高质量长篇博文:《深入 vLLM:高吞吐 LLM 推理系统解剖》Inside vLLM: Anatomy of a High-Throughput LLM Inference System
地址: www.aleksagordic.com/blog/vllm
作者Aleksa Gordić 曾是DeepMind 和微软的研究工程师,还有个不知道啥意思的中文id: (水平问题)。
作者的推荐语:
“这可能是最详尽的一次对 LLM 推理引擎,尤其是 vLLM 工作机理的拆解!为了把代码读透并写成文章,我花了很长时间,也深深低估了工作量 😅,写出来才发现完全可以扩成一本小书。
文章覆盖:
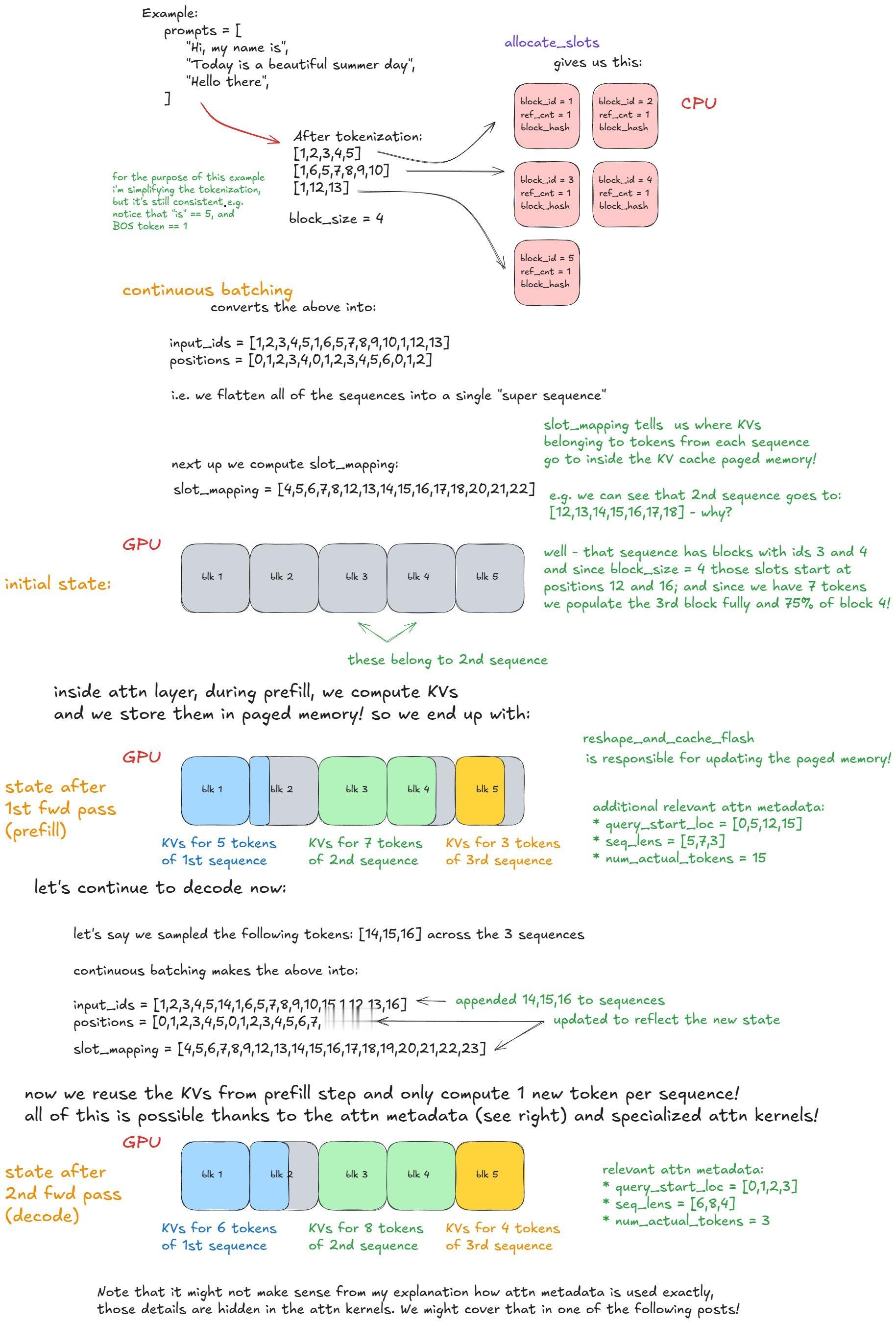
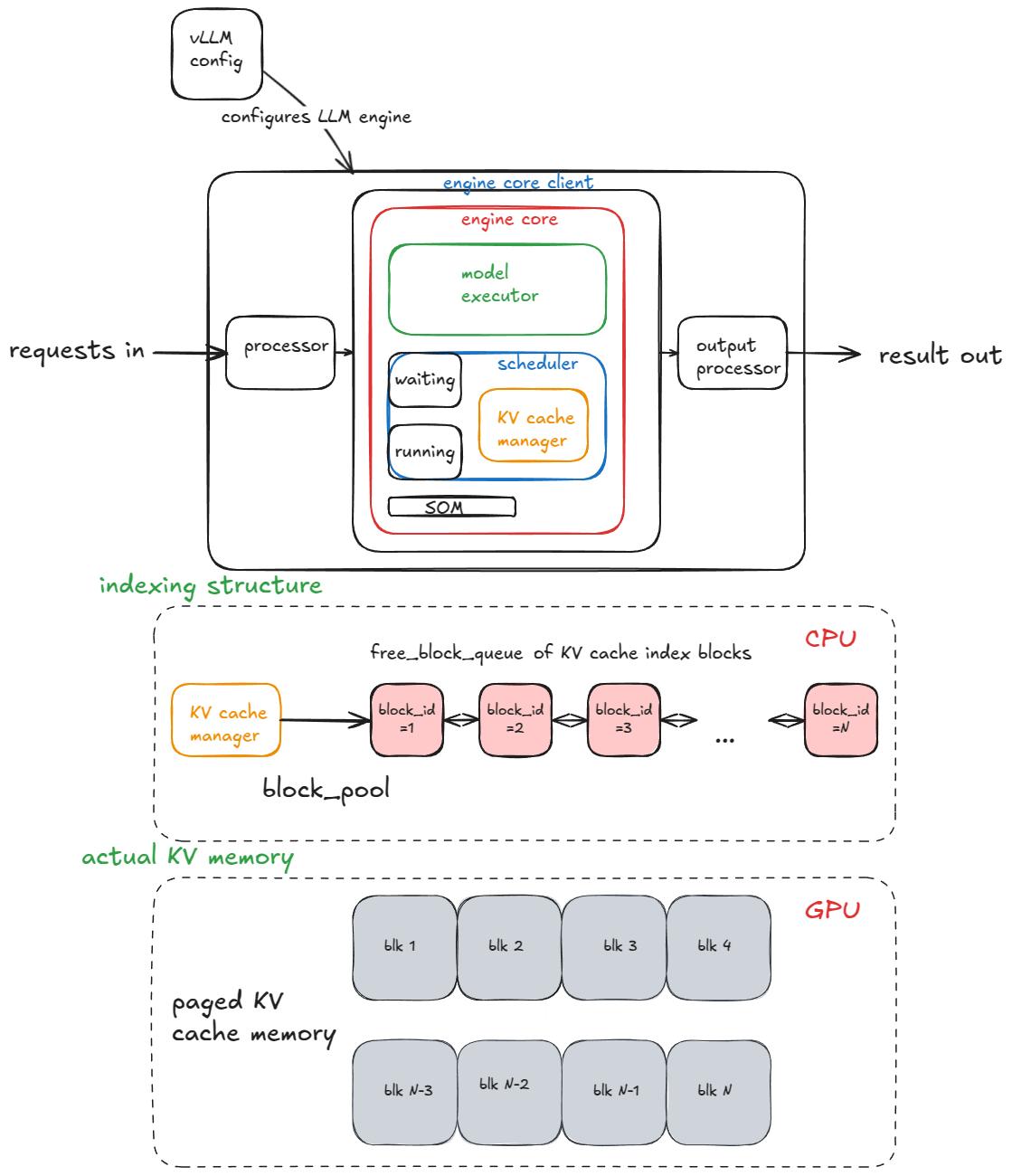
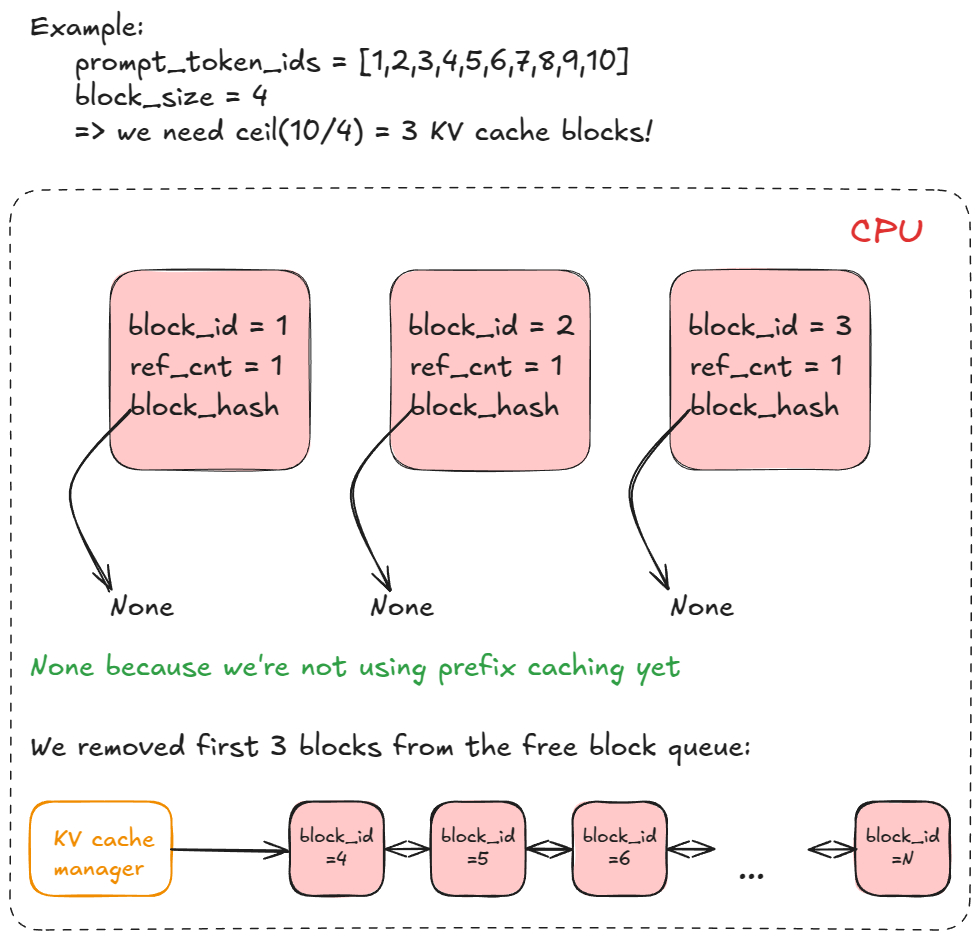
⭐推理引擎基础流程:输入/输出请求处理、调度、分页注意力、连续批处理
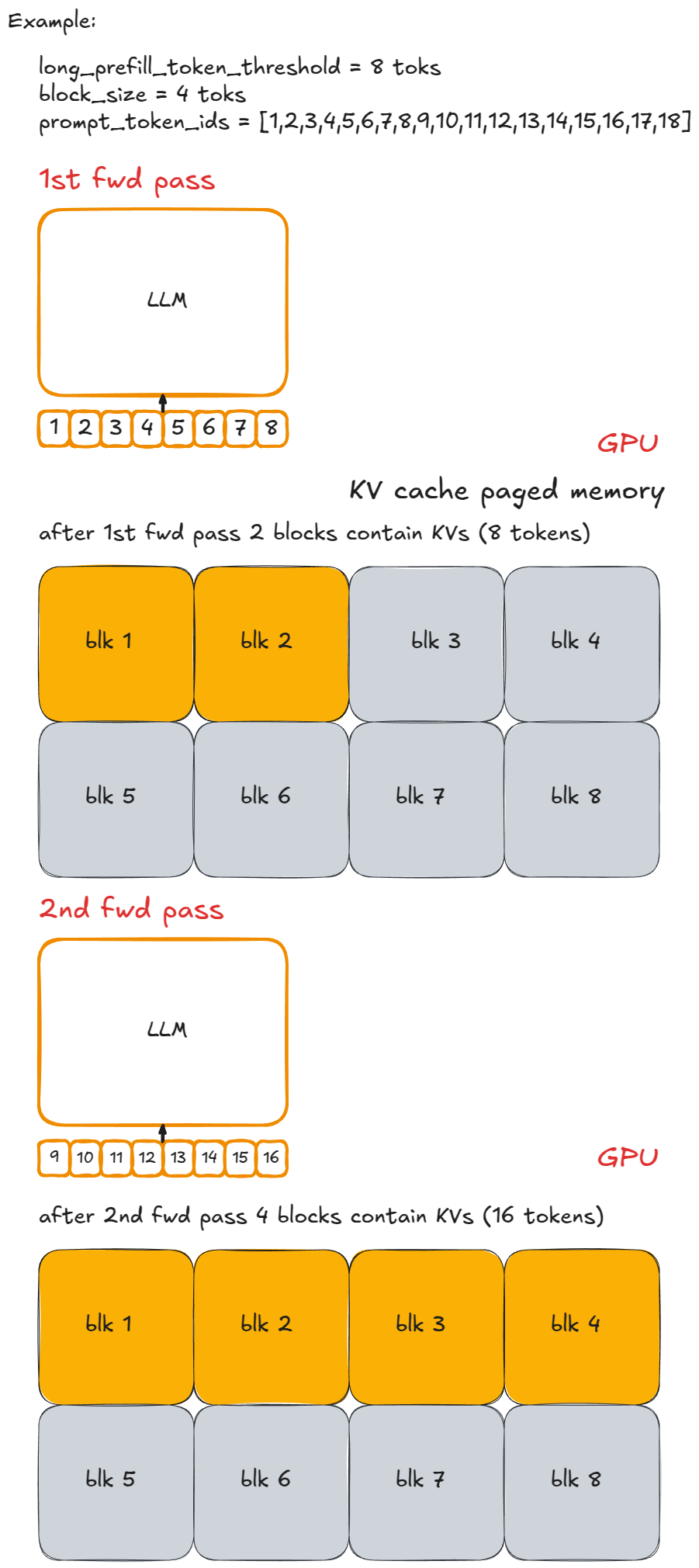
⭐“进阶”内容:分块预填充、前缀缓存、受约束语法 FSM 的引导解码、投机解码、解耦式预填充/解码
⭐规模扩展:从单 GPU 就能跑的小模型,到用 TP/PP/SP 跨多 GPU、多节点支撑万亿级参数模型
⭐Web 服务化:从离线部署到多 API server、负载均衡、DP 协调器、多引擎联合作战
⭐性能度量:延迟(TTFT、ITL、E2E、TPOT)、吞吐,以及 GPU 性能屋顶线模型
大量示例、大量可视化!”
AI生活指南