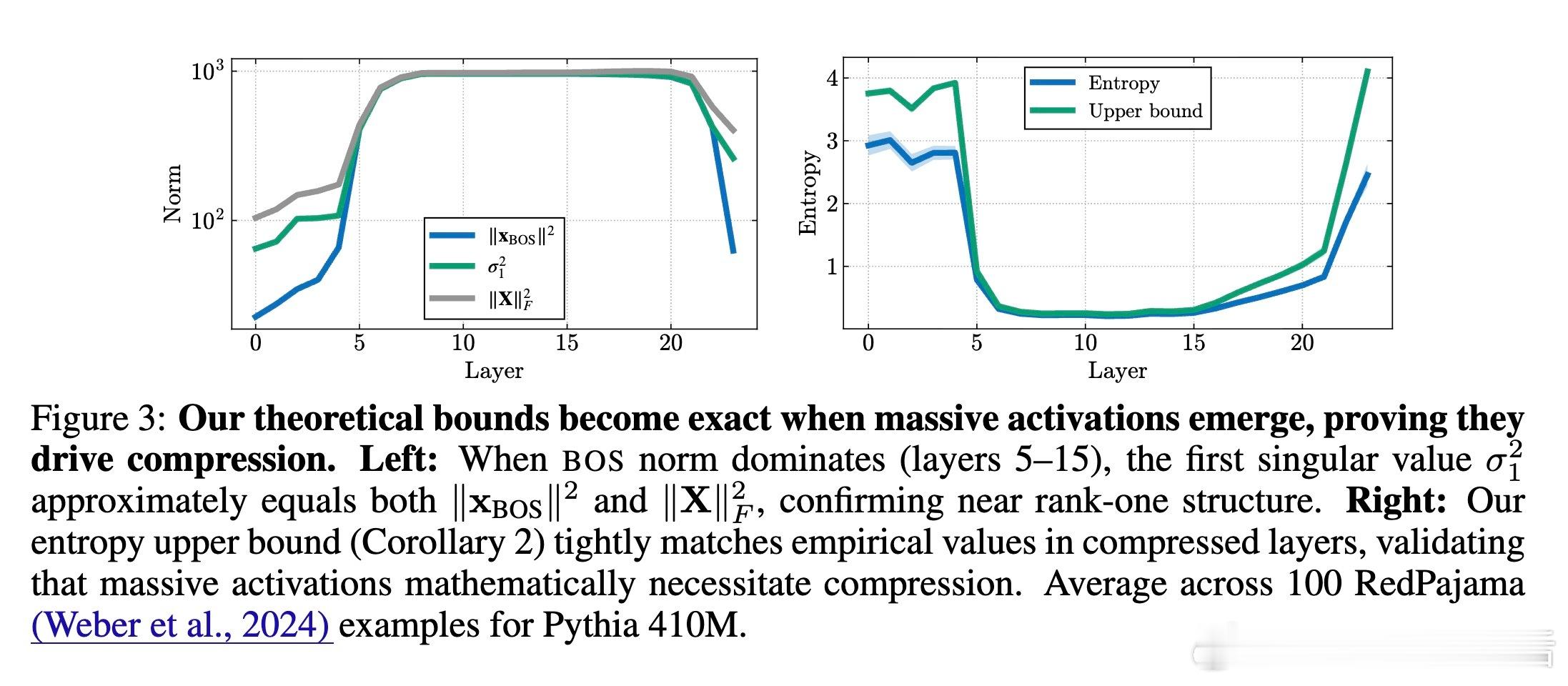
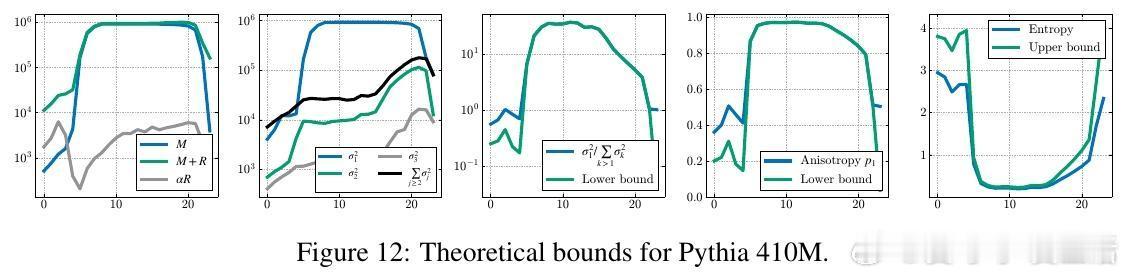
2️⃣ 理论证明——证明了大规模激活必然引起表示压缩(主奇异值占优),并给出了熵降低的数学界限。
3️⃣ 三阶段信息流理论(Mix-Compress-Refine):
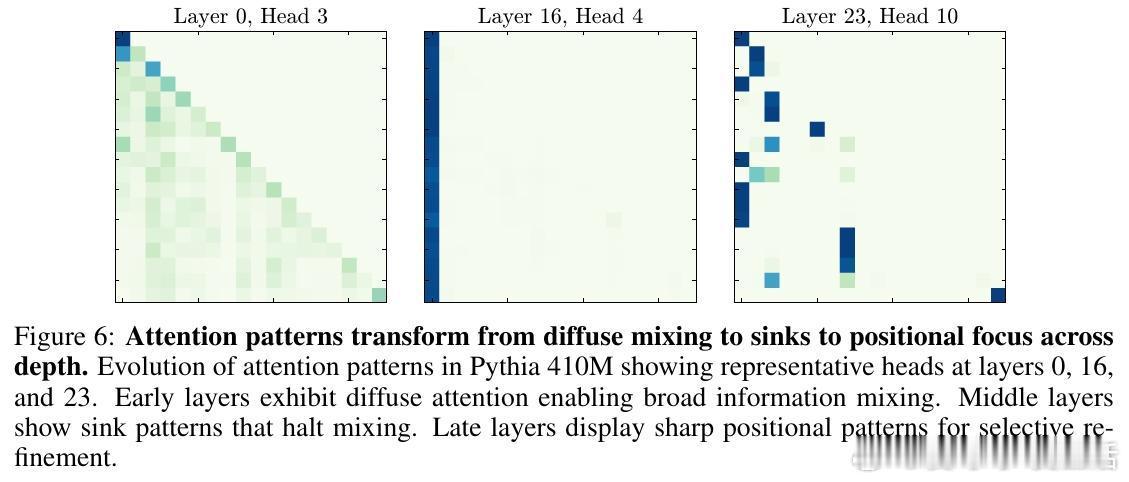
- 早期(0-20%层数):广泛混合信息,构建上下文语义。
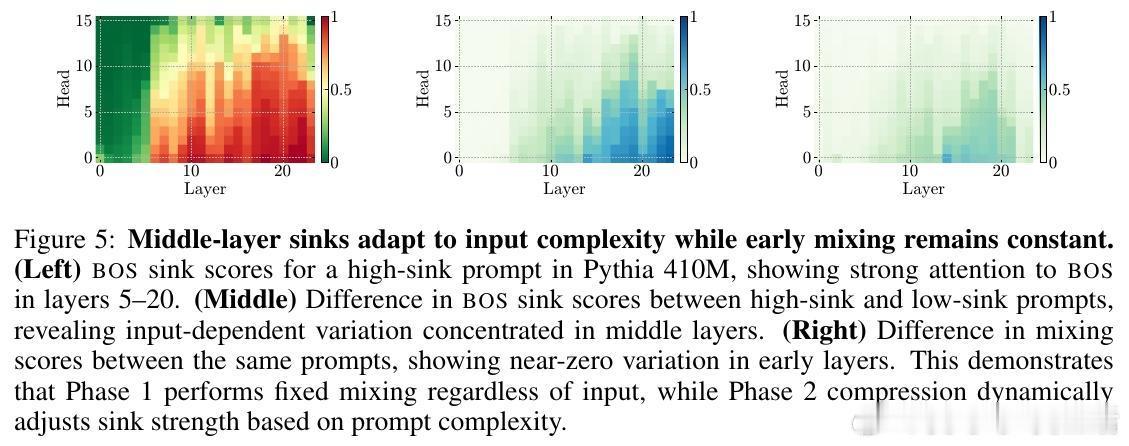
- 中期(20-85%):激活大规模激活引发压缩,注意力汇聚限制无效混合,防止过度混合。
- 后期(85-100%):范数均衡,注意力转向局部精准关注,实现选择性细化。
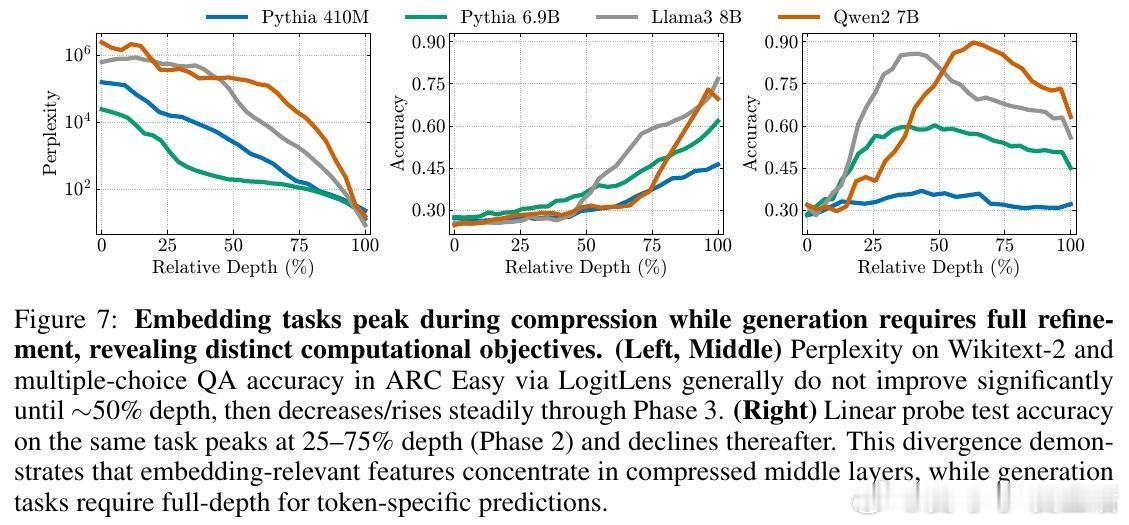
4️⃣ 任务依赖表现解释——嵌入任务(如分类、检索)在中期压缩层表现最佳,生成任务(文本生成、推理)则需完整深度细化阶段。
📊 实证验证:
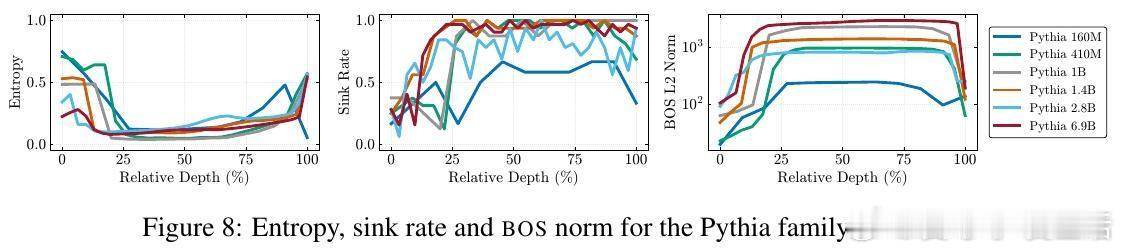
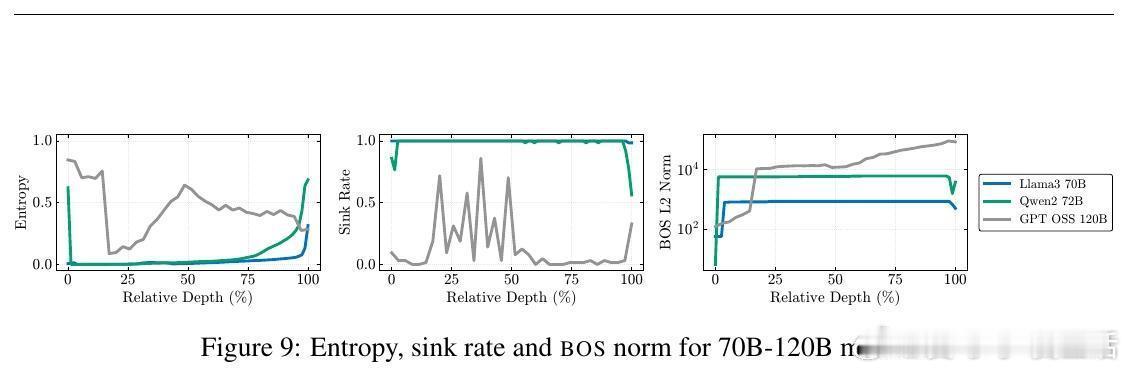
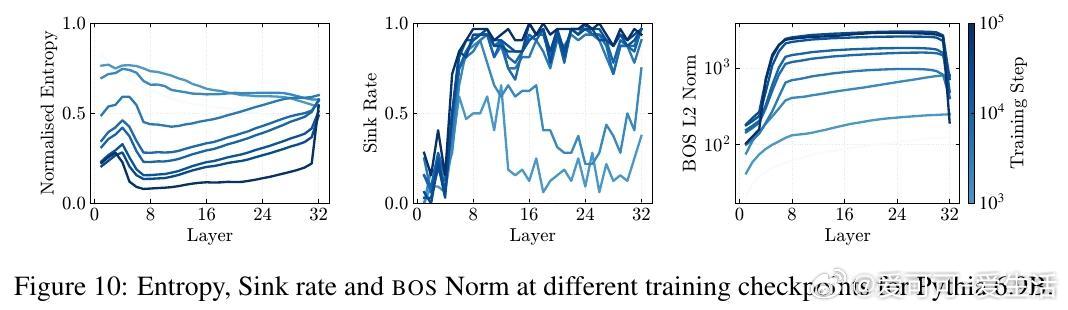
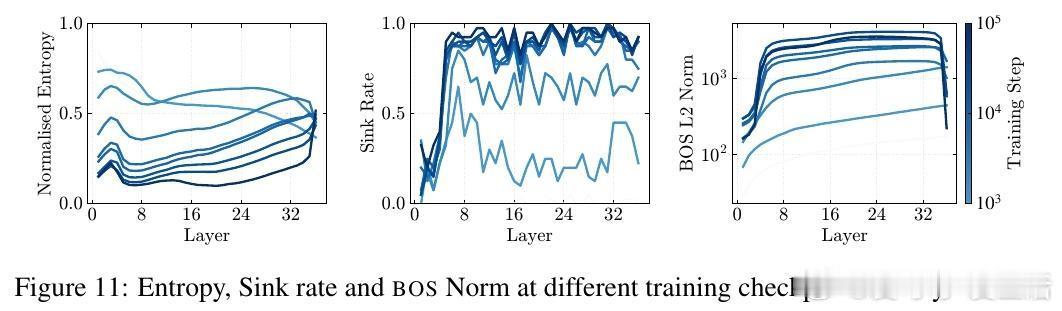
- 410M至120B参数规模多模型实测,注意力汇聚、压缩谷和大规模激活同步出现。
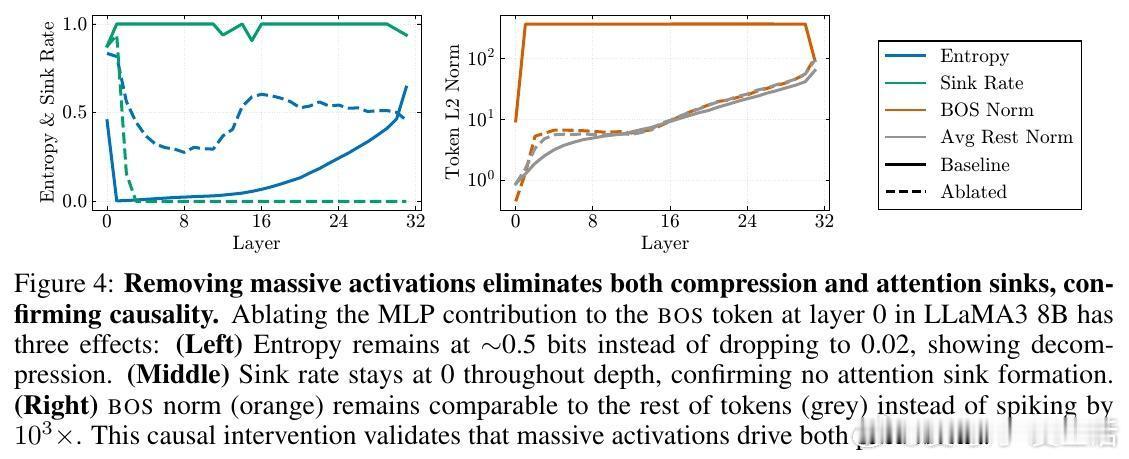
- 通过针对性MLP层消融,消除大规模激活即解除压缩和汇聚,验证因果关系。
- 细致分析多任务表现,揭示为何不同任务“最优层”差异根源于模型深度计算阶段分工。
💡 意义与展望:
这项工作首次将LLMs深度层间的注意力机制与表示几何结构统一起来,提供了更机械化的深度计算理解框架,助力未来设计更高效、可控的语言模型。
——
详细阅读原文请戳:arxiv.org/abs/2510.06477
大规模激活 注意力汇聚 表示压缩 LLM内部机制 Transformer 深度学习 人工智能 自然语言处理